
Hướng dẫn cách tính phương sai sử dụng Python

Được xuất bản ban đầu trên Built In bởi Eric Kleppen.
Phương sai là một thống kê mạnh mẽ được sử dụng trong phân tích dữ liệu và máy học. Đây là một trong bốn chỉ số chính về biến động cùng với phạm vi, phạm vi nửa khoảng cách (IQR) và độ lệch chuẩn. Hiểu về phương sai quan trọng vì nó cung cấp thông tin về sự phân tán của dữ liệu và có thể được sử dụng để so sánh sự khác biệt trong các nhóm mẫu hoặc xác định các đặc điểm quan trọng của mô hình. Phương sai cũng được sử dụng trong máy học để hiểu các thay đổi trong hiệu suất mô hình do sử dụng các mẫu dữ liệu đào tạo khác nhau.
Việc tính toán phương sai rất đơn giản bằng Python. Trước khi đào sâu vào mã nguồn Python, tôi sẽ trình bày trước về phương sai là gì và cách bạn có thể tính toán nó. Đến cuối bài hướng dẫn này, bạn sẽ hiểu rõ hơn về tại sao phương sai là một thống kê quan trọng, cùng với một số phương pháp tính toán nó bằng Python.
Phương sai là gì?
Phương sai là một thống kê đo lường sự phân tán. Phương sai thấp cho biết giá trị thông thường và không biến động nhiều so với giá trị trung bình, trong khi phương sai cao cho biết giá trị có sự phân tán rộng từ giá trị trung bình. Bạn có thể sử dụng phương sai trên một bộ mẫu hoặc toàn bộ quần thể vì tính toán này liên quan đến tất cả các điểm dữ liệu trong bộ mẫu cho trước. Mặc dù phép tính này có chút khác biệt khi bạn xem xét một mẫu so với quần thể, bạn có thể tính toán phương sai như trung bình của bình phương của sự chênh lệch từ giá trị trung bình.
Bởi vì phương sai là một giá trị bình phương, việc giải thích nó có thể khó khăn hơn so với các độ đo biến động khác như độ lệch chuẩn. Tuy nhiên, việc xem xét phương sai có thể hữu ích; việc này có thể giúp bạn dễ dàng quyết định xem bạn nên sử dụng các kiểm định thống kê nào với dữ liệu của mình. Tùy thuộc vào kiểm định thống kê, sự không đồng đều về phương sai giữa các mẫu có thể làm nghiêng hoặc làm chệch kết quả.
Một trong những kiểm định thống kê phổ biến mà sử dụng phương sai là kiểm định phân tích phương sai (ANOVA). Kiểm định ANOVA được sử dụng để đánh giá xem các giá trị trung bình của các nhóm có khác biệt đáng kể hay không khi phân tích một biến độc lập phân loại và một biến phụ thuộc định lượng. Ví dụ, nếu bạn muốn phân tích xem việc sử dụng mạng xã hội có ảnh hưởng đến thời gian ngủ. Bạn có thể chia việc sử dụng mạng xã hội thành các danh mục như sử dụng ít, sử dụng trung bình và sử dụng nhiều, sau đó chạy kiểm định ANOVA để đánh giá xem có sự khác biệt thống kê giữa các giá trị trung bình hay không. Kiểm định có thể chỉ ra xem kết quả có được giải thích bởi sự khác biệt nhóm hay sự khác biệt cá nhân.
Làm thế nào để tính phương sai?
Việc tính toán phương sai cho một tập dữ liệu có thể khác nhau tùy thuộc vào việc tập đó là toàn bộ quần thể hay một mẫu của quần thể.
Công thức tính phương sai cho toàn bộ quần thể nhìn như sau:
σ² = ∑ (Xᵢ— μ)² / N
Một giải thích về công thức:
- σ² = phương sai của quần thể
- Σ = tổng của…
- Χᵢ = mỗi giá trị
- μ = giá trị trung bình của quần thể
- Ν = số lượng giá trị trong quần thể
- Sử dụng một ví dụ về dãy số, chúng ta sẽ đi qua quá trình tính toán từng bước.
Ví dụ về dãy số: 8, 6, 12, 3, 13, 9
Tìm giá trị trung bình của quần thể (μ):

Tính độ lệch từ giá trị trung bình bằng cách trừ giá trị trung bình từ mỗi giá trị.

Bình phương mỗi độ lệch để có được một số dương.

Tổng các giá trị bình phương.

