
 Dù thiết kế chiplet đã tồn tại từ lâu nhưng đến nay mới thực sự nổi lên với vai trò quan trọng trong ngành công nghệ. AMD, một trong những ông lớn của ngành, đã sử dụng chiplet để định vị lại vị thế của mình trong cuộc cạnh tranh. Dường như không còn xa lạ khi chiplet sẽ trở thành tiêu chuẩn trong ngành công nghệ máy tính. Bài viết này sẽ giải thích một số khái niệm cơ bản về chiplet và vì sao chúng lại trở nên quan trọng đến vậy.AMD đã chứng minh sức mạnh của chiplet, đặt nền móng cho một tương lai mà vi xử lý không còn bị giới hạn bởi kích thước của một chip duy nhất. Chiplet không chỉ là xu hướng mà còn là sự cần thiết để đáp ứng nhu cầu ngày càng tăng về hiệu suất và tính linh hoạt trong ngành công nghệ.Chiplet là gì?Chiplet là những đơn vị xử lý được chia thành các phần nhỏ, từng khu vực. Thay vì tổng hợp tất cả vào một con chip duy nhất (gọi là phương pháp nguyên khối - monolithic), các phần riêng lẻ được sản xuất như các con chip độc lập. Các con chip này sau đó được lắp ráp lại với nhau thành một gói duy nhất thông qua một hệ thống kết nối phức tạp.Về cấu trúc, chúng giống như một khu phức hợp thương mại, với các cửa hàng tập trung lại một chỗ, sắp xếp đều đặn thành từng ô. Do đó, chiplet có thể được hiểu như là các 'cửa hàng' chip.
Sắp xếp này cho phép các thành phần hưởng lợi từ các phương pháp sản xuất mới nhất, giúp thu nhỏ kích thước, tăng cường hiệu quả của quy trình và cho phép chúng tương thích với nhiều thành phần hơn. Cách tiếp cận này dựa trên việc chỉ một số thành phần sử dụng công nghệ mới nhất, không cần phải là toàn bộ chip, nếu điều kiện không cho phép.
Lấy ví dụ về một trung tâm thương mại, mỗi cửa hàng bên trong có thể thiết kế theo ý muốn, bán các sản phẩm cao cấp hoặc phổ thông. Thay vì là một cửa hàng lớn duy nhất (phương pháp nguyên khối) yêu cầu sự nhất quán trong thiết kế và hàng hóa.
Dù thiết kế chiplet đã tồn tại từ lâu nhưng đến nay mới thực sự nổi lên với vai trò quan trọng trong ngành công nghệ. AMD, một trong những ông lớn của ngành, đã sử dụng chiplet để định vị lại vị thế của mình trong cuộc cạnh tranh. Dường như không còn xa lạ khi chiplet sẽ trở thành tiêu chuẩn trong ngành công nghệ máy tính. Bài viết này sẽ giải thích một số khái niệm cơ bản về chiplet và vì sao chúng lại trở nên quan trọng đến vậy.AMD đã chứng minh sức mạnh của chiplet, đặt nền móng cho một tương lai mà vi xử lý không còn bị giới hạn bởi kích thước của một chip duy nhất. Chiplet không chỉ là xu hướng mà còn là sự cần thiết để đáp ứng nhu cầu ngày càng tăng về hiệu suất và tính linh hoạt trong ngành công nghệ.Chiplet là gì?Chiplet là những đơn vị xử lý được chia thành các phần nhỏ, từng khu vực. Thay vì tổng hợp tất cả vào một con chip duy nhất (gọi là phương pháp nguyên khối - monolithic), các phần riêng lẻ được sản xuất như các con chip độc lập. Các con chip này sau đó được lắp ráp lại với nhau thành một gói duy nhất thông qua một hệ thống kết nối phức tạp.Về cấu trúc, chúng giống như một khu phức hợp thương mại, với các cửa hàng tập trung lại một chỗ, sắp xếp đều đặn thành từng ô. Do đó, chiplet có thể được hiểu như là các 'cửa hàng' chip.
Sắp xếp này cho phép các thành phần hưởng lợi từ các phương pháp sản xuất mới nhất, giúp thu nhỏ kích thước, tăng cường hiệu quả của quy trình và cho phép chúng tương thích với nhiều thành phần hơn. Cách tiếp cận này dựa trên việc chỉ một số thành phần sử dụng công nghệ mới nhất, không cần phải là toàn bộ chip, nếu điều kiện không cho phép.
Lấy ví dụ về một trung tâm thương mại, mỗi cửa hàng bên trong có thể thiết kế theo ý muốn, bán các sản phẩm cao cấp hoặc phổ thông. Thay vì là một cửa hàng lớn duy nhất (phương pháp nguyên khối) yêu cầu sự nhất quán trong thiết kế và hàng hóa. nhưng tổng chi phí thường thấp hơnĐào sâu vào khoa học của silicĐể thấu hiểu rõ vì sao các nhà sản xuất bộ xử lý chuyển sang sử dụng chiplet, chúng ta cần khám phá kỹ càng quá trình tạo ra các thiết bị này. CPU và GPU bắt đầu cuộc hành trình của chúng dưới dạng các đĩa lớn làm từ silic tinh khiết, thường có đường kính dưới 12 inch (300 mm) một chút và dày 0.04 inch (1 mm).
