
Các lỗi tự động sửa của Excel đang làm đau đầu nghiên cứu gen
Tự động sửa, hoặc văn bản dự đoán, là một tính năng phổ biến của nhiều công cụ công nghệ hiện đại, từ tìm kiếm trên internet đến ứng dụng nhắn tin và xử lý văn bản. Tự động sửa có thể là một phúc lành, nhưng khi thuật toán phạm lỗi, nó có thể thay đổi thông điệp một cách đậm nét và đôi khi là hài hước.
Nghiên cứu của chúng tôi cho thấy các lỗi tự động sửa, đặc biệt là trong các bảng tính Excel, cũng có thể làm rối tên gen trong nghiên cứu di truyền. Chúng tôi đã khảo sát hơn 10,000 bài báo có danh sách gen trên Excel được xuất bản từ 2014 đến 2020 và phát hiện hơn 30% chứa ít nhất một tên gen bị lẫn lộn do tự động sửa.
Nghiên cứu này làm tiếp theo sau nghiên cứu của chúng tôi vào năm 2016, phát hiện khoảng 20% bài báo chứa những lỗi này, vì vậy vấn đề có thể đang trở nên tồi tệ hơn. Chúng tôi tin rằng bài học cho các nhà nghiên cứu là rõ ràng: đã đến lúc dừng việc sử dụng Excel và học cách sử dụng phần mềm mạnh mẽ hơn.
Excel đưa ra những giả định không chính xác
Các bảng tính áp dụng văn bản dự đoán để đoán xem người dùng muốn loại dữ liệu nào. Nếu bạn nhập một số điện thoại bắt đầu bằng số không, nó sẽ nhận diện nó là một giá trị số và loại bỏ số không dẫn đầu. Nếu bạn nhập “=8/2”, kết quả sẽ xuất hiện là “4”, nhưng nếu bạn nhập “8/2”, nó sẽ được nhận diện là một ngày tháng.
Với dữ liệu khoa học, hành động đơn giản như mở một tệp trong Excel với các thiết lập mặc định có thể làm hỏng dữ liệu do tự động sửa. Có thể tránh tự động sửa không mong muốn nếu ô đã được định dạng trước khi dán hoặc nhập dữ liệu, nhưng điều này và những mẹo vệ sinh dữ liệu khác không phổ biến.
Trong di truyền học, từ năm 2004 đã nhận thức được rằng Excel có thể chuyển đổi khoảng 30 tên gen và protein con người thành ngày tháng. Những tên này là như MARCH1, SEPT1, Oct-4, jun, và nhiều hơn nữa.
Nhiều năm trước, chúng tôi phát hiện lỗi này trong các tệp dữ liệu bổ sung đính kèm vào một bài báo của một tạp chí uy tín và trở nên quan tâm đến việc lỗi này phổ biến như thế nào. Bài báo của chúng tôi năm 2016 cho thấy vấn đề này ảnh hưởng đến các tạp chí trung và cao cấp với tỷ lệ tương đương. Điều này cho thấy với chúng tôi rằng các nhà nghiên cứu và tạp chí lớn phần lớn không nhận thức được vấn đề tự động sửa và cách tránh nó.
Do báo cáo của chúng tôi năm 2016, Hội đồng Tên Gen Người, cơ quan chính thức chịu trách nhiệm đặt tên cho các gen người, đã đổi tên các gen gây vấn đề nhất. MARCH1 và SEPT1 đã được đổi thành MARCHF1 và SEPTIN1 tương ứng, và những gen khác cũng có những thay đổi tương tự.
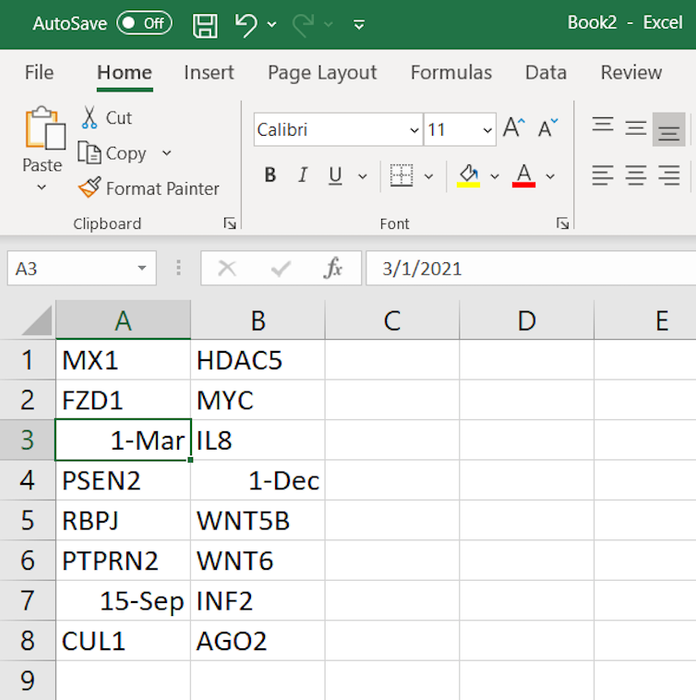 An example list of gene names in Excel.
An example list of gene names in Excel.Vấn đề vẫn còn tồn tại
Earlier this year we repeated our analysis. This time we expanded it to cover a wider selection of open access journals, anticipating researchers and journals would be taking steps to prevent such errors appearing in their supplementary data files.
Chúng tôi bất ngờ khi phát hiện trong giai đoạn từ 2014 đến 2020 có 3,436 bài báo, khoảng 31% trong số mẫu của chúng tôi, chứa lỗi tên gen. Dường như vấn đề không giảm bớt mà thực tế đang trở nên tồi tệ hơn.