Chia tổng bình phương cho N hoặc n-1.
Vì chúng ta đang làm việc với toàn bộ quần thể, nên chia cho N. Nếu chúng ta đang làm việc với một mẫu của quần thể, chúng ta sẽ chia cho n-1.
69.5/6 = 11.583
Đó là nó! Phương sai của quần thể chúng ta là 11.583.
Tại sao sử dụng n-1 khi tính phương sai của mẫu?
Việc áp dụng n-1 vào công thức được gọi là sửa lỗi của Bessel, được đặt theo tên Friedrich Bessel. Khi sử dụng mẫu, chúng ta cần tính phương sai ước lượng cho quần thể. Nếu chúng ta sử dụng N thay vì n-1 cho mẫu, ước lượng sẽ bị chệch, có thể đánh giá thấp phương sai của quần thể. Sử dụng n-1 sẽ làm cho ước lượng phương sai lớn hơn, đánh giá cao sự biến động trong mẫu, từ đó giảm thiểu sự chệch lệch.
Hãy tính lại phương sai giả định rằng các giá trị đến từ một mẫu:

Như chúng ta có thể thấy, phương sai lớn hơn!
Tính phương sai bằng Python
Bây giờ sau khi chúng ta đã tính toán bằng tay, chúng ta có thể thấy rằng việc hoàn thành nó cho một tập giá trị lớn sẽ rất phiền toái. May mắn thay, Python có thể dễ dàng xử lý tính toán cho dữ liệu rất lớn. Chúng ta sẽ khám phá hai phương pháp sử dụng Python:
- Viết chức năng tính toán phương sai của chúng ta
- Sử dụng chức năng tích hợp sẵn của Pandas
Viết một hàm tính phương sai
Khi chúng ta bắt đầu viết một hàm tính toán phương sai, hãy nhớ lại các bước chúng ta thực hiện khi tính toán bằng tay. Chúng ta muốn hàm này nhận vào hai tham số:
- population: một mảng các số
- is_sample: một Boolean để điều chỉnh tính toán tùy thuộc vào việc chúng ta đang làm việc với một mẫu hay toàn bộ quần thể
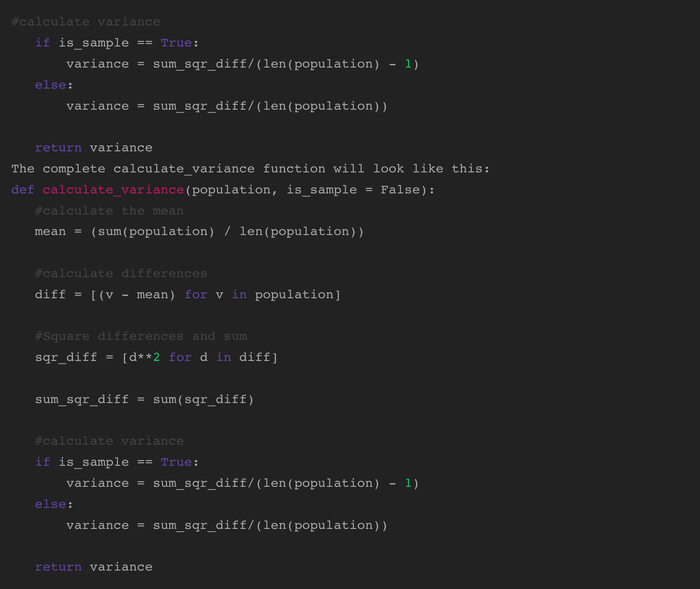
Bắt đầu bằng cách định nghĩa hàm nhận hai tham số.

Tiếp theo, thêm logic để tính giá trị trung bình của quần thể.

Sau khi tính toán giá trị trung bình, tìm sự chênh lệch từ giá trị trung bình cho mỗi giá trị. Bạn có thể thực hiện điều này trong một dòng sử dụng list comprehension.

Tiếp theo, bình phương sự chênh lệch và tổng chúng.

Cuối cùng, tính toán phương sai. Sử dụng câu lệnh If/Else, chúng ta có thể sử dụng tham số is_sample. Nếu is_sample là true, tính toán phương sai bằng (n-1). Nếu nó là false (giá trị mặc định), sử dụng N:
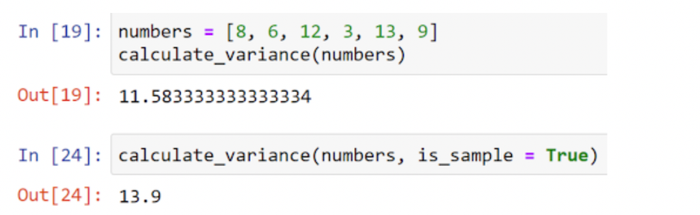
Chúng ta có thể kiểm thử tính toán bằng cách sử dụng dãy số chúng ta tính toán bằng tay:
Tìm phương sai bằng cách sử dụng Pandas
Mặc dù chúng ta có thể viết một hàm tính toán phương sai trong ít hơn 10 dòng mã, nhưng có một cách dễ dàng hơn để tìm phương sai. Bạn có thể làm điều đó trong một dòng mã sử dụng Pandas. Hãy tải dữ liệu mẫu và thực hiện ví dụ thực tế về việc tìm phương sai.
Tải dữ liệu ví dụ
Ví dụ sử dụng Pandas sử dụng bộ dữ liệu Thách thức Giá xe BMW từ Kaggle, có thể tải miễn phí. Bắt đầu bằng cách nhập thư viện Pandas, sau đó đọc tệp CSV vào một khung dữ liệu Pandas:

