

Giờ đây có nhiều phương pháp để tạo hình ảnh từ các câu lệnh của bạn. Midjourney thu phí hàng tháng để gửi câu lệnh tạo hình ảnh trực tiếp qua Discord. Sử dụng Bing Chat với sức mạnh của DALL-E trên máy chủ Azure để tạo ra hình ảnh cơ bản. Firefly của Adobe tích hợp trong Photoshop nhưng đều yêu cầu thanh toán. Trong khi Bing Chat miễn phí nhưng chất lượng hình ảnh thấp và không có nhiều tùy chỉnh câu lệnh.
Bên cạnh đó, có một giải pháp hoàn toàn miễn phí là Stable Diffusion WebUI do AUTOMATIC1111 trên Github phát triển. Sử dụng mô hình ngôn ngữ từ Stability AI, bạn có thể sử dụng sức mạnh của máy tính cá nhân để tạo ra hình ảnh theo ý muốn mà không tốn phí.
Sử dụng Stable Diffusion trên macOS
Bây giờ chúng ta có hai lựa chọn, sử dụng Stable Diffusion trên macOS hoặc trên máy tính Windows. Trên macOS, việc này rất đơn giản với ứng dụng có sẵn là DiffusionBee. Chỉ cần tải về từ trang web của nhà phát triển và cài đặt là xong.
Tuy nhiên, Diffusion Bee chỉ hỗ trợ chip Apple Silicon, không tương thích với Mac sử dụng chip Intel. Điều kiện thứ hai, máy Mac phải chạy macOS Monterey trở lên để cài đặt DiffusionBee.
https://diffusionbee.com/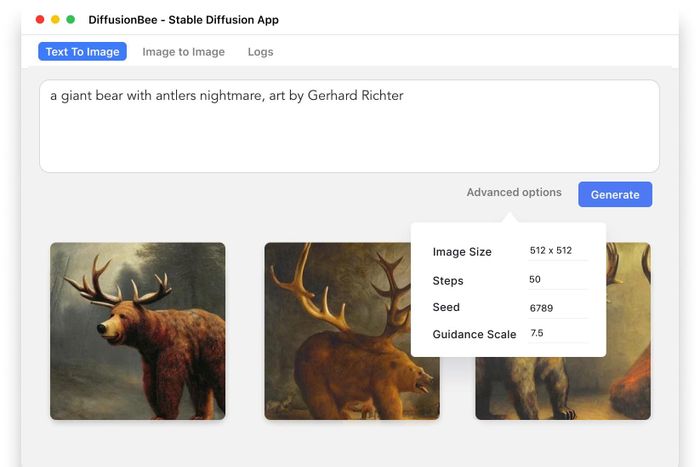 Chú ý đến các Tùy chọn Nâng cao trong phần mềm. Hiểu rõ những thông số này sẽ giúp bạn tạo ra những tấm hình ưng ý hơn:
Chú ý đến các Tùy chọn Nâng cao trong phần mềm. Hiểu rõ những thông số này sẽ giúp bạn tạo ra những tấm hình ưng ý hơn:- Kích thước Ảnh: Kích thước của hình tạo ra. DiffusionBee được tối ưu hóa để tạo ra hình ảnh ở kích thước 512x512 pixel là tốt nhất.
- Bước: Số bước trong quá trình nội suy hình ảnh. Số bước càng cao thì hình ảnh càng chi tiết, nhưng cũng tốn thêm thời gian. Số bước thấp sẽ tạo ra hình nhanh, nhưng chất lượng thấp.
- Seed: Tham số dùng để tạo hình. Nếu bạn thấy hình trước đó ưng ý, hãy giữ nguyên giá trị Seed để tạo ra hình tương tự. Nếu không, để ngẫu nhiên để tạo ra hình khác nhau.
- Quy mô Hướng dẫn: Giá trị từ 1 đến 30. Số càng cao thì AI sẽ tuân thủ nghiêm ngặt hơn từ khóa của bạn. Số thấp sẽ tạo ra những tác phẩm “sáng tạo” hơn.
