
 3-D visuals begin as basic structures known as wireframes.
2008 Mytour
3-D visuals begin as basic structures known as wireframes.
2008 MytourYou’re likely reading this on a computer screen — a display with two main dimensions: height and width. But when you watch a film like "Toy Story II" or play a game like Tomb Raider, you’re peeking into a three-dimensional realm. One of the most remarkable aspects of this view is that it could represent our real world, a future world, or even an entirely fictional world created by the minds behind the movie or game. And all of these worlds are presented on the same screen you use for writing reports or managing your finances.
How does your computer manage to make you believe that the flat screen stretches into a series of deep rooms? How do game developers make you feel like you’re watching real characters move through real environments? We’ll explore the visual techniques 3-D graphic artists use, and how hardware engineers ensure these tricks are so seamless that it feels like a movie responding to your every action.
How Does a Picture Become 3-D?
An image that seems to possess height, width, and depth is considered three-dimensional (or 3-D). In contrast, a picture that only shows height and width, without depth, is known as two-dimensional (or 2-D). Some 2-D images are intentionally created this way. Take, for instance, the universally recognized symbols that indicate which restroom to use. These symbols are designed for quick recognition, relying on basic shapes. Any additional details—such as the person’s clothing, hair color, or fitness habits—would only slow down the ability to identify the restroom. This is a key difference between 2-D and 3-D graphics: 2-D is efficient for conveying simple information quickly, while 3-D provides a more intricate narrative but requires much more data to do so.
For example, a triangle consists of three sides and three angles — the minimal components required to define it. A pyramid, however, is a three-dimensional shape with four triangular sides. It requires five lines and six angles to describe it, nearly twice the information needed for a triangle.
For centuries, artists have understood techniques that can transform a flat, 2-D image into a semblance of the real, 3-D world. You can observe some of these tricks in photographs you might scan and view on a computer screen: Objects become smaller as they move farther away; objects closer to the camera stay sharp, while distant objects blur; colors tend to fade as they recede. However, when discussing 3-D graphics on computers today, we’re not referring to still images — we’re talking about moving pictures.
Converting a 2-D image into a 3-D representation demands a significant amount of added detail. Going from a 3-D still image to realistic moving visuals requires even more. Part of the challenge comes from our heightened expectations. In the mid-1970s, a game like "Pong" could wow audiences with its simple on-screen graphics. Today, we expect video game visuals to be as detailed and fluid as DVD movies, raising the bar for 3-D graphics on personal computers, Macintoshes, and increasingly powerful game consoles like the Dreamcast and Playstation II.
What Are 3-D Graphics?
For many people, the most common way to experience 3-D graphics is through computer games or advanced gaming systems. These games, as well as films created with computer-generated imagery, must go through three essential stages to produce and display a convincing 3-D scene:
- Building a virtual 3-D environment.
- Deciding which portion of the environment will be displayed on the screen.
- Determining how each pixel on the screen should appear to create the most lifelike image possible.
Building a Virtual 3-D Environment
A virtual 3-D world is not the same as a single image of that world. This concept is also true for our real world. For instance, if you consider a small part of the real world, like your hand resting on a desktop, your hand has certain characteristics that define how it moves and appears. Your finger joints bend toward your palm, not away from it. If you slap your hand down on the desk, the desk doesn’t splash; it's always solid and hard. Your hand can’t pass through the desk. These behaviors are evident in any picture you take, but no single picture can prove them. In the real world, this is how hands work and how they will always behave. On the other hand, objects in a virtual 3-D world do not exist naturally like your hand. They are entirely synthetic. The only properties these virtual objects possess are those assigned to them by the software. Developers must use specialized tools and meticulously define a virtual 3-D environment to ensure that everything in it behaves in a consistent manner.
What Part of the Virtual World Is Displayed on the Screen?
At any given time, the screen displays only a small portion of the virtual 3-D world designed for a computer game. What you see on the screen depends on how the world is structured, where you decide to go, and which direction you choose to look. No matter where you move – forward or backward, up or down, left or right – the virtual 3-D world surrounding you dictates what you see from that spot and in that direction. Additionally, what you see needs to be consistent from scene to scene. If you're looking at an object from the same distance, it should appear the same height, regardless of the direction you're facing. Each object should behave and appear in a way that convinces you it consistently possesses the same properties, such as mass, rigidity, softness, pliability, and so on.