Những lỗi nhỏ cũng quan trọng
Một số người cho rằng những lỗi này thực sự không quan trọng, vì khoảng 30 gen chỉ là một phần nhỏ trong số khoảng 44,000 gen trong toàn bộ gen con người, và những lỗi này không thể làm đảo ngược kết luận của bất kỳ nghiên cứu genôm cụ thể nào.
Bất kỳ người nào tái sử dụng những tệp dữ liệu bổ sung này sẽ thấy bộ gen nhỏ này bị thiếu hoặc bị hỏng. Điều này có thể làm phiền nếu dự án nghiên cứu của bạn xem xét gia đình gen SEPT, nhưng nó chỉ là một trong rất nhiều gia đình gen tồn tại.
Chúng tôi tin rằng những lỗi này quan trọng vì chúng đặt ra câu hỏi về cách những lỗi này có thể lẻn vào các xuất bản khoa học. Nếu lỗi tự động sửa tên gen có thể đi qua đánh giá từ đồng nghiệp mà không được phát hiện vào các tệp dữ liệu đã xuất bản, thì có thể còn những lỗi khác nào đang ẩn nấp giữa hàng nghìn điểm dữ liệu khác?
Thảm họa bảng tính
Trong lĩnh vực kinh doanh và tài chính, có nhiều ví dụ về những lỗi bảng tính dẫn đến những tổn thất đắt đỏ và đau đớn.
Năm 2012, JP Morgan tuyên bố mất hơn 6 tỷ USD do một loạt những sai lầm giao dịch được tạo ra nhờ lỗi công thức trong các bảng tính mô phỏng của họ. Phân tích hàng nghìn bảng tính tại Enron Corporation, trước khi sụp đổ ngoạn mục vào năm 2001, cho thấy gần một phần tư chứa lỗi.
Một bài viết nổi tiếng của các nhà kinh tế Harvard Carmen Reinhart và Kenneth Rogoff được sử dụng để bào chữa các biện pháp cắt giảm sau cuộc khủng hoảng tài chính toàn cầu, nhưng phân tích này chứa một lỗi Excel quan trọng dẫn đến việc bỏ qua năm trong số 20 quốc gia trong mô hình của họ.
Chính năm ngoái, một lỗi bảng tính tại Cơ quan Y tế Công cộng Anh dẫn đến việc mất dữ liệu tương ứng với khoảng 15,000 ca COVID-19 dương tính. Điều này làm ảnh hưởng đến công cuộc theo dõi tiếp xúc trong tám ngày trong khi số lượng ca nhanh chóng tăng lên. Trong bối cảnh chăm sóc sức khỏe, lỗi nhập dữ liệu lâm sàng vào bảng tính có thể lên đến 5%, trong khi một nghiên cứu khác về bảng tính quản lý bệnh viện chỉ ra rằng 11 trong số 12 chứa những lỗi nghiêm trọng.
Trong nghiên cứu sinh học, một sai lầm trong việc chuẩn bị một tờ mẫu dẫn đến việc toàn bộ bộ nhãn mẫu bị di chuyển một vị trí và thay đổi hoàn toàn kết quả phân tích gen. Kết quả này quan trọng vì nó được sử dụng để bào chữa các loại thuốc mà bệnh nhân sẽ nhận trong cuộc thử nghiệm lâm sàng sau này. Điều này có thể là một trường hợp cụ thể, nhưng chúng ta thực sự không biết những lỗi như vậy có phổ biến trong nghiên cứu hay không do thiếu các nghiên cứu phát hiện lỗi có hệ thống.
Có các công cụ tốt hơn hiện có
Bảng tính là một công cụ linh hoạt và hữu ích, nhưng nó cũng có nhược điểm của mình. Doanh nghiệp đã chuyển sang phần mềm kế toán chuyên dụng, và không ai trong lĩnh vực Công nghệ Thông tin sẽ sử dụng bảng tính để xử lý dữ liệu khi hệ thống cơ sở dữ liệu như SQL mạnh mẽ và linh hoạt hơn nhiều.
Tuy nhiên, việc sử dụng tệp Excel để chia sẻ dữ liệu bổ sung trực tuyến vẫn phổ biến trong cộng đồng các nhà khoa học. Nhưng khi khoa học trở nên phức tạp về dữ liệu và nhược điểm của Excel trở nên rõ ràng hơn, có lẽ là lúc các nhà nghiên cứu nên từ chối bảng tính.
Trong genôm học và các ngành khoa học khác có lượng dữ liệu lớn, các ngôn ngữ máy tính được viết kịch bản như Python và R rõ ràng là ưu việt hơn so với bảng tính. Chúng mang lại những lợi ích bao gồm kỹ thuật phân tích cải tiến, khả năng tái tạo, khả năng kiểm tra và quản lý tốt hơn phiên bản mã và đóng góp từ các cá nhân khác nhau. Mặc dù có thể khó học ở giai đoạn đầu, nhưng những lợi ích mang lại cho khoa học tốt hơn đáng giá trong thời gian dài.
Excel phù hợp với việc nhập dữ liệu và phân tích nhẹ. Microsoft nói rằng cài đặt mặc định của Excel được thiết kế để đáp ứng nhu cầu của phần lớn người dùng, phần lớn thời gian.
Rõ ràng, khoa học genôm không đại diện cho một trường hợp sử dụng phổ biến. Bất kỳ bộ dữ liệu nào lớn hơn 100 hàng đều không thích hợp cho bảng tính.

Bài viết của Mark Ziemann, Giảng viên ngành Công nghệ Sinh học và Tin học Sinh học, Đại học Deakin và Mandhri Abeysooriya, , Đại học Deakin
Bài viết này được tái bản từ The Conversation dưới giấy phép Creative Commons. Đọc bài viết gốc.