
When working with Oracle, you might occasionally come across duplicate data entries. These redundant rows can be removed by identifying and using their RowID or row addresses. Before starting, it’s advisable to back up your database in case you need to review it later.
Steps
Identify Duplicate Data
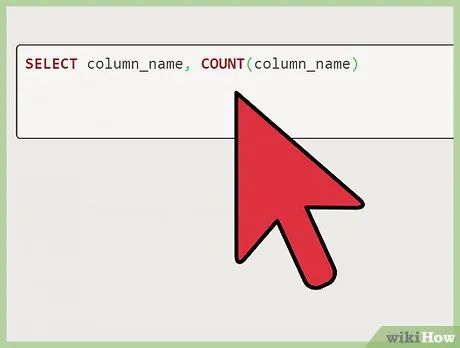
Detect duplicate data. In this example, we’ll identify duplicate data as the name "Alan." Ensure the data you intend to remove is genuinely duplicated by running the Structured Query Language (SQL) command provided below.
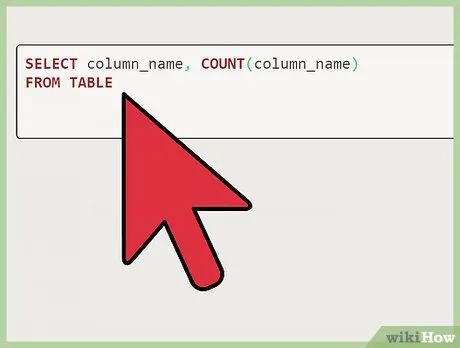
Search within the column named "Names". In the example of the "Names" column, replace "column_name" with Names.
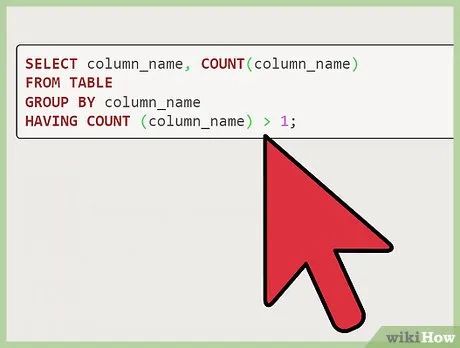
Search within another column. If you want to identify duplicate data in a different column, such as Alan's age instead of his name, input "Ages" in place of "column_name". Other cases follow the same approach.
select column_name, count(column_name) from table group by column_name having count (column_name) > 1;
Delete a Duplicate Entry
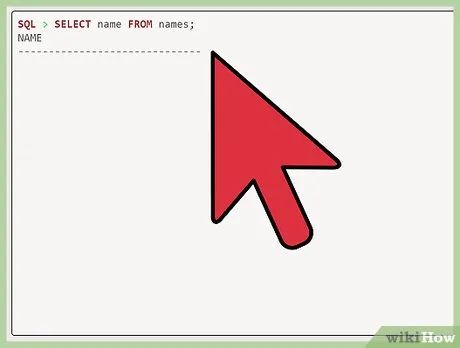
Select "name from names". After "SQL," enter "select name from names".
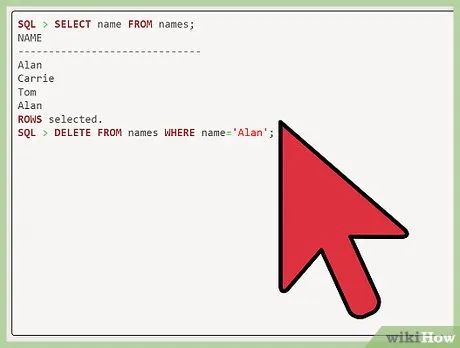
Delete all rows with duplicate names. After "SQL," input "delete from names where name='Alan';". Note that capitalization is crucial as this will remove all rows with the name "Alan". After "SQL," type "commit".
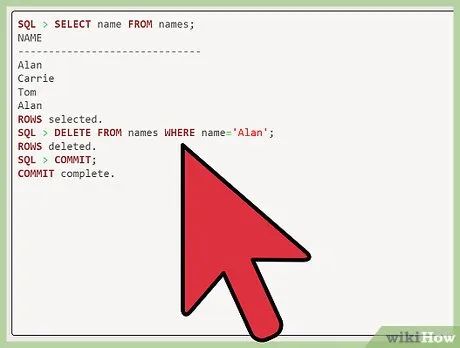
Reinsert the row without duplicate data. Now that all rows with the name "Alan" have been deleted, you can reinsert the name by typing "insert into name values ('Alan');". After "SQL," enter "commit" to create the new row.
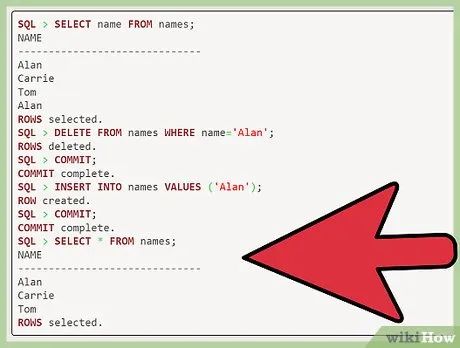
View the updated list. After completing the steps above, you can verify that no duplicate data remains by typing "select * from names".
SQL > select name from names; NAME ------------------------------ Alan Carrie Tom Alan rows selected. SQL > delete from names where name='Alan'; rows deleted. SQL > commit; Commit complete. SQL > insert into names values ('Alan'); row created. SQL > commit; Commit complete. SQL > select * from names; NAME ------------------------------ Alan Carrie Tom rows selected.
Delete Multiple Duplicate Entries