Game developers invest significant effort into designing 3-D worlds so that you can navigate them without encountering anything that disrupts the illusion. The last thing you want to see is two solid objects passing through one another – a jarring reminder that everything you're witnessing is fictional.
The third step requires just as much processing power as the first two and must occur in real-time for both games and videos. We will delve deeper into this in the next section.
How to Make It Look Like the Real Thing
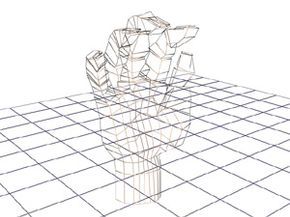 This illustration depicts the wireframe of a hand constructed from relatively few polygons – 862 in total.
Mytour.com
This illustration depicts the wireframe of a hand constructed from relatively few polygons – 862 in total.
Mytour.comNo matter how vast or intricate a virtual 3-D world may be, a computer can only represent it by placing pixels on a 2-D screen. This section will explore how these images on the screen are made to look lifelike, particularly focusing on how scenes are rendered to resemble the real world as closely as possible. First, we will examine how a single, stationary object is made to appear realistic. Then, we'll extend the same analysis to a whole scene. Finally, we'll explore the processes a computer uses to display full-motion scenes, with realistic images moving at natural speeds.
Creating a realistic object involves several key components. Among the most critical elements are shapes, surface textures, lighting, perspective, depth of field, and anti-aliasing.
Shapes
 The outline of the wireframe can be enhanced to look more natural and smooth, but this requires significantly more polygons – 3,444 in total.
Mytour.com
The outline of the wireframe can be enhanced to look more natural and smooth, but this requires significantly more polygons – 3,444 in total.
Mytour.comWhen we gaze outside, we observe scenes filled with various shapes, combining straight lines and curves in a range of sizes. Similarly, when we view a 3-D graphical image on our computer screen, we encounter images made up of numerous shapes, most of which are constructed from straight lines. We see squares, rectangles, parallelograms, circles, and rhomboids, but primarily, we see triangles. However, to create images that appear to have the smooth curves common in nature, some of these shapes must be exceedingly small, and a complex image, such as a human body, may require thousands of these shapes to form a structure known as a wireframe. At this stage, the structure may be recognizable as the symbol of what it will ultimately depict, but the next crucial step is to give the wireframe a surface.
Surface Textures
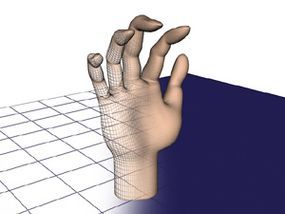 By adding a surface to the wireframe, the image begins to transition from something clearly mathematical to a more recognizable object, like a hand.
Mytour.com
By adding a surface to the wireframe, the image begins to transition from something clearly mathematical to a more recognizable object, like a hand.
Mytour.comWhen we encounter a surface in the real world, we gather information about it in two primary ways. We can observe it, sometimes from multiple perspectives, and we can touch it to determine its hardness or softness. However, in a 3-D graphic image, we can only rely on our visual perception to gather all the information possible. This information can be categorized into three key aspects:
- Color: What color does the surface have? Is the color uniform across its entire surface?
- Texture: Does the surface appear smooth, or does it have lines, bumps, craters, or other irregularities?
- Reflectance: How much light does the surface reflect? Are reflections of nearby objects sharp or blurry?
To make an image appear "real," it's essential to incorporate a variety of these three features throughout the image. Take a moment to look around: Your computer keyboard has a different color, texture, and reflectance compared to your desktop, which in turn has different characteristics than your arm. For realistic color, it’s crucial for the computer to be able to select from millions of different colors for the pixels forming the image. Texture variety comes from mathematical models that simulate surfaces ranging from frog skin to Jell-o gelatin, as well as texture maps that are applied to those surfaces. Additionally, we associate sensations such as softness, hardness, warmth, and coldness with particular combinations of color, texture, and reflectance. If any of these elements are incorrect, the illusion of reality is broken.