Tấm wafer silic này trải qua một chuỗi các bước phức tạp, tạo ra nhiều lớp vật liệu khác nhau - chất cách điện, chất điện môi và kim loại. Các mẫu của các lớp này được tạo ra thông qua một quy trình gọi là phô to-litographi, trong đó ánh sáng cực tím được chiếu qua một bản sao phóng to của mẫu (mặt nạ) và sau đó được thu nhỏ qua thấu kính đến kích thước cần thiết.
Mẫu này được lặp lại theo các chu kỳ đã định trên bề mặt của tấm bán dẫn và mỗi mẫu này sau cùng sẽ trở thành một bộ xử lý. Vì các chip có hình chữ nhật trong khi wafer lại có hình tròn, nên các mẫu phải được xếp chồng lên nhau xung quanh chu vi của đĩa. Những phần này sau cùng sẽ bị loại bỏ vì chúng không hoạt động.
nhưng tổng chi phí thường thấp hơnĐào sâu vào khoa học của silicĐể thấu hiểu rõ vì sao các nhà sản xuất bộ xử lý chuyển sang sử dụng chiplet, chúng ta cần khám phá kỹ càng quá trình tạo ra các thiết bị này. CPU và GPU bắt đầu cuộc hành trình của chúng dưới dạng các đĩa lớn làm từ silic tinh khiết, thường có đường kính dưới 12 inch (300 mm) một chút và dày 0.04 inch (1 mm).
Tấm wafer silic này trải qua một chuỗi các bước phức tạp, tạo ra nhiều lớp vật liệu khác nhau - chất cách điện, chất điện môi và kim loại. Các mẫu của các lớp này được tạo ra thông qua một quy trình gọi là phô to-litographi, trong đó ánh sáng cực tím được chiếu qua một bản sao phóng to của mẫu (mặt nạ) và sau đó được thu nhỏ qua thấu kính đến kích thước cần thiết.
Mẫu này được lặp lại theo các chu kỳ đã định trên bề mặt của tấm bán dẫn và mỗi mẫu này sau cùng sẽ trở thành một bộ xử lý. Vì các chip có hình chữ nhật trong khi wafer lại có hình tròn, nên các mẫu phải được xếp chồng lên nhau xung quanh chu vi của đĩa. Những phần này sau cùng sẽ bị loại bỏ vì chúng không hoạt động. Khi hoàn thành, wafer được kiểm tra bằng cách sử dụng đầu dò áp dụng cho từng chip. Kết quả kiểm tra dưới dạng điện giúp kỹ sư đánh giá chất lượng của bộ xử lý dựa trên các tiêu chí cụ thể. Giai đoạn này, được gọi là chip binning, giúp phân loại bộ xử lý theo 'cấp độ'.
Ví dụ, nếu một con chip dự kiến sẽ là CPU, thì mọi thành phần phải hoạt động chính xác, ở một phạm vi tốc độ xung nhịp nhất định, và ở một điện áp cụ thể. Mỗi phần wafer sau đó được phân loại dựa trên các kết quả kiểm tra này.
Sau khi hoàn thành, wafer được cắt thành từng mảnh riêng biệt hoặc các 'đi', sẵn sàng để sử dụng. Những điều này sau đó được gắn lên một nền tảng, giống như một bo mạch chủ đặc biệt. Bộ xử lý trải qua quá trình đóng gói bổ sung (ví dụ: với bộ tản nhiệt) trước khi sẵn sàng để phân phối.
Khi hoàn thành, wafer được kiểm tra bằng cách sử dụng đầu dò áp dụng cho từng chip. Kết quả kiểm tra dưới dạng điện giúp kỹ sư đánh giá chất lượng của bộ xử lý dựa trên các tiêu chí cụ thể. Giai đoạn này, được gọi là chip binning, giúp phân loại bộ xử lý theo 'cấp độ'.
Ví dụ, nếu một con chip dự kiến sẽ là CPU, thì mọi thành phần phải hoạt động chính xác, ở một phạm vi tốc độ xung nhịp nhất định, và ở một điện áp cụ thể. Mỗi phần wafer sau đó được phân loại dựa trên các kết quả kiểm tra này.
Sau khi hoàn thành, wafer được cắt thành từng mảnh riêng biệt hoặc các 'đi', sẵn sàng để sử dụng. Những điều này sau đó được gắn lên một nền tảng, giống như một bo mạch chủ đặc biệt. Bộ xử lý trải qua quá trình đóng gói bổ sung (ví dụ: với bộ tản nhiệt) trước khi sẵn sàng để phân phối. Toàn bộ quy trình này có thể mất hàng tuần để thực hiện và các công ty như TSMC và Samsung đều tính phí cao cho mỗi tấm wafer, từ khoảng 3,000 đến 20,000 đô la tùy thuộc vào nút tiến trình hiện đang sử dụng.
'Nút tiến trình' là thuật ngữ để mô tả toàn bộ hệ thống sản xuất. Trước đây, chúng được đặt tên dựa trên chiều dài cổng bóng bán dẫn. Tuy nhiên, khi công nghệ sản xuất cải thiện và cho phép các thành phần ngày càng nhỏ hơn, thuật ngữ này không còn phản ánh bất kỳ khía cạnh vật lý nào của chip nữa, giờ đây nó chỉ đơn giản là một công cụ tiếp thị.
