
 The World Wide Web operates using a combination of commands and metadata. hh5800 / Getty Images
The World Wide Web operates using a combination of commands and metadata. hh5800 / Getty ImagesThe World Wide Web presents a fascinating paradox: it’s built by computers, yet designed for human use. The websites you visit daily incorporate natural language, images, and page structures to display information in a user-friendly way. While these elements are essential for creating and maintaining the Web, computers themselves struggle to fully comprehend this data. They can't read, understand relationships, or make decisions like humans do.
The Semantic Web aims to assist computers in 'reading' and utilizing the Web. The concept is simple: by adding metadata to web pages, the current World Wide Web can become machine-readable. This won't grant artificial intelligence or self-awareness to computers, but it will provide them with tools to locate, exchange, and somewhat interpret information. It’s an enhancement, not a replacement, for the World Wide Web.
This might seem a bit abstract, and indeed it is. Although some websites have already implemented Semantic Web principles, many of the required tools are still being developed. In this article, we’ll make these concepts and tools more tangible by applying them to a galaxy far, far away.
Special thanks to Josh Senecal for his help with this article.
Why the Semantic Web?
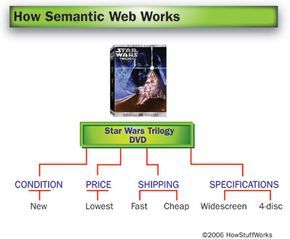
Imagine you’re looking to purchase a "Star Wars Trilogy" boxed set online, with a few specific requirements. First, you prefer widescreen DVDs over full-screen, and you want the version that includes the extra bonus disc. Secondly, you want the best price available, but you'd rather buy a new set instead of a used one. Finally, you don’t want to pay too much for shipping, and you don’t want to wait too long for delivery.
At this point in the Web’s development, your best option would be to visit various retailers’ websites, comparing prices, shipping times, and costs. You could also use a price-comparison website that aggregates options from several retailers. Either way, you’ll need to do most of the work yourself before making your final decision and placing the order.
With the Semantic Web, you’d have an additional option. You could input your preferences into a digital agent, which would then search the Web, find the best choice for you, and place the order. The agent could also open personal finance software on your computer to track the amount you spent and record the expected delivery date of your DVDs on your calendar. Over time, your agent would learn your preferences and habits, so if you had a negative experience with a particular site, it would avoid that site in the future.
The agent wouldn’t perform this task by reading descriptions and viewing images like a human. Instead, it would analyze metadata—machine-readable data that clearly defines what the agent needs to know. In the Semantic Web, metadata is hidden from human viewers but visible to computers. These metadata tags also enable more refined and focused Web searches, producing more accurate results. To paraphrase Tim Berners-Lee, the creator of the World Wide Web, these tools would transform the Web from a vast book into a massive database.
Next, we’ll explore the tools that can turn documents into machine-readable formats.
How much do you know about Web 3.0 and its capabilities? Put your knowledge to the test with our Web 3.0 Quiz!
Creating a machine-readable Web requires layers of metadata, logic, and security. Most visual depictions of these layers feature a stack—a tower of blocks that represent each layer. As the ideas behind the Semantic Web evolve, so too does the stack. You can view a typical version of this stack here, as part of an introduction to the Semantic Web.
Marking Up: XML and RDF
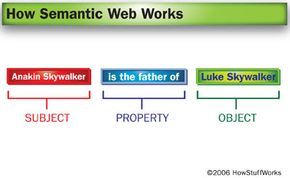 An RDF triple consists of a subject (Anakin Skywalker), an object (Luke Skywalker), and a property that connects the two.
An RDF triple consists of a subject (Anakin Skywalker), an object (Luke Skywalker), and a property that connects the two.Suppose you want to make this sentence understandable to a computer:
Anakin Skywalker is Luke Skywalker's father.
For humans, it's straightforward to understand this sentence – Anakin and Luke Skywalker are both individuals, and there's a connection between them. You recognize that a father is a type of parent, and that the sentence implies Luke is Anakin's son. However, a computer can't deduce this on its own. To help a computer comprehend the meaning, you'd need to add machine-readable information that defines who Anakin and Luke are, and what their relationship entails. This begins with two tools: eXtensible Markup Language (XML) and Resource Description Framework (RDF).
XML is a markup language similar to hypertext markup language (HTML), which you may be familiar with from browsing the Web. While HTML controls the presentation of the information you view online, XML works alongside HTML (but doesn't replace it) by introducing tags that describe data. These tags are invisible to human readers but can be interpreted by computers. Tags are already widely used on the Web, and existing bots, such as those that gather data for search engines, can process them.
RDF serves its purpose by utilizing XML tags to establish a framework that describes resources. In the context of RDF, nearly everything in the world qualifies as a resource. This framework connects a resource (such as Anakin Skywalker or the "Star Wars" trilogy) to a unique item or location on the Web, ensuring the computer can accurately identify what the resource is. The precise identification of resources prevents confusion, like mistaking Anakin Skywalker for Sebastian Shaw or Hayden Christensen, or confusing the original trilogy with the One-Man "Star Wars" Trilogy.