We will explore the concepts of lighting and perspective in the following section.
Lighting and Perspective
 Lighting in an image serves not only to enhance the object's depth through shading but also helps to “anchor” objects to the ground by creating shadows.
Lighting in an image serves not only to enhance the object's depth through shading but also helps to “anchor” objects to the ground by creating shadows.When you enter a room, you turn on a light. You likely don't spend much time thinking about how the light travels from the bulb or tube and spreads across the space. However, those creating 3-D graphics must consider it carefully, as all the surfaces around the wireframes need to be illuminated from a specific source. A technique known as ray-tracing maps the journey of imaginary light rays as they emanate from the bulb, bounce off reflective surfaces like mirrors and walls, and ultimately hit objects with varying intensity from different angles. This is complex even with just a single light bulb, but in reality, most rooms have multiple light sources -- such as lamps, ceiling fixtures, windows, candles, and more.
Lighting is essential for two effects that give objects the sense of weight and substance: shading and shadows. Shading occurs when one side of an object is illuminated more brightly than the other. This effect helps a ball appear round, accentuates high cheekbones, and gives depth to the folds of a blanket. These light intensity variations, combined with shape, create the illusion that an object has depth, in addition to height and width. The second effect, shadows, reinforces the perception of weight.
Solid objects cast shadows when illuminated, which is something we observe when a sundial or a tree casts its shadow on the ground. Since we're accustomed to seeing real-world objects and people cast shadows, including them in 3-D images strengthens the illusion that we're peering through a window into the real world, not just looking at a screen full of mathematically calculated shapes.
Perspective
The term 'perspective' may sound technical, but it actually refers to a simple visual effect that we have all experienced. If you stand beside a long, straight road and gaze into the distance, the road appears to converge at a single point on the horizon. Similarly, trees along the road seem to shrink the farther away they are from you. In fact, all the trees appear to converge toward that same vanishing point. When all objects in a scene appear to converge at a single point in the distance, this is known as perspective. While there are variations, most 3-D graphics use the 'single point perspective' technique just described.
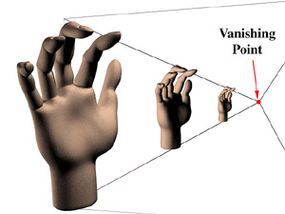
In this illustration, the hands are separate, but in many scenes, objects partially block the view of others. For these scenes, the software must not only compute the relative sizes of objects but also determine which item is in front and how much it obscures other items. The Z-Buffer is the most common technique used to handle this. It gets its name from the imaginary Z-axis, which extends from the screen through the scene toward the horizon. (There are two additional axes to consider: the x-axis, measuring side to side, and the y-axis, measuring top to bottom.)
The Z-buffer assigns a value to each polygon based on how close an object containing that polygon is to the front of the scene. Typically, lower values are given to objects closer to the screen, while higher values are assigned to those farther away. For example, in a 16-bit Z-buffer, an object closest to the screen might receive the value -32,768, while an object at the greatest distance would be assigned 32,767.
In the real world, we naturally can't see objects that are hidden behind others, so we don’t have to worry about figuring out what should be visible. However, computers face this challenge constantly and resolve it in a simple yet effective way. As each object is created, its Z-value is compared with the Z-values of other objects occupying the same x- and y-coordinates. The object with the smallest Z-value is rendered fully, while objects with higher Z-values aren’t rendered where they overlap. This process ensures that background objects aren’t visible through the foreground characters. Additionally, since the Z-buffer is used before the full rendering of objects, parts of the scene hidden behind other objects don’t need to be rendered at all, boosting the performance of graphics. In the next section, we’ll explore the depth of field element.
Depth of Field
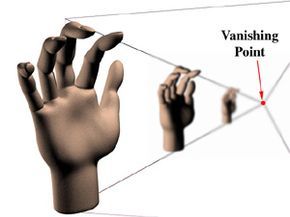
Another visual effect used to enhance 3-D scenes is depth of field. For instance, when looking at a line of trees along a road, the trees in the distance appear smaller, but something else happens as well. The trees closer to you are in focus, while the ones farther away become blurry. This effect is especially noticeable in photographs or films. Filmmakers and 3-D animators often use depth of field for two reasons. First, it strengthens the illusion of depth in the scene. It’s possible for the computer to render everything in perfect focus, no matter its distance, but that would make the scene feel unnatural. The depth of field effect is familiar to us, and having everything in focus would disrupt the feeling of realism.