Hướng dẫn cài đặt Stable Diffusion WebUI của AUTOMATIC1111 trên Windows
Trên macOS, mọi thứ khá dễ dàng, nhưng lại ít điều khiển hơn trong quá trình chỉnh sửa hình ảnh. Trong khi đó, trên Windows, quá trình cài đặt và cấu hình đòi hỏi phức tạp hơn một chút so với macOS, nhưng đổi lại, người dùng có nhiều sự linh hoạt hơn khi sử dụng Stable Diffusion để tạo ra hình ảnh bằng trí tuệ nhân tạo. Đầu tiên, hãy tìm hiểu về yêu cầu cấu hình để cài đặt Stable Diffusion WebUI:- Yêu cầu hệ điều hành Windows 10 trở lên.
- Card đồ họa của Nvidia là bắt buộc, vì Stable Diffusion WebUI chỉ hỗ trợ xử lý dựa trên tập lệnh và nhân CUDA trên GPU của Nvidia. Card đồ họa cần có VRAM tối thiểu 4GB. Trong quá trình nội suy, card đồ họa với VRAM lớn hơn sẽ cho kết quả tốt hơn. Tuy nhiên, không phải ai cũng có card RTX 3090 hoặc 4090 để thử nghiệm cùng trí tuệ nhân tạo.
- Còn các giải pháp khác như AUTOMATIC1111, OnnxDiffuserUI, hỗ trợ card đồ họa Radeon của AMD hoặc có thể tùy chỉnh AUTOMATIC1111 để hỗ trợ card AMD. Phần này sẽ được trình bày trong một bài viết khác, vì cách “vượt rào” tương đối phức tạp.
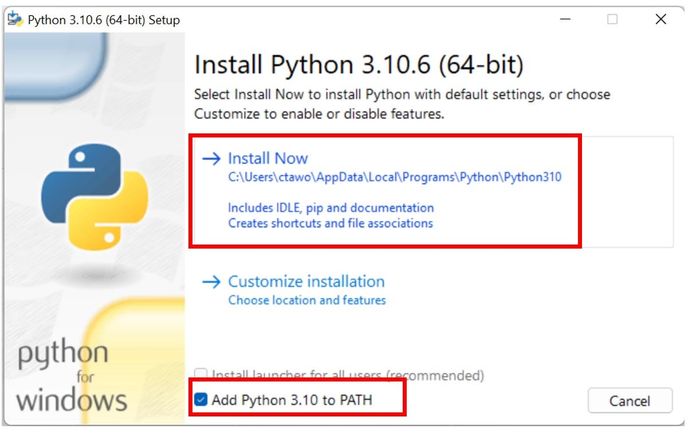
- Bước 1: Tải Python phiên bản mới nhất cho máy tính Windows. Truy cập trang web của Python: https://www.python.org/downloads/release/python-31010/, sau đó chọn phiên bản cài đặt dành cho Windows Installer (64-bit), tải về máy tính và tiến hành cài đặt. Lưu ý: Khi cài đặt Python, hãy đảm bảo tick vào ô 'Add Python 3.10 to PATH'.
- Bước 2: Tải và cài đặt Git for Windows tại đây: https://git-scm.com/download/win. Để cài đặt AUTOMATIC1111 và cập nhật, Git là điều cần thiết vì nó là công cụ quản lý mã nguồn.
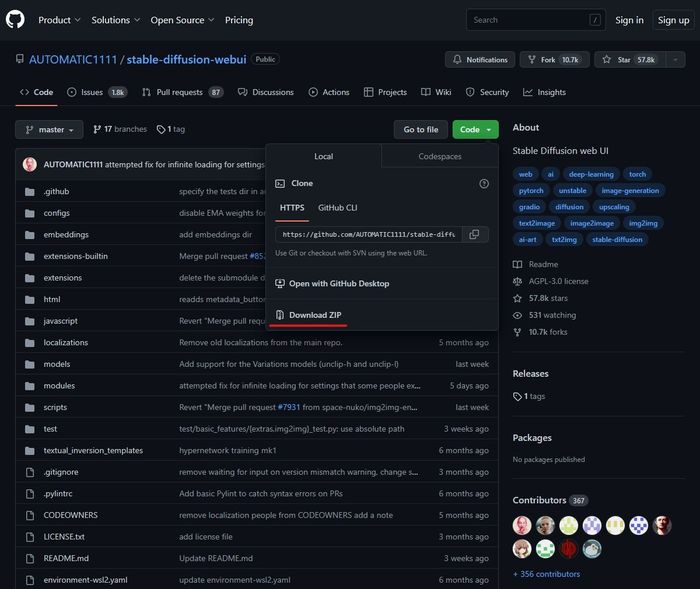
- Bước 3: Sau khi đã cài đặt Python và Git, truy cập vào https://github.com/AUTOMATIC1111/stable-diffusion-webui, nhấn vào nút Code, sau đó chọn Download ZIP để tải WebUI về máy tính.