Tuy nhiên, mỗi nút tiến trình mới vẫn mang lại lợi ích so với nút tiền nhiệm trước đó. Nó có thể rẻ hơn để sản xuất, tiêu thụ ít năng lượng hơn ở cùng tốc độ xung nhịp (hoặc ngược lại: xung nhịp cao hơn với cùng một mức năng lượng) hoặc có mật độ cao hơn. Thang đo về mật độ đo lường xem có bao nhiêu thành phần có thể vừa với một diện tích khuôn nhất định. Trong biểu đồ bên dưới, chúng ta có thể thấy việc này đã tiến triển như thế nào qua nhiều năm đối với GPU (chip lớn nhất và phức tạp nhất mà bạn sẽ tìm thấy trong PC).
Toàn bộ quy trình này có thể mất hàng tuần để thực hiện và các công ty như TSMC và Samsung đều tính phí cao cho mỗi tấm wafer, từ khoảng 3,000 đến 20,000 đô la tùy thuộc vào nút tiến trình hiện đang sử dụng.
'Nút tiến trình' là thuật ngữ để mô tả toàn bộ hệ thống sản xuất. Trước đây, chúng được đặt tên dựa trên chiều dài cổng bóng bán dẫn. Tuy nhiên, khi công nghệ sản xuất cải thiện và cho phép các thành phần ngày càng nhỏ hơn, thuật ngữ này không còn phản ánh bất kỳ khía cạnh vật lý nào của chip nữa, giờ đây nó chỉ đơn giản là một công cụ tiếp thị.
Tuy nhiên, mỗi nút tiến trình mới vẫn mang lại lợi ích so với nút tiền nhiệm trước đó. Nó có thể rẻ hơn để sản xuất, tiêu thụ ít năng lượng hơn ở cùng tốc độ xung nhịp (hoặc ngược lại: xung nhịp cao hơn với cùng một mức năng lượng) hoặc có mật độ cao hơn. Thang đo về mật độ đo lường xem có bao nhiêu thành phần có thể vừa với một diện tích khuôn nhất định. Trong biểu đồ bên dưới, chúng ta có thể thấy việc này đã tiến triển như thế nào qua nhiều năm đối với GPU (chip lớn nhất và phức tạp nhất mà bạn sẽ tìm thấy trong PC).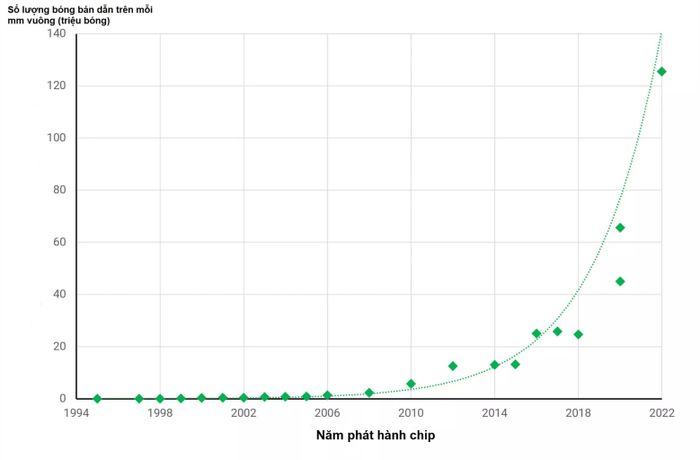 Mật độ bóng bán dẫn của GPU đã tăng vọt trong 30 năm qua, đặc biệt là từ năm 2014 trở đi.
Mật độ bóng bán dẫn của GPU đã tăng vọt trong 30 năm qua, đặc biệt là từ năm 2014 trở đi.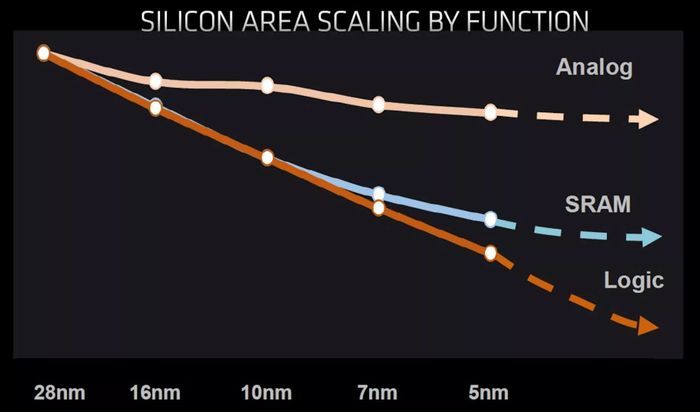 Tỷ lệ diện tích của các loại mạch chức năng trên miếng silicon: Mạch Logic đang giảm diện tích nhưng diện tích Analog và SRAM đang chững lại.
Mặc dù mạch logic vẫn chiếm phần lớn trong khuôn, nhưng lượng SRAM trong CPU và GPU đã tăng đáng kể trong những năm gần đây. Ví dụ: chip Vega 20 của AMD được sử dụng trong card đồ họa Radeon VII có tổng cộng 5 MB bộ đệm cache L1 và L2. Chỉ cần hai thế hệ GPU sau, Navi 21 có hơn 130 MB bộ nhớ cache đủ loại - gấp 25 lần so với Vega 20.
