
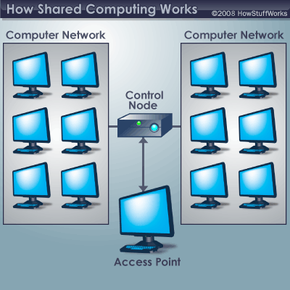
 In a distributed computing system, or a shared computing network, users can harness the combined processing capabilities of a network of computers.
Mytour
In a distributed computing system, or a shared computing network, users can harness the combined processing capabilities of a network of computers.
MytourFor highly complex computational problems, a single computer might require an extensive amount of time to solve—sometimes millions of days. Even supercomputers have their limits. Fortunately, distributed computing systems can be utilized to tackle these difficult computational challenges with efficiency.
Picture yourself tasked with pushing a massive car up a steep incline. You're allowed to enlist help from people not engaged in any other activities. You have two options: search for one person large and strong enough to complete the task alone or assemble several ordinary-sized individuals to work together. Most of the time, gathering a group of average individuals will be the easier choice. Surprisingly, this same concept is used in distributed computing systems.
Distributed computing offers a cost-effective solution to high-performance computing. Unlike high-performance computing, which relies on supercomputers, distributed computing connects multiple computers in a network. It's more flexible and benefits from resource pooling.
A distributed computing system is essentially a network of computers collaborating to complete a particular task. Each computer contributes part of its processing power—and sometimes additional resources—to help accomplish a shared objective. By linking thousands of computers, a distributed computing system can match or even exceed the power of a supercomputer.
In most cases, your computer isn't fully utilizing its processing capacity. There are times when your computer is turned on but you're not actively using it. A distributed computing system, or shared computing network, taps into these unused resources.
Shared computing systems excel in solving certain complex problems, but they have their limitations. They can be challenging to design and manage. Although many computer scientists are striving to standardize these systems, many still depend on specialized hardware, software, and architecture.
What components make up a typical distributed computing system? Continue reading to discover more.
Distributed Systems
In a conventional high-performance computing system, all computers are of the same model and operate under a single operating system. Typically, each application running on the system has its own dedicated server. The network often relies on hardwired connections, where all components communicate through various hubs, creating an efficient and streamlined system.
A distributed computing system can be just as efficient, though it may not have the same level of elegance. The system's capabilities are mainly determined by the software used to connect the computers. With the appropriate software, a distributed system can function across different types of computers with various operating systems. Network connections may occur through hardwired networks, local area networks (LANs), wireless area networks (WANs), or the Internet. The key benefit of distributed systems over traditional HPC systems is their flexibility to scale. Anyone with a computer capable of running the necessary software can contribute to the system.
The system's software is what enables it to tap into the unused processing power of each computer. Every computer in the system must have this software installed to participate. While there is no universal shared computing software kit, most software should be able to perform the following tasks:
- Communicate with the system's administrative server to request a segment of data
- Monitor the host computer's CPU usage and utilize its processing power whenever it's available
- Return processed data to the administrative server in exchange for new data
Distributed computing is most effective for solving large computational problems that can be divided into smaller, manageable parts. When these problems are particularly easy to break down, they are referred to as embarrassingly parallel problems.
For smaller computational tasks or those that are difficult to divide, shared computing systems are less practical. The primary advantage of these systems is their ability to accelerate complex calculations, but they do not necessarily speed up simple computations across the network.
What are the components that make up a distributed computing system? Continue reading to explore further.
Distributed computing systems are often called CPU-scavenging, cycle-scavenging, or cycle stealing because they utilize the unused processing power of many computers. Each term refers to how these systems tap into the CPUs of the computers connected to the network.
Distributed Computing Architecture
Unlike grid computing systems, which theoretically can have as many network interface points as there are users, a distributed computing system typically has only a few control points. This is because most shared computing systems are designed for specific tasks rather than serving as general utilities.
It helps to envision a typical shared computing system as consisting of a front end and a back end. The front end includes all the computers that contribute their CPU resources to the project. The back end consists of the computers and servers that manage the entire project, break down the main task into smaller components, communicate with the front-end computers, and store the data sent by the front-end systems after analysis.
In general, the responsibility of splitting the computational task into smaller parts falls on a program running on a back-end computer, usually a server. This computer uses specialized software to break the task into smaller pieces that are easier for average computer systems to handle. When contacted by the companion software on the front-end computer, the server sends data over the network for analysis. Once the analysis is complete, the server directs the results to the appropriate database.
The system's administrators typically use another computer to piece together the completed analyses. The ultimate aim is to solve a large problem by addressing it in smaller, manageable pieces. Often, the system's administrators will publish the results for the benefit of others.