 Hugging FaceCivitai
Hugging FaceCivitai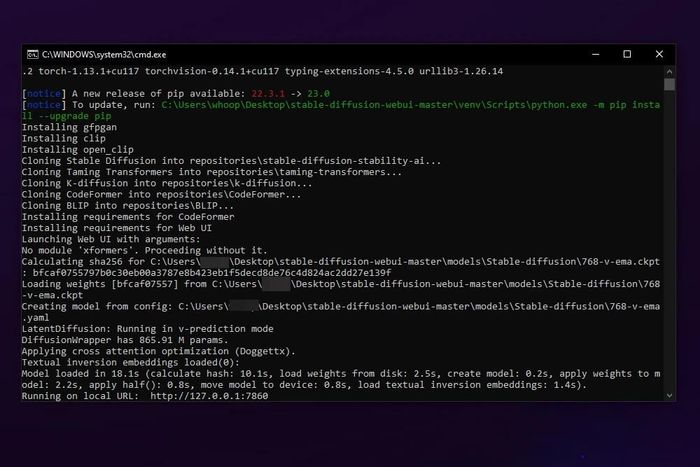 Do là lần đầu tiên khởi chạy, phần mềm sẽ tự động tải xuống các thành phần cần thiết để khởi chạy WebUI, bao gồm cả các mô hình nâng cấp hình ảnh và các plugin cần thiết. Quá trình này có thể mất từ 5 đến 15 phút tùy thuộc vào tốc độ internet của bạn. Chỉ cần đợi cho đến khi cửa sổ cmd hiển thị dòng thông báo “Running on local IRL: http://127.0.0.1:7860” là thành công.
Do là lần đầu tiên khởi chạy, phần mềm sẽ tự động tải xuống các thành phần cần thiết để khởi chạy WebUI, bao gồm cả các mô hình nâng cấp hình ảnh và các plugin cần thiết. Quá trình này có thể mất từ 5 đến 15 phút tùy thuộc vào tốc độ internet của bạn. Chỉ cần đợi cho đến khi cửa sổ cmd hiển thị dòng thông báo “Running on local IRL: http://127.0.0.1:7860” là thành công.- Bước 8: Mở trình duyệt và nhập địa chỉ http://127.0.0.1:7860. Giao diện WebUI sẽ xuất hiện, sẵn sàng cho bạn bắt đầu tạo hình ảnh từ thuật toán AI:
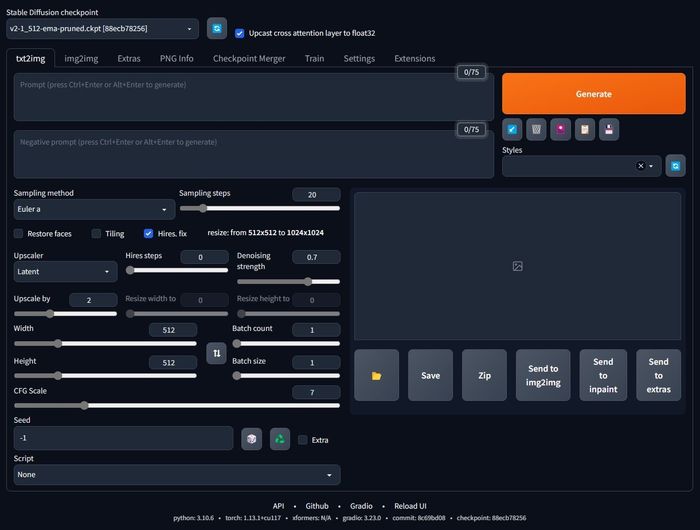
Làm thế nào để sử dụng mô hình AI để tạo ảnh?
