
While converting an entire PDF file to an Excel document is straightforward, selectively extracting specific data can be more challenging. Nevertheless, there are several methods to achieve this, including manual copy-pasting, using free online tools like Docparser, or utilizing paid software such as Adobe Acrobat Pro DC. This article provides a step-by-step guide on how to extract specific data from PDF to Excel.
Steps
Perform the and Paste Operation

Open the PDF file in a PDF reader program. Double-clicking the PDF file will open it in the default PDF reader, such as Preview on macOS or Edge on Windows.

Select the data you want to extract from the PDF. You can highlight the data by clicking and dragging from the top-left corner to the bottom-right corner of the desired section. The selected data will now be highlighted.
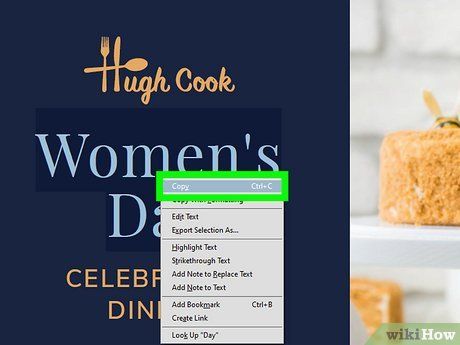
the data to the clipboard. Right-click on the highlighted section and choose .
- Alternatively, you can copy the data by pressing Command + C on Mac or Control + C on Windows.
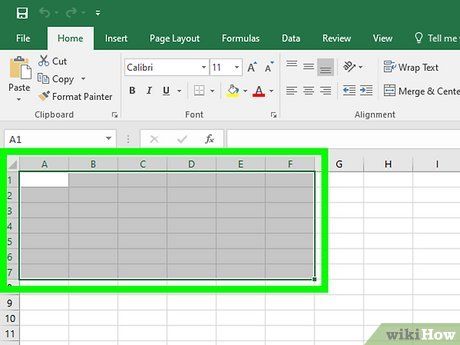
Open the Excel document and select the cells. Similar to the previous step, to quickly select multiple cells, click and drag from the top-left cell to the bottom-right cell.
- Ensure you select enough cells to accommodate the extracted data. Otherwise, only a portion of the data will be pasted.
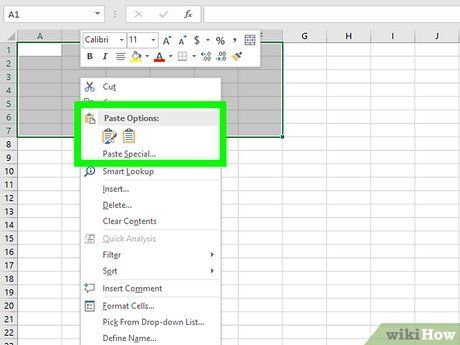
Paste the data into the Excel document. Right-click on one of the selected cells and choose Paste. Although some formatting adjustments may be needed, the Excel file will now contain the data from the PDF!
- If pasting the entire dataset doesn’t work, try copying and pasting individual lines of data into specific cells as needed.
- You can also paste the data by pressing Command + V on Mac or Control + V on Windows.
Using Docparser
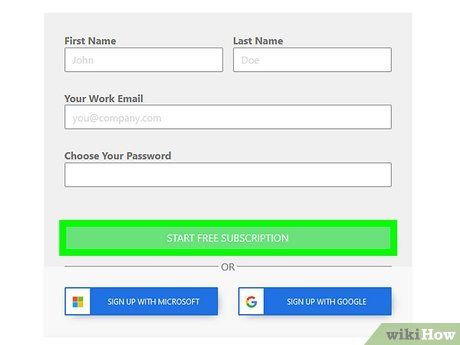
Sign up for an account at https://app.docparser.com/account/signup. Docparser offers various subscription plans, including a free tier that allows you to extract up to 30 documents per month.
- You can register using your Google or Microsoft account or create a dedicated Docparser account.