If this description of the architecture seems somewhat vague, it's because there isn't a single standardized way to create and manage a distributed computing system. Each system has its own unique software and architecture. In most cases, a programmer tailors the software to the specific objectives of the system. While two different shared computing systems may operate similarly in broad terms, their details can differ significantly upon closer inspection.
What are some applications of distributed computing, and why is specialized software necessary? Read on in the next section to discover more.
Some distributed computing systems utilize virtual servers. To create virtual servers, an engineer installs specialized software on a single physical server. This software partitions the server into multiple distinct platforms, each capable of running an independent operating system. Why do this? Much like how an average computer owner rarely uses all of their computer's processing power, it’s uncommon for a server to operate at full capacity. By employing virtual servers, a single physical server can function closer to its full potential, minimizing the need for extra hardware.
Distributed Computing Applications
 Scientists are leveraging distributed computing systems to tackle intricate computational problems.
James Steidl/iStockphoto
Scientists are leveraging distributed computing systems to tackle intricate computational problems.
James Steidl/iStockphotoThere are numerous active distributed computing system projects, each with its own networks and computational tasks. Some of these networks overlap, meaning users can participate in more than one network, though this leads to projects having to share idle resources. As a result, each task may take a bit longer to complete.
One example of a shared computing system is the Grid Laboratory of Wisconsin (GLOW). The University of Wisconsin-Madison utilizes GLOW for various projects, which distinguishes it from most shared computing systems. One project focuses on studying the human genome, while another uses GLOW's resources for cancer treatment research. Unlike other distributed computing systems dedicated to a single task, GLOW supports multiple projects simultaneously.
The software that enables GLOW is called Condor. Condor's role is to locate idle processors within the GLOW network and allocate them to different projects. When a project is inactive, Condor borrows its resources for other projects. However, if an inactive project resumes activity, Condor will return its resources to that project.
Other shared computing systems include:
- SETI@home: A project dedicated to analyzing data from radio telescopes in the search for intelligent extraterrestrial life.
- Africa@home: This project focuses on using computing power for research aimed at improving the quality of life in Africa, especially in malaria control efforts.
- Proteins@home, Predictor@home, Rosetta@home, and Folding@home: These projects focus on studying proteins in various contexts.
- Einstein@home, Cosmology@home, Milkyway@home, and Orbit@home: These projects analyze astronomical data.
Other projects focus on diverse topics, from the physics of fluid dynamics to simulating nanotechnology environments.
While distributed computing systems can offer great benefits, are there any risks involved? Keep reading if you're not already worried.
Concerns About Distributed Computing
Whenever a system grants one computer access to another's resources, safety and privacy concerns inevitably arise. How can users be sure that administrators won't spy on a specific computer? If the administrators can tap into CPU power, does that mean they can access files or sensitive data as well?
The straightforward answer to these concerns is that it largely depends on the software that each participating computer installs to connect to the system. The capabilities of a shared computing system are limited to what that software allows. In most cases, the software prevents anyone from directly accessing the content of the host computer. The process is fully automated, and only the CPU's power is utilized.
However, there are exceptions. A zombie computer system, also known as a botnet, is a prime example of a malicious shared computing network. Led by a hacker, this type of system exploits innocent computer owners. The victim must first install a specific software, often disguised as harmless, which allows the hacker to gain control. Once installed, the hacker can use the computer for malicious purposes, such as launching a direct denial of service (DDoS) attack or distributing large volumes of spam. A botnet can involve hundreds or thousands of computers, with the victims often unaware of the operation.
Distributed computing systems must also prepare for situations where a computer goes offline or is otherwise unavailable for a prolonged period. Most systems have protocols in place to ensure continuity. Each task is given a time limit, and if the participant's computer fails to complete the task within that time frame, the system's control server will cancel the task and reassign it to another available machine.
One major criticism of shared computing systems is that while they effectively use idle processors, they also contribute to increased power consumption and heat generation. As more processing power is utilized, the demand for electricity grows. Some administrators encourage participants to leave their computers on all the time to ensure constant access to the network's resources. This approach can sometimes clash with green initiatives, which prioritize energy conservation.
A key drawback of distributed computing systems is their limited scope. While they consolidate processing power, they don't tap into other valuable resources like storage. As a result, many organizations are exploring the use of grid computing systems, which leverage a broader range of resources and support a wider array of applications that can benefit from networked resources.
A distributed computing system can be considered a limited form of grid computing. In a distributed system, tasks are divided into chunks and distributed across a network of computers, utilizing available CPU power. A grid computing system, however, shares a variety of resources such as processing power, memory, and storage space across the network. Typically, a shared computing system is built around a specific goal, and once that objective is completed, the system is no longer necessary. On the other hand, grid computing systems are designed to be versatile and organizationally oriented, meaning they serve as ongoing resources for corporations and organizations rather than being dedicated to a single task.