Có thể dự kiến rằng các mức cache này sẽ tiếp tục tăng khi các thế hệ bộ xử lý mới được phát triển, nhưng với việc bộ nhớ không thu nhỏ như logic, việc sản xuất tất cả các mạch điện trên cùng một nút tiến trình sẽ trở nên ít hiệu quả hơn về mặt chi phí.
Trong một thế giới lí tưởng, ta sẽ thiết kế một khuôn mà trong đó các phần analog được sản xuất trên nút lớn nhất và rẻ nhất, các bộ phận SRAM trên một nút nhỏ hơn nhiều và mạch logic dành riêng cho công nghệ tiên tiến tuyệt đối. Thật không may, điều này không thể đạt được trên thực tế. Tuy nhiên, vẫn tồn tại một cách tiếp cận khác.Phân chia và vượt quaQuay lại năm 1995, Intel ra mắt kế nhiệm của vi xử lý kiến trúc P5 với phiên bản Pentium II. Điểm độc đáo so với CPU thường ở thời điểm đó là dưới tấm chắn nhựa có một bảng mạch chứa hai chip: chip chính, bao gồm toàn bộ hệ thống logic xử lý và hệ thống analog, cùng với một hoặc hai mô-đun SRAM riêng biệt đóng vai trò bộ đệm cache L2.
Intel sản xuất chip chính, nhưng bộ đệm lại được cung cấp từ các công ty khác. Điều này trở thành tiêu chuẩn phổ biến đối với máy tính để bàn vào cuối những năm 1990, cho đến khi kỹ thuật sản xuất chất bán dẫn được cải thiện đến mức mà mạch logic, bộ nhớ đệm và analog có thể tích hợp vào cùng một khuôn.
Tỷ lệ diện tích của các loại mạch chức năng trên miếng silicon: Mạch Logic đang giảm diện tích nhưng diện tích Analog và SRAM đang chững lại.
Mặc dù mạch logic vẫn chiếm phần lớn trong khuôn, nhưng lượng SRAM trong CPU và GPU đã tăng đáng kể trong những năm gần đây. Ví dụ: chip Vega 20 của AMD được sử dụng trong card đồ họa Radeon VII có tổng cộng 5 MB bộ đệm cache L1 và L2. Chỉ cần hai thế hệ GPU sau, Navi 21 có hơn 130 MB bộ nhớ cache đủ loại - gấp 25 lần so với Vega 20.
Có thể dự kiến rằng các mức cache này sẽ tiếp tục tăng khi các thế hệ bộ xử lý mới được phát triển, nhưng với việc bộ nhớ không thu nhỏ như logic, việc sản xuất tất cả các mạch điện trên cùng một nút tiến trình sẽ trở nên ít hiệu quả hơn về mặt chi phí.
Trong một thế giới lí tưởng, ta sẽ thiết kế một khuôn mà trong đó các phần analog được sản xuất trên nút lớn nhất và rẻ nhất, các bộ phận SRAM trên một nút nhỏ hơn nhiều và mạch logic dành riêng cho công nghệ tiên tiến tuyệt đối. Thật không may, điều này không thể đạt được trên thực tế. Tuy nhiên, vẫn tồn tại một cách tiếp cận khác.Phân chia và vượt quaQuay lại năm 1995, Intel ra mắt kế nhiệm của vi xử lý kiến trúc P5 với phiên bản Pentium II. Điểm độc đáo so với CPU thường ở thời điểm đó là dưới tấm chắn nhựa có một bảng mạch chứa hai chip: chip chính, bao gồm toàn bộ hệ thống logic xử lý và hệ thống analog, cùng với một hoặc hai mô-đun SRAM riêng biệt đóng vai trò bộ đệm cache L2.
Intel sản xuất chip chính, nhưng bộ đệm lại được cung cấp từ các công ty khác. Điều này trở thành tiêu chuẩn phổ biến đối với máy tính để bàn vào cuối những năm 1990, cho đến khi kỹ thuật sản xuất chất bán dẫn được cải thiện đến mức mà mạch logic, bộ nhớ đệm và analog có thể tích hợp vào cùng một khuôn. Bộ xử lý Pentium II của Intel - với CPU ở chính giữa, các chip bộ đệm cache nằm bên phải. Nguồn: Wikimedia.
Mặc dù Intel tiếp tục nghiên cứu nhiều chip trong cùng một gói, nhưng phần lớn họ bị mắc kẹt với cái gọi là cách tiếp cận nguyên khối cho bộ xử lý – tức là một chip cho mọi thứ. Đối với hầu hết các bộ xử lý, không cần nhiều hơn một khuôn, vì các kỹ thuật sản xuất đủ thành thạo (và giá cả phải chăng) để giữ cho nó đơn giản.
Tuy nhiên, các công ty khác lại quan tâm nhiều hơn đến cách tiếp cận đa chip, đáng chú ý nhất là IBM. Vào năm 2004, ta có thể mua phiên bản gồm 8 chip của CPU máy chủ POWER4 bao gồm bốn bộ xử lý và bốn mô-đun bộ đệm cache, tất cả được gắn trong cùng một khối (được gọi là mô-đun nhiều chip hoặc cách tiếp cận MCM - multi-chip module).