The second purpose of depth of field in films is to guide the audience’s focus to specific objects or characters. For example, a director might use a 'shallow depth of field' to ensure that only the main actor is in focus, drawing the viewer's attention to them. In contrast, a 'deep depth of field' might be used for a scene that aims to showcase the vastness of nature, keeping as much of the scene in focus as possible to enhance the sense of scale.
Anti-aliasing
Anti-aliasing is another technique that tricks the eye. While digital graphics systems excel at drawing straight vertical and horizontal lines, they struggle when it comes to curves or diagonal lines, which are common in the real world. These lines often end up looking jagged, resembling stair steps, rather than smooth curves. To make these lines appear smooth, the computer can add subtle variations in color to the surrounding pixels. These 'smoothed' pixels create the illusion that the jagged edges are no longer present. This process, called anti-aliasing, is one of the distinguishing techniques between computer-generated 3-D graphics and those drawn by hand. The computer must keep up with the movement of the lines and apply the right amount of 'anti-jaggy' coloring, a task that adds complexity to 3-D animation creation.
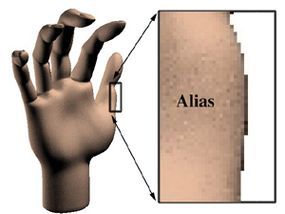 The jagged, 'stair-step' effect that appears when straight lines are rendered from pixels is a clear indicator that an image is computer-generated.
The jagged, 'stair-step' effect that appears when straight lines are rendered from pixels is a clear indicator that an image is computer-generated.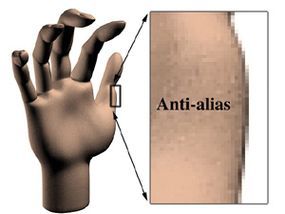 To reduce the appearance of the jagged edges, gray pixels are drawn around the lines, effectively 'blurring' the edges. This process softens the stair-step effect and makes the image look more natural.
To reduce the appearance of the jagged edges, gray pixels are drawn around the lines, effectively 'blurring' the edges. This process softens the stair-step effect and makes the image look more natural.In the following sections, we will explore how to animate 3-D images.
Realistic Examples

By combining all the techniques we've discussed, incredibly realistic scenes can be created. In modern video games and films, computer-generated objects are often placed into real photographic backgrounds, further enhancing the illusion. The results are truly remarkable, especially when comparing photographs to computer-generated imagery.
This is a photo of a sidewalk near the How Stuff Works office. In one of the images that follows, a ball was physically placed on the sidewalk and photographed. In another, an artist used a computer graphics program to generate the ball.
 Image A
Image A Image B
Image BCan you identify which ball is real? The answer is revealed at the end of the article.
Animating 3-D Graphics
Up until now, we've focused on the elements that help make any digital image appear more lifelike, whether it’s a static picture or part of an animated sequence. However, when it comes to animation, additional techniques are employed to create the illusion of "live action" rather than just computer-generated graphics.
What frame rate is ideal?
When you watch a movie at the theater, a series of images, known as frames, is projected at a rate of 24 frames per second. Your retina holds onto each image for slightly longer than 1/24th of a second, so your brain merges these frames into a smooth, flowing picture of movement.
From a different perspective, each frame of a film is a photograph taken with an exposure of 1/24 of a second. This is much longer than the exposures used in "stop action" photography, where objects like runners appear frozen mid-motion. In a racing movie, for example, you might notice that some cars appear slightly "blurred" because they moved while the camera’s shutter was open. This motion blur is something we are accustomed to, and it helps create a more realistic look when displayed on screen.
Unlike traditional photographs, digital 3-D images don’t naturally produce the motion blur we expect when an object moves within a frame. To enhance realism, programmers need to artificially add this effect. Some game designers argue that to truly replicate the natural blurring, a frame rate of over 30 frames per second is necessary, with some pushing for 60 frames per second. While this higher rate allows for finer details and smoother transitions between frames, it comes at a cost: a significant increase in the number of frames to render for each action sequence. For instance, a 6.5-minute chase scene would require 9,360 frames at 24 frames per second, but at 60 frames per second, the same scene would require 23,400 frames.