Chúng ta có thể đếm số hàng trong bộ dữ liệu và hiển thị năm hàng đầu tiên để đảm bảo mọi thứ đã tải đúng cách:
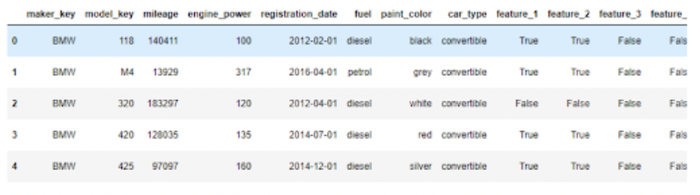 Displaying the first rows using bmw_df.head()
Displaying the first rows using bmw_df.head()Tìm phương sai cho dữ liệu BMW
Vì bộ dữ liệu BMW có 4843 hàng, tính toán bằng tay sẽ...không vui. Thay vào đó, chúng ta có thể đơn giản là đưa cột từ khung dữ liệu vào hàm calculate_variance của chúng ta và trả về phương sai. Hãy tìm phương sai cho các cột số như mileage, engine_power và price.
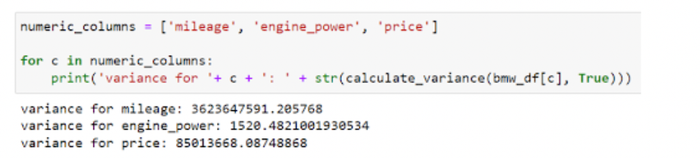 Variance for numeric columns in the BMW data frame
Variance for numeric columns in the BMW data frameSử dụng hàm var() của Pandas
Trong trường hợp chúng ta quên công thức tính phương sai và không thể viết chức năng của chúng ta, Pandas có một chức năng tính phương sai tích hợp sẵn được đặt tên là var(). Theo mặc định, nó giả sử đó là một mẫu từ quần thể và sử dụng n-1 trong tính toán; tuy nhiên, bạn có thể điều chỉnh tính toán bằng cách truyền đối số ddof=0.
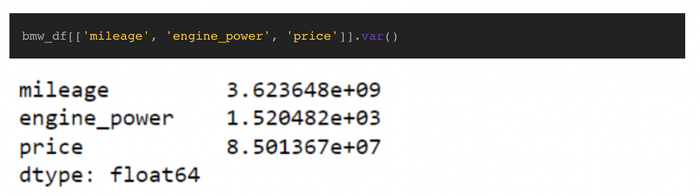 Pandas var() function
Pandas var() functionNhư chúng ta thấy, hàm Var() khớp với các giá trị do chúng ta tính toán bằng hàm calculate_variance của chúng ta và chỉ là một dòng mã. Xem xét kết quả, chúng ta thấy mileage có phương sai cao, điều này có nghĩa là giá trị thường biến động rất nhiều so với giá trị trung bình. Điều này hợp lý vì nhiều yếu tố đóng vai trò trong khoảng cách mà một người cần lái xe. Ngược lại, engine_power có phương sai thấp, điều này cho thấy giá trị không biến động rộng lớn so với giá trị trung bình.
Bài học chính
Hiểu biết về phương sai có thể là một phần quan trọng của phân tích dữ liệu và máy học vì bạn có thể sử dụng nó để đánh giá sự khác biệt giữa các nhóm. Phương sai cũng ảnh hưởng đến việc xác định kiểm định thống kê nào có thể giúp chúng ta đưa ra quyết định dựa trên dữ liệu. Phương sai cao có nghĩa là giá trị có sự phân tán lớn từ giá trị trung bình, trong khi phương sai thấp có nghĩa là các số không phân tán rộng lớn từ giá trị trung bình. Nếu chúng ta có một tập giá trị nhỏ, có thể tính toán phương sai bằng tay chỉ trong năm bước. Đối với các bộ dữ liệu lớn, chúng ta thấy cách đơn giản để tính toán phương sai bằng Python và Pandas. Hàm Var() trong Pandas tính toán phương sai cho các cột số trong một khung dữ liệu chỉ trong một dòng mã, điều này khá tiện lợi!