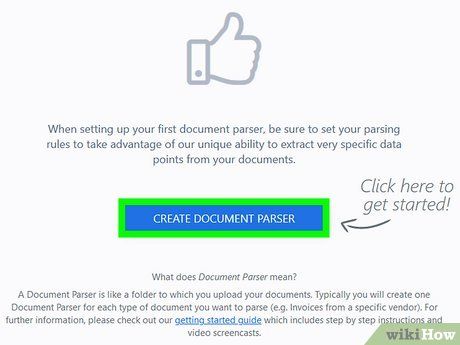
Click on Create Document Parser. This is the blue button located at the bottom center of the screen.
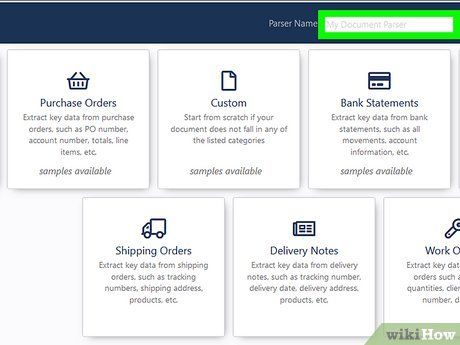
Enter a name and select a template. If the document you want to extract doesn’t match any of the available templates, choose Custom in the first row.
- Docparser templates come with predefined rules tailored to specific document types, while creating a custom template requires you to set your own rules.
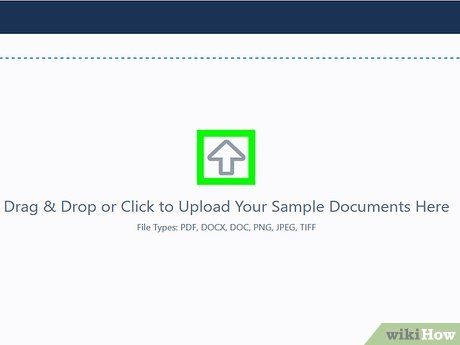
Upload your PDF and click Continue. You can either drag and drop your PDF file onto the website or click the upload box to select the file from your computer. After uploading, click the green button at the top-right corner of the screen.
- If you want to convert multiple PDFs with the same rules, continue uploading additional files.
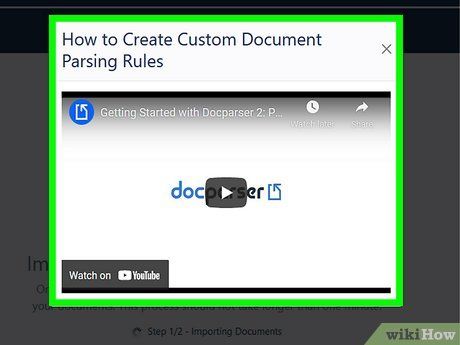
Watch or skip the introductory video on extraction rules. Extraction rules allow you to define how the PDF file is read and converted. If you prefer not to watch the tutorial, click the “X” at the top-right corner of the video window.
- The video is only about 1 minute and 30 seconds long, and it’s recommended to watch it for tips on customizing PDF data extraction.
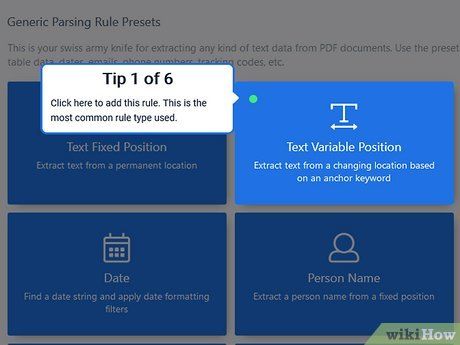
Follow the on-screen instructions. First, Docparser will prompt you to select the Text Variable Position rule set and name the rule. The program will then display additional information about the extracted data, where to add filters, how to filter data, and how to preview the filtered results.