Motion Blur
The blur added by programmers to make moving images appear more realistic is called "motion blur" or "spatial anti-aliasing." If you've ever used the "mouse trails" feature in Windows, you've experienced a simplified form of this technique. As the object moves, copies of it are left behind, fading out in intensity and clarity as the object moves further. The length of the trail, the rate at which the copies fade, and other factors depend on the object’s speed, its proximity to the viewer, and its importance in the scene. Clearly, achieving realistic motion involves numerous choices and precise programming.
At times, achieving realistic imagery requires compromising on the precision of digital rendering, both for still and animated scenes. Reflections provide a prime example. While chrome cars or spaceships may perfectly reflect their surroundings through ray-tracing, the real world is not made of chrome. Surfaces like wood, marble, and polished metal do reflect, but not as flawlessly as mirrors. For these surfaces to appear realistic in a digital scene, their reflections must be blurred, with the degree of blurring varying depending on the surface and its proximity to the focus of the scene.
The Challenge of Creating Smooth Motion
The process of displaying a 3-D image on a screen involves several complex stages. Not only must the object be defined and created, but the software also has to calculate and render every pixel that makes up the image. This includes factoring in the wireframe’s triangles and polygons, the surface texture, and the light rays from different sources reflecting off various surfaces. Before the software even starts painting the pixels on the screen, all these components must be calculated. You might think the computational work is done once the painting begins, but it’s at the rendering stage where the real number crunching takes place.
In today's digital world, the lowest point of "high-resolution" is defined by a screen resolution of 1024 x 768, which adds up to 786,432 individual pixels. When 32 bits of color are used, this totals 25,165,824 bits per image. For a frame rate of 60 frames per second, the computer needs to handle over 1.5 billion bits per second just to display the image. This doesn’t even account for all the other processing the computer must do to decide on the image’s content, colors, shapes, and lighting. Considering the immense amount of processing involved, it’s no surprise that graphics processing is increasingly being handled by dedicated graphics cards instead of the CPU, which needs all the help it can get.
Transforms and Processors: Work, Work, Work
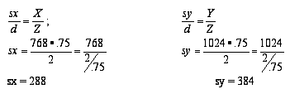
Looking at the number of bits that make up an image only gives us part of the story when it comes to processing. To understand the total load on the computer, we need to talk about transforms. A transform is a mathematical process used whenever we change the way we view something. For instance, as a car moves toward us in a scene, a transform is used to make it appear larger. Another common transform is when a 3-D scene created by a computer is converted into a 2-D image for display on the screen. Let's dive into the math behind this transform, which is applied to every frame in a 3-D game, to give you a sense of the enormous mathematical effort required to generate just one screen. Don’t worry about doing the math yourself—it’s the computer’s job. This is just to help you appreciate how much your computer is doing while you’re playing a game.
The first step in this process involves several key variables:
- X = 758 -- the height of the "world" we're observing.
- Y = 1024 -- the width of the world we're observing
- Z = 2 -- the depth (front to back) of the world we're observing
- Sx = the height of our view into the world
- Sy = the width of our view into the world
- Sz = a depth factor that determines the visibility order of objects, ensuring some are in front of others
- D = .75 -- the distance between our viewpoint and the window into this imaginary world.
The first step is to determine the size of the windows that allow us to peer into the imaginary world.
Once the window size is figured out, we use a perspective transformation to get closer to projecting the world onto a monitor screen. At this point, additional variables come into play.
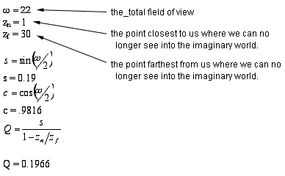
Now, consider a point (X, Y, Z, 1.0) in this 3-D world. Its transformed position would be (X', Y', Z', W'), which we can calculate using the following equations:
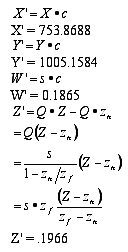
At this stage, another transformation must occur before the image is ready to be displayed on the monitor’s screen. You can start to grasp the extent of the calculations involved—and keep in mind, this is just for a single vector (or line) in the image! Imagine the complexity when multiple objects and characters are involved, and all this has to be done 60 times per second. Aren't you glad computers exist?
