
Statistical hypothesis testing is guided by statistical analysis. The reliability of statistical significance is calculated using the p-value, which indicates the likelihood of the observed result assuming a specific hypothesis (the null hypothesis) is true. If the p-value is smaller than the significance level (usually 0.05), the experimenter can conclude that there is sufficient evidence to reject the null hypothesis and accept the alternative hypothesis. Using a simple t-test, you can calculate the p-value and determine the significance between two different datasets.
Steps
Set up your experiment

Define your hypothesis. The first step in evaluating statistical significance is to define the question you're aiming to answer and state your hypothesis. A hypothesis is a claim about experimental data and the potential differences in a population. Every experiment has a null hypothesis and an alternative hypothesis. In general terms, you will compare two groups to see if they are the same or different.
- Generally, the null hypothesis (H0) asserts that there is no difference between the two data groups. For instance: Students who read the material before class do not perform better on the final exam.
- The alternative hypothesis (Ha) opposes the null hypothesis and is the statement you aim to support with experimental data. For example: Students who read the material before class actually perform better on the final exam.

Select the significance level to determine if the difference is statistically significant. The significance level (also called alpha) is the threshold you set to decide statistical significance. If the p-value is less than or equal to the chosen significance level, the data is considered statistically significant.
- As a general rule, the significance level (or alpha) is often chosen at 0.05, meaning the probability of the observed difference being random is just 5%.
- The higher the confidence level (and thus the lower the p-value), the more meaningful the result.
- If a higher confidence level is required, reduce the p-value to 0.01. Lower p-values are often used in manufacturing to detect product defects. High reliability is crucial to ensure every part functions as designed.
- For most hypothesis-based experiments, a significance level of 0.05 is acceptable.
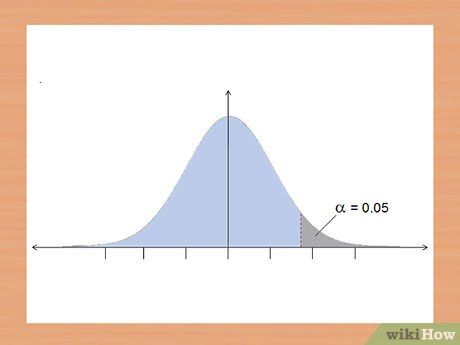
Decide whether to use a one-tailed or two-tailed test. One assumption of the t-test is that your data follows a normal distribution. A normal distribution forms a bell curve with the majority of observations concentrated around the center. The t-test is a mathematical test used to check whether your data lies in the outer part of the normal distribution curve, either above or below, in one of the 'tails' of the curve.
- If you are unsure whether your data is above or below the control group, use a two-tailed test. This allows you to test significance in both directions.
- If you know the expected direction of the data, use a one-tailed test. For example, if you expect students' scores to improve, you would use a one-tailed test.

Determine sample size with power analysis. The power of a test is the probability of detecting the expected result with a given sample size. The common threshold for power (or β) is 80%. Power analysis can be somewhat complex without preliminary data as you need information about the expected mean between groups and their standard deviations. Use online power analysis tools to determine the optimal sample size for your data.
- Researchers often conduct a small pilot study to gather information for power analysis and decide the necessary sample size for a larger, more comprehensive study.
- If you cannot conduct a complex pilot study, estimate the feasible mean value by reviewing articles and research that others may have done. This can give you a good starting point for determining sample size.
Calculate the standard deviation
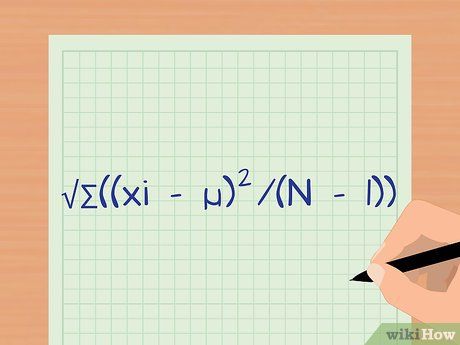
Define the standard deviation formula. The standard deviation measures the spread of data. It tells you about the consistency of each data point in the sample. When you're new to it, the formula might seem complicated, but the following steps will make it easier to understand. The formula is s = √∑((xi – µ)2/(N – 1)).
- s is the standard deviation.
- ∑ means you will sum all the collected observations.
- xi represents each data value.
- µ is the mean of the data for each group.
- N is the total number of observations.

Calculate the average of observations in each group. To calculate the standard deviation, start by computing the average of the observations in each individual group. This average is represented by the Greek letter mu (µ). To do this, simply add all observations together and divide by the total number of observations.
- For example, to find the average score for the group that read the material before class, let’s consider a set of data points. To simplify, we’ll use five scores: 90, 91, 85, 83, and 94 (out of 100).
- Sum all the observations: 90 + 91 + 85 + 83 + 94 = 443.
- Divide the sum by the number of observations (N = 5): 443 / 5 = 88.6.
- The average score for this group is 88.6.

Subtract the mean from each observation value. The next step involves the part (xi – µ) of the equation. You will subtract the mean value you just calculated from each individual observation. With the example above, we have five subtractions.
- (90 – 88.6), (91 – 88.6), (85 – 88.6), (83 – 88.6), and (94 – 88.6).
- The results are 1.4, 2.4, -3.6, -5.6, and 5.4.