Dường như giao diện WebUI có thể khiến bạn cảm thấy khá lạ lẫm so với DiffusionBee trên macOS mà tôi đã chia sẻ trước đó. Tuy nhiên, khi bạn đã hiểu rõ mọi chi tiết và tính năng của từng phần, bạn sẽ nhận ra rằng công cụ này mạnh mẽ và linh hoạt hơn nhiều so với DiffusionBee:- StableDiffusion checkpoint: Mô hình đã được huấn luyện để tạo hình ảnh dựa trên từ khóa.
- Prompt: Ô nhập từ khóa để thuật toán tạo hình ảnh.
- Negative prompt: Các từ khóa có thể tạo ra chi tiết hình ảnh không mong muốn, nhập các từ khóa này để thuật toán bỏ qua chúng trong quá trình nội suy hình ảnh.
- Sampling method: Phương pháp lấy mẫu trong quá trình nội suy. Mỗi phương pháp lấy mẫu phù hợp với một loại hình ảnh khác nhau. Có phương pháp phù hợp với DDIM, cũng như phương pháp phù hợp với DPM2 a. Lựa chọn phương pháp lấy mẫu phụ thuộc hoàn toàn vào thử nghiệm của bạn.
- Restore faces: Sử dụng thuật toán CodeFormer để điều chỉnh chi tiết của khuôn mặt để chúng trở nên tự nhiên hơn.
- Tiling: Tạo ra các hình ảnh lặp lại, rất hữu ích khi tạo ra các hoa văn và mẫu họa mới.
- Hires. fix: Sử dụng các thuật toán khác để tiếp tục nội suy, tăng độ phân giải của hình ảnh.
- Upscaler: Lựa chọn thuật toán để nâng cao độ phân giải của hình ảnh.
- Upscale by: Tỷ lệ tăng kích thước hình ảnh. Hãy tránh chọn quá cao để tránh tình trạng hết VRAM. Các hình ảnh lớn hơn có thể tạo ra ở tab Extra, tiết kiệm tài nguyên máy tính hơn so với việc tăng kích thước hình ảnh cùng lúc với quá trình nội suy của AI.
- Hires steps: Số bước nội suy được sử dụng để tăng độ phân giải và chi tiết của hình ảnh.
- Denoising strength: Mức độ can thiệp của thuật toán nâng cấp hình ảnh, áp dụng lên hình ảnh đã được tạo ra trước đó. Số càng nhỏ thì can thiệp càng ít.
- CFG Scale: Viết tắt của Classifier Free Guidance, tương tự như DiffusionBee, số càng nhỏ thì hình ảnh càng có tính sáng tạo.
- Seed: Tham số của thuật toán được sử dụng trong quá trình nội suy hình ảnh.
- Từ khóa nội suy: ((Darth Vader lái xe vespa trên đường phố mưa Tokyo)), phản chiếu trên mặt đất, biển quảng cáo neon, cyberpunk, đêm Tokyo, ánh sáng Rembrandt, thần thoại, bầu trời kịch tính, điện ảnh, ống kính fisheye, f1.8, siêu thực, siêu chi tiết, chân dung thực tế, đối lập cao
- Số liệu nội suy: Bước: 35, Sampler: DPM++ SDE Karras, CFG scale: 6, Seed: 786709107, Phục hồi khuôn mặt: CodeFormer, Kích thước: 768x512, Hash mô hình: 88ecb78256, Mô hình: v2-1_512-ema-pruned, Độ mờ: 0.2, Nâng cấp hiệu suất cao: 2, Bộ nâng cấp hiệu suất cao: R-ESRGAN 4x+
 Deliberate V2:
Deliberate V2: Illuminati Diffusion V1.0:
Illuminati Diffusion V1.0: Bộ máy Realism V1.0:
Bộ máy Realism V1.0: Mỗi mô hình hoạt động dựa trên cùng một tham số nội suy, nhưng việc điều chỉnh từ khóa, thay đổi tham số và lựa chọn mô hình ngôn ngữ cùng sampler nội suy cũng là một nghệ thuật để tạo ra những bức hình tốt nhất dựa trên Stable Diffusion.