RDF achieves this by utilizing triples, expressed as XML tags, to represent this information in the form of a graph. These triples are composed of a subject, property, and object, much like the structure of a sentence's subject, verb, and direct object. (Some interpretations refer to them as the subject, predicate, and object.) RDF is already present on the Web, for instance, as part of the RSS feed generation process.
At this stage, the computer recognizes that the sentence contains two objects and that a relationship exists between them. However, it still lacks an understanding of the objects themselves and how they are connected. We'll explore the tool responsible for adding this layer of meaning next.
Knowing What's What: URIs
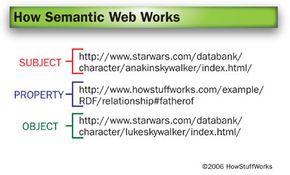 A URI provides a computer with a precise reference point for each element in the triple, eliminating the need for interpretation and minimizing the potential for confusion.
A URI provides a computer with a precise reference point for each element in the triple, eliminating the need for interpretation and minimizing the potential for confusion.Although XML and RDF offer a foundational framework, a computer still requires a clear and precise method for understanding what or who these resources are. To accomplish this, RDF employs uniform resource identifiers (URIs) to guide the computer to a document or object that represents the resource. One of the most common forms of URI is the uniform resource locator (URL), typically starting with http://. A URI can refer to anything on the Web, as well as non-web objects, such as devices in smart homes. Other examples of URIs include mailto, ftp, and telnet addresses.
For this illustration, we’ll use the official Star Wars website pages for the characters as their respective URIs.
At this point, the computer understands what the subject and object are—Anakin Skywalker corresponds to the first URI, and Luke Skywalker to the second. However, you’ll notice that the middle URI in this triple—the one for the property—does not point to the Star Wars website. Instead, it leads to a fictional document on the Mytour server. If this page truly existed, it would be our XML namespace.
In contrast to HTML, which utilizes predefined tags like <b> for bold and <u> for underline, XML lacks standard tags. This flexibility is beneficial because it allows developers to create custom tags for specific tasks. However, it also means that browsers don't automatically recognize what the tags signify. An XML namespace essentially acts as a guide, informing applications of the meaning behind the tags in another document. The XML document creator introduces the namespace at the start of the document using a specific line of code. For example, our namespace declaration would appear like this:
<rdf:RDF xmlns:hsw=https://www.Mytour.com/example/RDF/relationship#>
This line of code tells the computer, "Any tag starting with 'hsw' should refer to the vocabulary defined in this document. If you encounter a tag that begins with 'hsw', you can refer to this document for its meaning." This approach allows individuals to create custom XML tags for their documents without causing conflicts with other XML documents across the Web.
XML and RDF serve as the 'official language' of the Semantic Web, but by themselves, they don't offer everything needed to make the entire Web comprehensible to a computer. Let's explore some additional layers that play a role in this process.
XML and RDF form the backbone of the Semantic Web. They provide a framework for computers to search for information and define relationships between resources. Applications can also combine graphs that utilize the same URIs. For example, an application could combine the graph above with another one detailing the relationship between Anakin Skywalker and Darth Vader. In doing so, it could infer that Vader is Luke's father.
Languages and Vocabularies:RDFS, OWL and SKOS
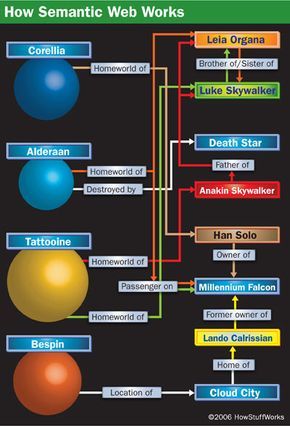 This is just a glimpse of the myriad resources and connections that could be represented in a Star Wars ontology. While a human can figure these out by watching the films and browsing the Web, a computer requires a well-defined structure to understand it all.
This is just a glimpse of the myriad resources and connections that could be represented in a Star Wars ontology. While a human can figure these out by watching the films and browsing the Web, a computer requires a well-defined structure to understand it all.A significant challenge for the Semantic Web is that computers lack the vocabulary that humans naturally develop. You've been immersed in language your entire life, so it’s likely easy for you to understand connections between various words and concepts, and to derive meanings from context. Unfortunately, simply giving a computer a dictionary, almanac, and a collection of encyclopedias won’t allow it to learn autonomously. For a computer to grasp what words mean and how they relate, it must have documents that define the words, along with logic to establish the connections between them.