Khoảng thời gian này, thuật ngữ 'tích hợp không đồng nhất (HI)' (heterogeneous integration) bắt đầu xuất hiện, một phần là do công việc nghiên cứu được thực hiện bởi DARPA (Cơ quan chỉ đạo các Dự án Nghiên cứu Quốc phòng Tiên tiến). HI nhằm mục đích phân tách các phần khác nhau của một hệ thống xử lý, chế tạo chúng một cách riêng lẻ trên các nút phù hợp nhất cho từng phần, sau đó kết hợp chúng vào cùng một gói.
Hiện nay, phương pháp này được gọi là Hệ thống trong gói (System-in-Package, SiP) và đã trở thành tiêu chuẩn cho việc tích hợp chip vào các thiết bị như đồng hồ thông minh ngay từ khi chúng xuất hiện. Ví dụ: Apple Watch Series 1 chứa CPU, DRAM, bộ nhớ NAND Flash, bộ điều khiển và các thành phần khác trong một cấu trúc duy nhất.
Bộ xử lý Pentium II của Intel - với CPU ở chính giữa, các chip bộ đệm cache nằm bên phải. Nguồn: Wikimedia.
Mặc dù Intel tiếp tục nghiên cứu nhiều chip trong cùng một gói, nhưng phần lớn họ bị mắc kẹt với cái gọi là cách tiếp cận nguyên khối cho bộ xử lý – tức là một chip cho mọi thứ. Đối với hầu hết các bộ xử lý, không cần nhiều hơn một khuôn, vì các kỹ thuật sản xuất đủ thành thạo (và giá cả phải chăng) để giữ cho nó đơn giản.
Tuy nhiên, các công ty khác lại quan tâm nhiều hơn đến cách tiếp cận đa chip, đáng chú ý nhất là IBM. Vào năm 2004, ta có thể mua phiên bản gồm 8 chip của CPU máy chủ POWER4 bao gồm bốn bộ xử lý và bốn mô-đun bộ đệm cache, tất cả được gắn trong cùng một khối (được gọi là mô-đun nhiều chip hoặc cách tiếp cận MCM - multi-chip module).
Khoảng thời gian này, thuật ngữ 'tích hợp không đồng nhất (HI)' (heterogeneous integration) bắt đầu xuất hiện, một phần là do công việc nghiên cứu được thực hiện bởi DARPA (Cơ quan chỉ đạo các Dự án Nghiên cứu Quốc phòng Tiên tiến). HI nhằm mục đích phân tách các phần khác nhau của một hệ thống xử lý, chế tạo chúng một cách riêng lẻ trên các nút phù hợp nhất cho từng phần, sau đó kết hợp chúng vào cùng một gói.
Hiện nay, phương pháp này được gọi là Hệ thống trong gói (System-in-Package, SiP) và đã trở thành tiêu chuẩn cho việc tích hợp chip vào các thiết bị như đồng hồ thông minh ngay từ khi chúng xuất hiện. Ví dụ: Apple Watch Series 1 chứa CPU, DRAM, bộ nhớ NAND Flash, bộ điều khiển và các thành phần khác trong một cấu trúc duy nhất. Hình ảnh tia X cấu trúc SiP của Apple Watch Series 1. Nguồn: iFixit.
Cách tiếp cận tương tự có thể được thực hiện bằng cách đặt tất cả các hệ thống khác nhau trên một chip duy nhất (gọi là Hệ thống trên cùng một chip hoặc SoC). Tuy nhiên, cách tiếp cận này không tận dụng được các nút giá rẻ khác nhau, cũng như không thể sản xuất mọi thành phần theo cách này.
Đối với một nhà cung cấp công nghệ, áp dụng tích hợp không đồng nhất cho một sản phẩm thị trường ngách là một vấn đề, nhưng triển khai nó cho hầu hết danh mục đầu tư của họ là một vấn đề khác. Điều này chính xác là gì AMD đã thực hiện với dòng bộ xử lý của mình. Vào năm 2017, hãng đã phát hành kiến trúc Zen dưới dạng CPU Ryzen. Vài tháng sau, hai dòng sản phẩm đa chip, Threadripper và EPYC, được ra mắt, với EPYC tự hào sở hữu tới bốn khuôn.
Với sự ra mắt của Zen 2 hai năm sau đó, AMD đã hoàn toàn chấp nhận HI, MCM, SiP – bất kể bạn muốn gọi là gì. Họ đã chuyển phần lớn hệ thống analog ra khỏi bộ xử lý và đặt chúng vào một khuôn riêng, lựa chọn những gì không phù hợp. Chúng được sản xuất trên nút tiến trình đơn giản hơn, rẻ hơn, trong khi nút tiên tiến hơn được sử dụng cho phần logic và bộ đệm cache còn lại.
Do đó, chiplets đã trở thành một lựa chọn phổ biến.Lớn không phải lúc nào cũng tốtĐể hiểu rõ tại sao AMD lại lựa chọn con đường này, chúng ta hãy xem xét hình ảnh dưới đây. Đây là hai CPU từ dòng Ryzen 5 – 2600 ở bên trái, sử dụng kiến trúc Zen+, và 3600 có kiến trúc Zen 2 ở bên phải.