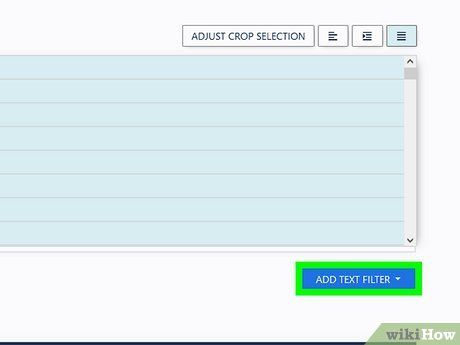
Add text filters and adjust each filter using the “Filtered Result” boxes below. Each box includes an adjustment panel to fine-tune the related filter and preview the data.
- To select a portion of the data, click Add Text Filter, move the cursor to Crop From Start & End, and set the start and end points for the data you want to extract.
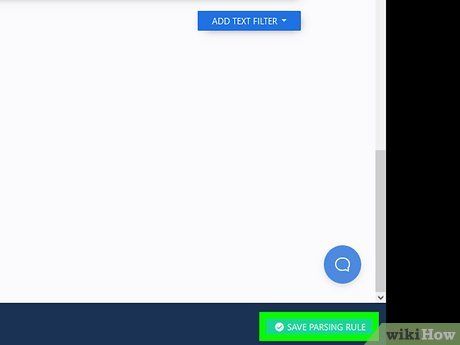
Click Save Parsing Rule. This is the green button at the bottom-right corner of the screen with a small white checkmark icon.
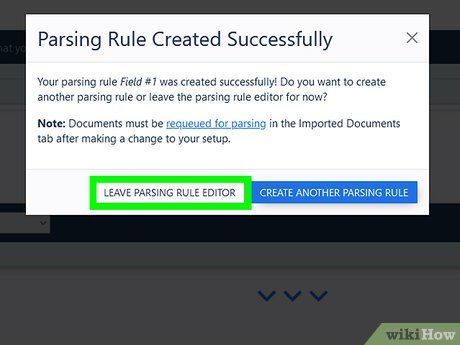
Create another parsing rule or exit the editing tool. Once you’ve finished creating the rule, click the gray Leave Parsing Editor button. Alternatively, click the blue Create Another Parsing Rule button to continue creating rules, then exit the editor and proceed to the next step.
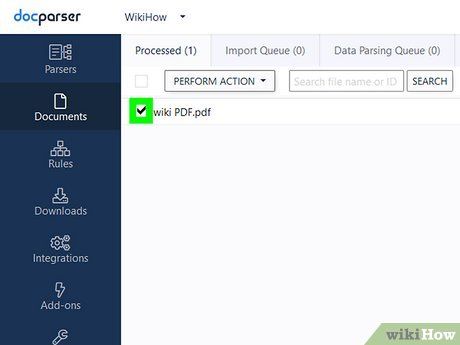
Click the checkbox next to the document name. A solid black checkmark will appear.
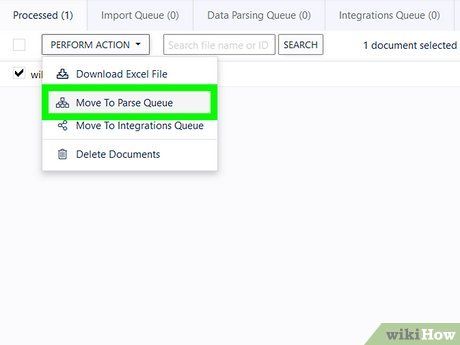
Select Move To Parse Queue from the Perform Action menu. This menu is located at the top-left corner of the screen, just above the document name.
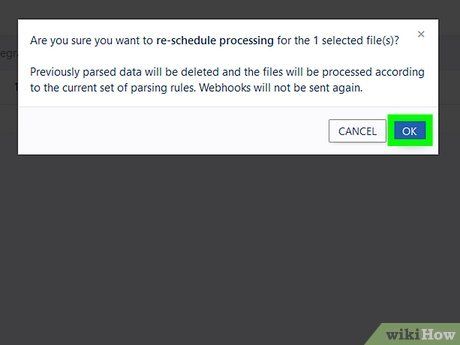
Click Ok, wait a minute, and refresh the page. If you don’t see the document, it might still be processing. Wait another minute and switch between tabs in the text extraction tool.