Mỗi mô hình hoạt động dựa trên cùng một tham số nội suy, nhưng việc điều chỉnh từ khóa, thay đổi tham số và lựa chọn mô hình ngôn ngữ cùng sampler nội suy cũng là một nghệ thuật để tạo ra những bức hình tốt nhất dựa trên Stable Diffusion.Card đồ họa dưới 8GB VRAM có được không?
Yêu cầu của AUTOMATIC1111 Stable Diffusion WebUI là card đồ họa Nvidia phải có ít nhất 8GB VRAM để thực hiện quá trình nội suy. Tuy nhiên, điều này không có nghĩa là những người dùng có card đồ họa có bộ nhớ ít hơn sẽ không thể sử dụng Stable Diffusion.- Bước 1: Anh em vào thư mục gốc stable-diffusion-webui, tìm file có tên webui-user.bat.
- Bước 2: Chuột phải vào webui-user.bat và chọn Chỉnh sửa.
- Bước 3: Tìm dòng set COMMANDLINE_ARGS=, thay dòng này bằng set COMMANDLINE_ARGS=--xformers --medvram
- Bước 4: Lưu lại file webui-user.bat, sau đó khởi động WebUI bằng file này thay vì webui.bat.
Sửa lỗi NansException khi mô hình không tương thích với card đồ họa
Với checkpoint gốc của StabilityAI, v2-1_512-ema-pruned.ckpt, không có vấn đề gì xảy ra. Tuy nhiên, khi sử dụng các mô hình ngôn ngữ khác từ CivitAI chẳng hạn, anh em có thể gặp phải lỗi khi thực hiện tạo hình ảnh trong WebUI sau khi đưa mô hình và tệp cấu hình vào thư mục mô hình tổng hợp và khởi động lại WebUI. Lỗi này có thể được mô tả như sau: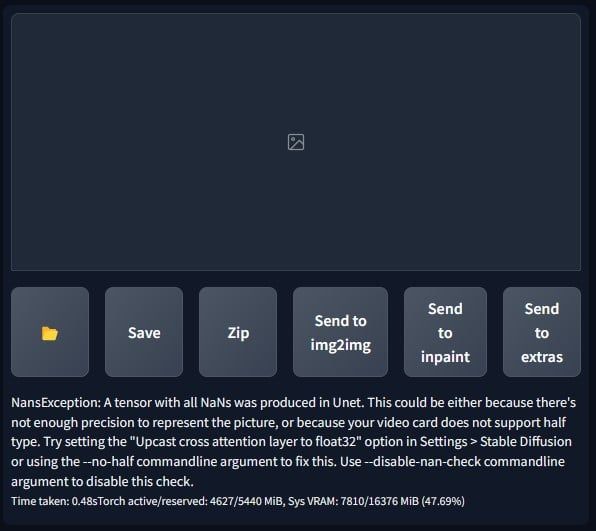 Lý do của lỗi này là card đồ họa không hỗ trợ xử lý half-type trong quá trình nội suy. Các card RTX 40 series dễ gặp phải lỗi này. Ngoài ra, cũng có trường hợp lỗi từ cơ sở dữ liệu của CivitAI gây ra, khiến cho việc tải model checkpoint mới từ trang web này gặp lỗi NansException.
Cách giải quyết như sau:
Lý do của lỗi này là card đồ họa không hỗ trợ xử lý half-type trong quá trình nội suy. Các card RTX 40 series dễ gặp phải lỗi này. Ngoài ra, cũng có trường hợp lỗi từ cơ sở dữ liệu của CivitAI gây ra, khiến cho việc tải model checkpoint mới từ trang web này gặp lỗi NansException.
Cách giải quyết như sau:- Bước 1: Tìm tệp webui-user.bat trong thư mục gốc stable-diffusion-webui, chuột phải và chọn Sửa.