Bộ tản nhiệt trên cả hai mẫu CPU đã bị tháo ra và hình ảnh được chụp bằng máy ảnh hồng ngoại. Khuôn đơn của 2600 chứa tám lõi, mặc dù hai trong số chúng đã bị vô hiệu hóa trên mẫu CPU cụ thể này.
Hình ảnh tia X cấu trúc SiP của Apple Watch Series 1. Nguồn: iFixit.
Cách tiếp cận tương tự có thể được thực hiện bằng cách đặt tất cả các hệ thống khác nhau trên một chip duy nhất (gọi là Hệ thống trên cùng một chip hoặc SoC). Tuy nhiên, cách tiếp cận này không tận dụng được các nút giá rẻ khác nhau, cũng như không thể sản xuất mọi thành phần theo cách này.
Đối với một nhà cung cấp công nghệ, áp dụng tích hợp không đồng nhất cho một sản phẩm thị trường ngách là một vấn đề, nhưng triển khai nó cho hầu hết danh mục đầu tư của họ là một vấn đề khác. Điều này chính xác là gì AMD đã thực hiện với dòng bộ xử lý của mình. Vào năm 2017, hãng đã phát hành kiến trúc Zen dưới dạng CPU Ryzen. Vài tháng sau, hai dòng sản phẩm đa chip, Threadripper và EPYC, được ra mắt, với EPYC tự hào sở hữu tới bốn khuôn.
Với sự ra mắt của Zen 2 hai năm sau đó, AMD đã hoàn toàn chấp nhận HI, MCM, SiP – bất kể bạn muốn gọi là gì. Họ đã chuyển phần lớn hệ thống analog ra khỏi bộ xử lý và đặt chúng vào một khuôn riêng, lựa chọn những gì không phù hợp. Chúng được sản xuất trên nút tiến trình đơn giản hơn, rẻ hơn, trong khi nút tiên tiến hơn được sử dụng cho phần logic và bộ đệm cache còn lại.
Do đó, chiplets đã trở thành một lựa chọn phổ biến.Lớn không phải lúc nào cũng tốtĐể hiểu rõ tại sao AMD lại lựa chọn con đường này, chúng ta hãy xem xét hình ảnh dưới đây. Đây là hai CPU từ dòng Ryzen 5 – 2600 ở bên trái, sử dụng kiến trúc Zen+, và 3600 có kiến trúc Zen 2 ở bên phải.
Bộ tản nhiệt trên cả hai mẫu CPU đã bị tháo ra và hình ảnh được chụp bằng máy ảnh hồng ngoại. Khuôn đơn của 2600 chứa tám lõi, mặc dù hai trong số chúng đã bị vô hiệu hóa trên mẫu CPU cụ thể này. Trái: Khuôn của Ryzen 5 2600, Phải: Khuôn của Ryzen 5 3600. Ảnh: Fritzchen Fritz.
Cũng là trường hợp của 3600, nhưng ở đây chúng ta có thể thấy có hai khuôn trong gói – Khuôn Phức hợp Lõi (CCD) ở trên cùng, chứa các lõi và bộ đệm, và Khuôn Đầu vào/Đầu ra (IOD) ở phần dưới cùng chứa tất cả các bộ điều khiển (dành cho bộ nhớ, PCI Express, USB, v.v.) và các giao diện vật lý.
Vì cả hai CPU Ryzen đều khớp với cùng một ổ socket bo mạch chủ, nên hai hình ảnh về cơ bản là để chia tỷ lệ. Nhìn bề ngoài, có vẻ như hai khuôn trong 3600 có diện tích kết hợp lớn hơn so với chip đơn trong 2600, nhưng vẻ bề ngoài có thể gây nhầm lẫn.
So sánh trực tiếp giữa chip chứa lõi, rõ ràng thấy mạch analog chiếm không gian đáng kể trong mẫu chip cũ (Zen+). Trong khi đó, trong CCD của Zen 2, rất ít diện tích khuôn được dành cho các hệ thống analog; nó gần như hoàn toàn bao gồm logic và SRAM (cache).
Chip Zen+ có diện tích 213 mm² và được sản xuất bởi GlobalFoundries bằng nút tiến trình 12nm. Đối với Zen 2, AMD đã giữ lại các dịch vụ của GlobalFoundries cho 125 mm² diện tích của IOD nhưng sử dụng nút tiến trình N7 ưu việt của TSMC cho 73 mm² của CCD.
Trái: Khuôn của Ryzen 5 2600, Phải: Khuôn của Ryzen 5 3600. Ảnh: Fritzchen Fritz.
Cũng là trường hợp của 3600, nhưng ở đây chúng ta có thể thấy có hai khuôn trong gói – Khuôn Phức hợp Lõi (CCD) ở trên cùng, chứa các lõi và bộ đệm, và Khuôn Đầu vào/Đầu ra (IOD) ở phần dưới cùng chứa tất cả các bộ điều khiển (dành cho bộ nhớ, PCI Express, USB, v.v.) và các giao diện vật lý.