In the example below, you'll see an animation depicting a walk through the newly designed How Stuff Works office. Notice how this sequence is relatively simple compared to typical scenes in 3-D games. There are no enemies jumping from behind desks, no projectiles flying through the air, and no terrifying creatures appearing in cubicles. From the standpoint of what’s happening in the scene, this is basic animation. However, even this straightforward sequence still tackles several of the issues we've discussed. The walls and furniture are textured over wireframe structures. Light rays create shadows, and as the viewpoint shifts during the walk, certain objects emerge around corners or from behind walls, a result of the z-buffer calculations. All these elements must be processed before the image can be rendered on the monitor. It’s clear that even the most powerful modern CPUs need assistance with the heavy processing required for 3-D graphics and games. That’s where graphics co-processor boards come into play.
How Graphics Boards Help
Since the early days of personal computers, most graphics boards have functioned as translators, converting the fully rendered image created by the computer’s CPU into the electrical impulses that control the computer’s monitor. While this method works, it relies heavily on the CPU to process the image, along with all other tasks such as sound, user input (in games), and system interrupts. With all the work a modern computer must do to run 3-D games and multimedia presentations, even the fastest processors can become overwhelmed and fail to handle everything in real time. This is where the graphics co-processor steps in: by sharing the workload with the CPU, the graphics co-processor ensures a smoother, more responsive multimedia experience.
As we’ve seen, the first step in creating a 3-D digital image is constructing a wireframe world made of triangles and polygons. This wireframe is then transformed from a 3-D mathematical model into a 2-D pattern that can be displayed on a screen. After the transformation, the image is rendered with surface textures, lit from multiple light sources, and converted into a final display pattern for the monitor. The most common graphics co-processors in modern display boards, however, take over the rendering task once the wireframe has been created and transformed into a 2-D polygonal model. For example, the VooDoo3 and TNT2 Ultra graphics co-processors handle rendering, relieving the CPU from this step. More advanced graphics processors go even further, taking responsibility earlier in the process.
One way to ease the CPU’s burden is through the GeForce 256 by Nvidia. In addition to the rendering tasks handled by previous-generation boards, the GeForce 256 also takes on the job of transforming wireframe models from 3-D mathematical space into 2-D display space and managing lighting effects. Since both transformation and ray-tracing involve complex floating point calculations (which use fractions and allow for high precision by shifting the decimal point), these tasks significantly reduce the CPU’s workload. By offloading these heavy tasks, the graphics processor can perform them more efficiently and quickly, freeing the CPU for other essential operations.
The Voodoo 5 from 3dfx introduces a new feature that further offloads tasks from the CPU. Dubbed the T-buffer, this technology enhances the rendering process rather than piling on more work for the processor. The T-buffer focuses on improving anti-aliasing by creating up to four slightly offset versions of the same image, which are then merged to gently blur the edges of objects, eliminating the "jaggies" that often mar computer-generated visuals. This same technique is used to simulate motion blur, softened shadows, and depth-of-field effects. The result is a smoother, more realistic image that graphics designers seek. The primary aim behind the Voodoo 5’s design is to provide full-screen anti-aliasing without sacrificing frame rates.
While computer graphics still have some way to go before we see continuous, perfectly realistic moving images, they have advanced significantly since the days of simple 80-character monochrome text. Today, millions of people are enjoying the immersive experiences provided by games and simulations powered by modern technology. The future promises even more breakthroughs, with next-gen 3-D processors coming closer to creating worlds that feel truly tangible. Major improvements in PC graphics hardware seem to arrive roughly every six months, while software development progresses more slowly. However, it’s clear that, much like the internet, computer graphics are rapidly becoming a compelling alternative to traditional TV viewing.
Returning to the ball images, how well did you do? Image A is a computer-generated ball, and Image B shows a real ball photographed on the sidewalk. It’s not so easy to tell them apart, is it?