- Bước 2: Tìm dòng set COMMANDLINE_ARGS, sau đó thêm --no-half-vae vào ngay sau dấu bằng, lưu lại file này.
- Bước 3: Khởi động WebUI bằng file webui-user.bat thay cho webui.bat như trên.
- Bước 4: Trong giao diện WebUI trên trình duyệt, vào tab Cài đặt, chọn mục Giao diện người dùng, ở dòng Danh sách cài đặt nhanh, dán sd_model_checkpoint, upcast_attn vào ô nhập liệu.
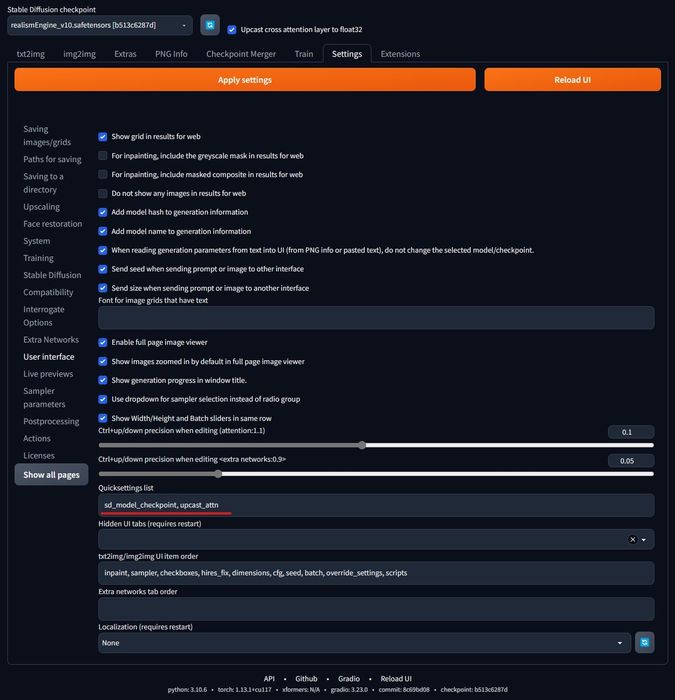
- Bước 5: Trong cùng mục Cài đặt, chọn mục Stable Diffusion, tick vào ô Chuyển lớp attention sang float32. Sau đó ấn nút Áp dụng cài đặt, rồi ấn nút Tải lại Giao diện người dùng, hai nút màu cam lớn trong hình ảnh:
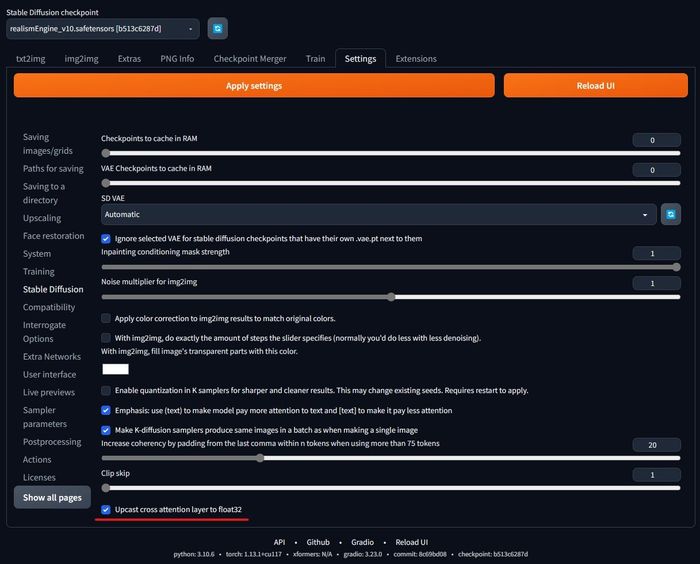 Chúc mọi người thành công, và đừng quên chia sẻ những tác phẩm sáng tạo được tạo ra nhờ AI Stable Diffusion trong phần bình luận nhé!
Chúc mọi người thành công, và đừng quên chia sẻ những tác phẩm sáng tạo được tạo ra nhờ AI Stable Diffusion trong phần bình luận nhé!