Select the RowID you want to delete. After "SQL," type "select rowid, name from names;".

Remove duplicate data. After "SQL," enter "delete from names a where rowid > (select min(rowid) from names b where b.name=a.name);" to delete duplicate entries.

Check for duplicate data. After completing the above step, verify if any duplicate entries remain by entering the command "select rowid,name from names;" followed by "commit".
SQL > select rowid,name from names; ROWID NAME ------------------ ------------------------------ AABJnsAAGAAAdfOAAA Alan AABJnsAAGAAAdfOAAB Alan AABJnsAAGAAAdfOAAC Carrie AABJnsAAGAAAdfOAAD Tom AABJnsAAGAAAdfOAAF Alan rows selected. SQL > delete from names a where rowid > (select min(rowid) from names b where b.name=a.name ); rows deleted. SQL > select rowid,name from names; ROWID NAME ------------------ ------------------------------ AABJnsAAGAAAdfOAAA Alan AABJnsAAGAAAdfOAAC Carrie AABJnsAAGAAAdfOAAD Tom rows selected. SQL > commit; Commit complete.
Delete Rows with Columns
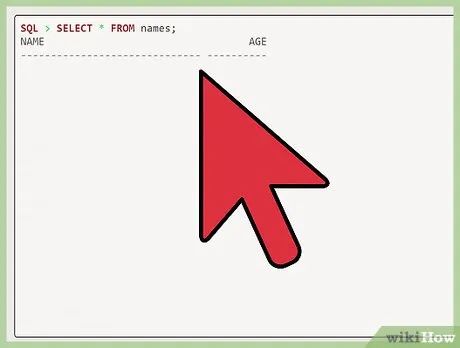
Select the row. After "SQL," type "select * from names;" to view the row you need.
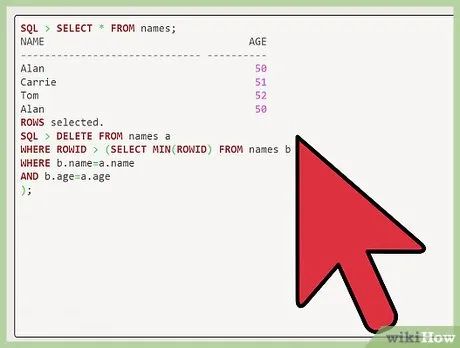
Delete duplicate rows by identifying their columns. After "SQL," enter "delete from names a where rowid > (select min(rowid) from names b where b.name=a.name and b.age=a.age);" to remove duplicate data.
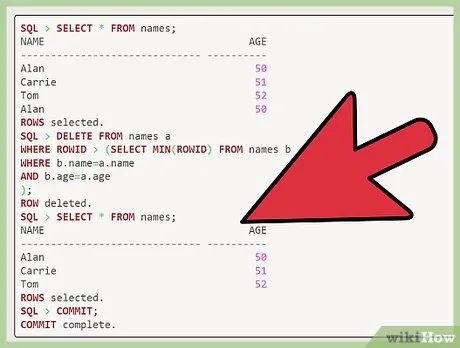
Verify duplicate data removal. After completing the steps above, type "select * from names;" and "commit" to ensure all duplicate entries have been deleted.
SQL > select * from names; NAME AGE ------------------------------ ---------- Alan 50 Carrie 51 Tom 52 Alan 50 rows selected. SQL > delete from names a where rowid > (select min(rowid) from names b where b.name=a.name and b.age=a.age ); row deleted. SQL > select * from names; NAME AGE ------------------------------ ---------- Alan 50 Carrie 51 Tom 52 rows selected. SQL > commit; Commit complete.
Warning
- Before deleting any data, back up the database during your session so you can review it later (in case of any uncertainties).
SQL > create table alan.names_backup as select * from names; Table created.