Vì cả hai CPU Ryzen đều khớp với cùng một ổ socket bo mạch chủ, nên hai hình ảnh về cơ bản là để chia tỷ lệ. Nhìn bề ngoài, có vẻ như hai khuôn trong 3600 có diện tích kết hợp lớn hơn so với chip đơn trong 2600, nhưng vẻ bề ngoài có thể gây nhầm lẫn.
So sánh trực tiếp giữa chip chứa lõi, rõ ràng thấy mạch analog chiếm không gian đáng kể trong mẫu chip cũ (Zen+). Trong khi đó, trong CCD của Zen 2, rất ít diện tích khuôn được dành cho các hệ thống analog; nó gần như hoàn toàn bao gồm logic và SRAM (cache).
Chip Zen+ có diện tích 213 mm² và được sản xuất bởi GlobalFoundries bằng nút tiến trình 12nm. Đối với Zen 2, AMD đã giữ lại các dịch vụ của GlobalFoundries cho 125 mm² diện tích của IOD nhưng sử dụng nút tiến trình N7 ưu việt của TSMC cho 73 mm² của CCD. Zen+ (phía trên) so sánh với CCD của Zen 2 (phía dưới).
Diện tích tổng hợp của các chip trong kiến trúc mới Zen 2 nhỏ hơn Zen+ (73+125 < 213) và nó cũng tự hào có bộ nhớ đệm L3 gấp đôi, hỗ trợ bộ nhớ nhanh hơn và PCI Express. Sự phát triển này đã khai sinh ra dòng Ryzen 9, cung cấp các mẫu CPU 12 và 16 lõi cho máy tính để bàn.
Thậm chí còn tốt hơn nữa là bằng cách sử dụng hai chip nhỏ hơn thay vì một chip lớn, mỗi tấm wafer có khả năng tạo ra nhiều khuôn hơn. Trong trường hợp của CCD trong Zen 2, một tấm wafer 12 inch (300 mm) duy nhất có thể tạo ra nhiều khuôn hơn tới 85% so với mẫu Zen+.
Một lát cắt ra khỏi tấm wafer càng nhỏ thì càng ít khả năng phát hiện lỗi sản xuất (vì chúng có xu hướng phân bố ngẫu nhiên trên đĩa), do đó, khi tính đến tất cả những điều này, phương pháp chiplet không chỉ mang lại cho AMD khả năng mở rộng danh mục đầu tư của mình, cho đến nay nó còn hiệu quả về chi phí hơn rất nhiều – cùng các CCD đó có thể được sử dụng trong nhiều mẫu chip và mỗi tấm wafer tạo ra hàng trăm mẫu chip như vậy.
Tuy nếu lựa chọn này có lợi thế, vậy tại sao Intel không thử? Và tại sao không thấy nó trong các bộ xử lý khác, như GPU?Theo đuổi sự lãnh đạoĐể giải đáp câu hỏi đầu tiên, Intel đã bắt đầu áp dụng hoàn toàn lộ trình chiplet và họ đang tiến về hướng đúng với kiến trúc CPU tiếp theo của mình, gọi là Meteor Lake (Hồ sao băng). Tất nhiên, cách tiếp cận của Intel có sự độc đáo riêng, vì vậy hãy khám phá cách nó khác biệt so với AMD.
Zen+ (phía trên) so sánh với CCD của Zen 2 (phía dưới).
Diện tích tổng hợp của các chip trong kiến trúc mới Zen 2 nhỏ hơn Zen+ (73+125 < 213) và nó cũng tự hào có bộ nhớ đệm L3 gấp đôi, hỗ trợ bộ nhớ nhanh hơn và PCI Express. Sự phát triển này đã khai sinh ra dòng Ryzen 9, cung cấp các mẫu CPU 12 và 16 lõi cho máy tính để bàn.
Thậm chí còn tốt hơn nữa là bằng cách sử dụng hai chip nhỏ hơn thay vì một chip lớn, mỗi tấm wafer có khả năng tạo ra nhiều khuôn hơn. Trong trường hợp của CCD trong Zen 2, một tấm wafer 12 inch (300 mm) duy nhất có thể tạo ra nhiều khuôn hơn tới 85% so với mẫu Zen+.
Một lát cắt ra khỏi tấm wafer càng nhỏ thì càng ít khả năng phát hiện lỗi sản xuất (vì chúng có xu hướng phân bố ngẫu nhiên trên đĩa), do đó, khi tính đến tất cả những điều này, phương pháp chiplet không chỉ mang lại cho AMD khả năng mở rộng danh mục đầu tư của mình, cho đến nay nó còn hiệu quả về chi phí hơn rất nhiều – cùng các CCD đó có thể được sử dụng trong nhiều mẫu chip và mỗi tấm wafer tạo ra hàng trăm mẫu chip như vậy.