Square the differences and sum them. Now, each of the calculated differences will be squared. The negative signs will be eliminated at this step. If you encounter a negative sign afterward or at the end of your calculations, you might have missed the previous step.
- For this example, we now work with 1.96, 5.76, 12.96, 31.36, and 29.16.
- Sum the squared results: 1.96 + 5.76 + 12.96 + 31.36 + 29.16 = 81.2.
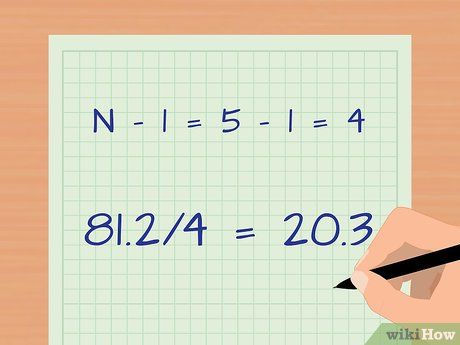
Divide by the total number of observations minus one. Divide by N – 1 to correct for the fact that the calculation is based on a sample, not the entire population of students.
- Subtract: N – 1 = 5 – 1 = 4
- Divide: 81.2 / 4 = 20.3

Take the square root. Once you’ve divided by the number of observations minus one, take the square root of the resulting value. This is the final step in calculating the standard deviation. Some statistical programs can assist you with this calculation once the raw data is entered.
- In this example, the standard deviation of the final exam scores for the students who read the material before class is: s = √20.3 = 4.51.
Determine Statistical Significance
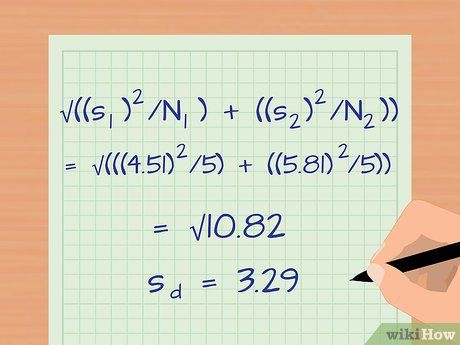
Calculate the variance between two observation groups. Up until now, we've only processed a single group of observations. To compare two groups, you'll need data from both. Calculate the standard deviation for the second observation group and use it to compute the variance between the two experimental groups. The variance formula is: sd = √((s1/N1) + (s2/N2)).
- sd is the variance between groups.
- s1 is the standard deviation of group 1, and N1 is the sample size of group 1.
- s2 is the standard deviation of group 2, and N2 is the sample size of group 2.
- In our example, assume the data from group 2 (students who did not read the material before class) has a sample size of 5 and a standard deviation of 5.81. The variance is:
- sd = √((s1)2/N1) + ((s2)2/N2))
- sd = √(((4.51)2/5) + ((5.81)2/5)) = √((20.34/5) + (33.76/5)) = √(4.07 + 6.75) = √10.82 = 3.29.
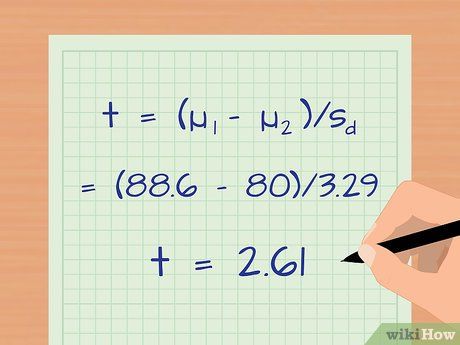
Calculate the t-statistic for the data. The t-statistic allows you to transform data into a comparable form across different datasets. It also enables you to perform the t-test, which tests the probability that two groups differ in a statistically significant way. The t-statistic formula is: t = (µ1 – µ2)/sd.
- µ1 is the mean of the first group.
- µ2 is the mean of the second group.
- sd is the variance between observations.
- Use the larger mean as µ1 to avoid a negative t-statistic value.
- In our example, assume the average score for group 2 (those who did not read before class) is 80. The t-statistic is: t = (µ1 – µ2)/sd = (88.6 – 80)/3.29 = 2.61.
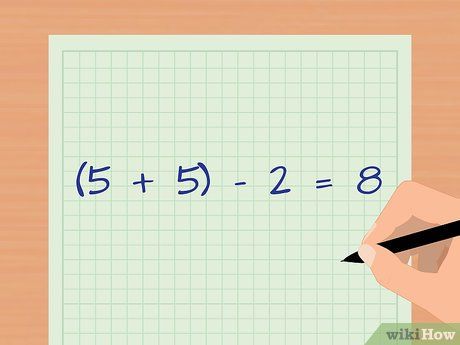
Determine the degrees of freedom for the sample. When using the t-statistic, the degrees of freedom are based on the sample size. Add the observations of each group and then subtract two. In our example, the degrees of freedom (d.f.) is 8 because there are 5 observations in each group ((5 + 5) – 2 = 8).

Use the t-table to assess significance. The t-statistic values and degrees of freedom can be found in statistical textbooks or online. Locate the row corresponding to the degrees of freedom for your data and the p-value that corresponds to your t-statistic.
- With 8 degrees of freedom and t = 2.61, the p-value for a one-tailed test falls between 0.01 and 0.025. Since the chosen significance level is less than or equal to 0.05, our data is statistically significant. Based on this, we reject the null hypothesis and accept the alternative hypothesis: students who read the material before class score higher on their final exams.

Consider conducting further research. Many researchers start with preliminary studies using a few measured values to understand how to design a larger study. Carrying out additional research with more measured values will increase confidence in your conclusions.
Advice
- Statistics is a vast and complex field. Take a high school or university-level (or higher) hypothesis testing course to better understand statistical significance.
Warning
- This analysis focuses on t-tests to examine the difference between two populations with normal distributions. Depending on the complexity of the data, you may need to use a different statistical test.