In the realm of the Semantic Web, this knowledge is provided by schemata and ontologies. These are two closely linked tools that aid computers in interpreting human language. An ontology represents a vocabulary that outlines objects and their interrelationships, while a schema is a way of organizing that information. Similar to RDF tags, schemata and ontologies are embedded within documents as metadata, with the document creator declaring which ontologies are used at the outset.
The Semantic Web utilizes schema and ontology tools such as:
- RDF Vocabulary Description Language schema (RDFS) - RDFS enhances resources by adding classes, subclasses, and properties, establishing a fundamental language framework. For example, Dagobah is classified as a subclass of the planet class, and a property of Dagobah could be swampy.
- Simple Knowledge Organization System (SKOS) - SKOS categorizes resources as either broader or narrower, assigns preferred and alternate labels, and facilitates the transfer of thesauri and glossaries to the Web. For instance, in a Star Wars glossary, a narrower term for Sith Lord could be Darth Sidious, while a broader term might be villain. Similarly, alternate labels for Han Solo could include nerf herder and laser brain.
- Web Ontology Language (OWL) - OWL, the most sophisticated layer, formalizes ontologies, describes relationships between classes, and applies logic to draw conclusions. It can also create new classes from existing data. OWL is available in three complexity levels: Lite, Description Language (DL), and Full.
The challenge with ontologies lies in their complexity. They are not only difficult to create but also challenging to implement and maintain. Depending on the scope, ontologies can become vast, defining a wide array of concepts and relationships. Some developers prefer focusing on logic and rules instead of ontologies due to these challenges. Disagreements on how these rules should be utilized could be a potential stumbling block for the Semantic Web.
Now, let's bring everything together by revisiting our initial example: those 'Star Wars Trilogy' DVDs.
One of the Semantic Web's long-term aspirations is to enable agents, software applications, and web applications to access and interact with metadata. A crucial component for achieving this is the simple protocol and RDF Query Language (SPARQL), which is still under development. The main purpose of SPARQL is to retrieve information from RDF graphs. It can search for data, refine results, and organize them. The advantage of the RDF framework is that queries can be very specific, yielding highly accurate results.
Bringing Everything Together
Revisiting our initial example, we discussed purchasing 'Star Wars' DVDs online. Here's how the Semantic Web could streamline the entire process:
- Each website would feature text and images for human readers, along with metadata (for computers) describing the DVDs available for purchase.
- The metadata, utilizing RDF triples and XML tags, would allow all DVD attributes (such as condition and price) to be machine-readable.
- When necessary, businesses would apply ontologies to provide the computer with the vocabulary needed to describe these items and their features. All the shopping sites could adopt the same ontologies, ensuring the metadata is in a shared language.
- Each DVD retailer would also implement the necessary security and encryption measures to safeguard customer information.
- Automated applications or agents would process all the metadata across various sites. These applications could cross-reference information, ensuring that the sources are accurate and reliable.
Naturally, the Web is vast, and integrating all this metadata into existing pages is an enormous task. We'll explore this challenge, along with some other obstacles facing the Semantic Web, next.
Just like any other web document, the Semantic Web demands security measures to protect data and transactions. Among the recommendations from the W3C for the Semantic Web are digital signatures, encryption, proofs, and trust. Proofs and trust pertain to the underlying logic of the Semantic Web and the capacity of applications to verify that data is accurate and consistent across the entire web ecosystem.
The Role of W3C in the Future of the Semantic Web

Similar to the World Wide Web, the Semantic Web operates on a decentralized structure — no single organization or agency controls its rules or content. Nevertheless, certain individuals and organizations have assumed leadership roles in shaping Semantic Web standards and protocols. Notably, the World Wide Web Consortium (W3C), led by Tim Berners-Lee, is one of the key players. While the W3C is not a research institution, universities, other entities, and the general public also contribute significantly to the development of the Semantic Web.
Several aspects of the World Wide Web have already adopted elements of the Semantic Web. These include RSS feeds, which utilize RDF, and the Friend-of-a-Friend (FOAF) project, which aims to create personal web pages that are machine-readable.
A large portion of the Semantic Web's practical use and functionality are still being developed, with significant challenges ahead. The decentralized nature of the Web gives developers the ability to design custom tags and ontologies that suit their specific needs. However, this flexibility could lead to inconsistencies, as different developers might use varying tags to describe the same concept, creating complications for machine comparison. An additional issue, known as the 'identity problem,' arises: does a URI represent a Web page, or does it represent the object or concept described by the page? For example, does 'http://www.starwars.com' refer to the 'Star Wars' films, or merely to the Web page itself?
There is disagreement among developers about whether the Semantic Web should focus more on rules or on ontologies. Critics contend that the project might be overly ambitious. Firstly, people don't naturally conceptualize information in the form of graphs like those used by RDF. Secondly, businesses and existing websites are unlikely to allocate the time and resources required to add the necessary metadata. While future software might offer tools to add metadata when creating new documents, such tools may still fall short of making the Semantic Web feasible on a large scale.