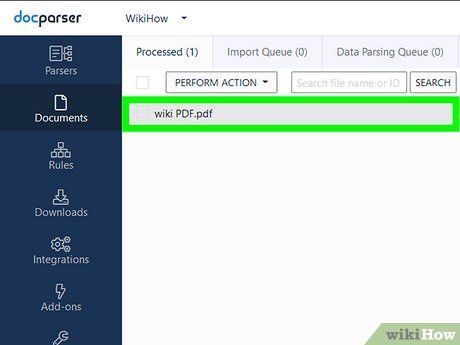
Click on the file name. This is the button on the left side of the page with a downward arrow.
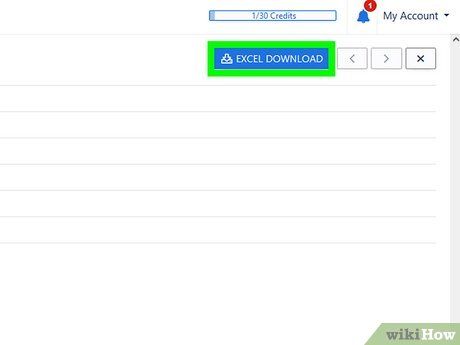
Click Excel Download. You now have an Excel document containing the selected data from the PDF!
- Ensure downloads are enabled on the page before downloading the file.
Using Adobe Acrobat Pro DC
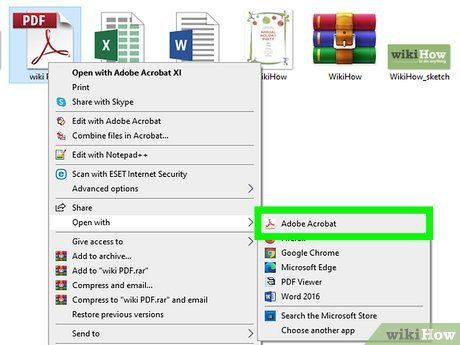
Open the desired PDF file using Acrobat. If Acrobat is not your default PDF reader, you can open the file by right-clicking it and selecting Acrobat from the Open With menu.
- You may need to search for Acrobat in the Open With menu by clicking Other… on Mac or Choose another app on Windows.

Select the data you wish to extract. Highlight the data by clicking and dragging from the top-left corner to the bottom-right corner of the desired section. The selected data will now be highlighted.
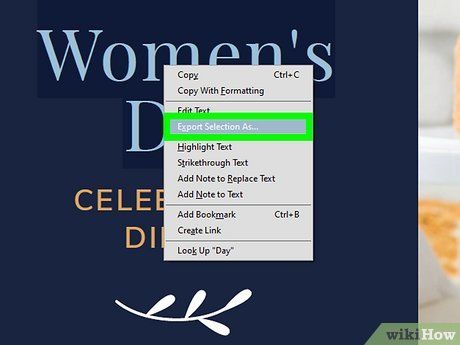
Right-click the selected data and choose Export Selection As…. A new window will appear with options for exporting the selected data from the PDF.
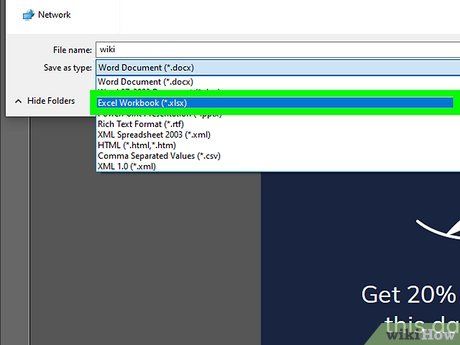
Choose the XLSX format from the Save As Type list and click Save. You now have an Excel spreadsheet containing the extracted data from the PDF!