Tuy nếu lựa chọn này có lợi thế, vậy tại sao Intel không thử? Và tại sao không thấy nó trong các bộ xử lý khác, như GPU?Theo đuổi sự lãnh đạoĐể giải đáp câu hỏi đầu tiên, Intel đã bắt đầu áp dụng hoàn toàn lộ trình chiplet và họ đang tiến về hướng đúng với kiến trúc CPU tiếp theo của mình, gọi là Meteor Lake (Hồ sao băng). Tất nhiên, cách tiếp cận của Intel có sự độc đáo riêng, vì vậy hãy khám phá cách nó khác biệt so với AMD.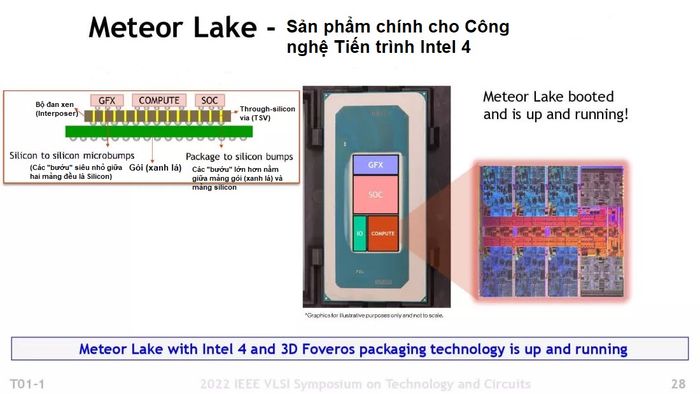 Bốn ô gạch kết nối tốc độ cao với nhau và tất cả chúng cùng kết nối với bộ đan xen - interposer, thông qua các “bướu” nhỏ trong hình. Các TSV (màu vàng) chạy xuyên qua lớp interposer (phần màu nâu) có các lớp dây dẫn nằm theo phương ngang để tạo ra kết nối. Dưới cùng là các 'bướu' lớn hơn để nối kết chính bộ đan xen này với bảng mạch lớn, còn gọi là gói. Điều đáng chú ý là ở hình minh họa cắt dọc khá mơ hồ này của Intel không thể hiện ô gạch I/O, hàm ý rằng cách mà nó kết nối với bộ đan xen có thể khác biệt và tốc độ thấp hơn so với 3 ô còn lại.
Sử dụng thuật ngữ ô gạch (tile) thay vì chiplet, thế hệ bộ xử lý này sẽ chia thiết kế nguyên khối trước đó thành bốn chip riêng biệt:
Bốn ô gạch kết nối tốc độ cao với nhau và tất cả chúng cùng kết nối với bộ đan xen - interposer, thông qua các “bướu” nhỏ trong hình. Các TSV (màu vàng) chạy xuyên qua lớp interposer (phần màu nâu) có các lớp dây dẫn nằm theo phương ngang để tạo ra kết nối. Dưới cùng là các 'bướu' lớn hơn để nối kết chính bộ đan xen này với bảng mạch lớn, còn gọi là gói. Điều đáng chú ý là ở hình minh họa cắt dọc khá mơ hồ này của Intel không thể hiện ô gạch I/O, hàm ý rằng cách mà nó kết nối với bộ đan xen có thể khác biệt và tốc độ thấp hơn so với 3 ô còn lại.
Sử dụng thuật ngữ ô gạch (tile) thay vì chiplet, thế hệ bộ xử lý này sẽ chia thiết kế nguyên khối trước đó thành bốn chip riêng biệt: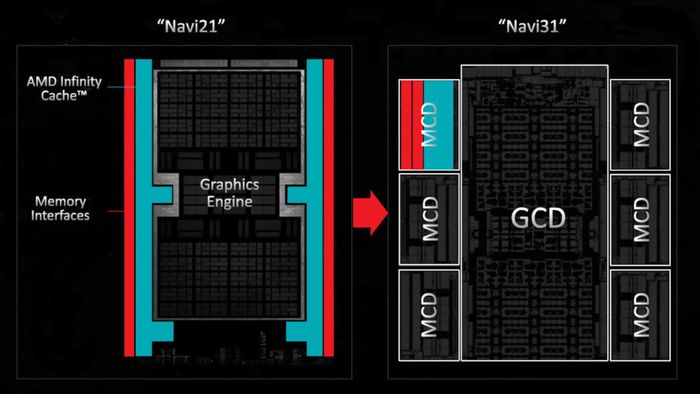 Trong kiến trúc Navi 31, có một GCD (Khuôn Phức hợp Đồ họa) chứa lõi và cache L2, và một MCD (Khuôn Phức hợp Bộ đệm) chứa các phần của cache L3 và bộ điều khiển bộ nhớ.
Đối với GPU, chúng chứa ít mạch analog hơn so với phần còn lại của khuôn, nhưng lượng SRAM bên trong đang tăng lên. Đây là lý do tại sao AMD đã áp dụng kiến thức về chiplet vào dòng Radeon 7000 mới nhất của mình, với GPU Radeon RX 7900 bao gồm nhiều chiplet – một khuôn lớn cho các lõi và cache L2, và năm hoặc sáu chiplet nhỏ khác, mỗi chiplet chứa một phần của cache L3 và bộ điều khiển bộ nhớ.
Dịch chuyển những thành phần này ra khỏi khuôn chính cho phép các kỹ sư tăng lượng mạch logic một cách đáng kể mà không cần phải sử dụng các tiến trình sản xuất mới nhất để kiểm soát kích thước chip. Tuy nhiên, thay đổi này không dẫn đến việc mở rộng danh mục card đồ họa, mặc dù nó có thể giúp giảm chi phí tổng thể.
Hiện tại, Intel và Nvidia không cho thấy bất kỳ dấu hiệu nào về việc theo đuổi thiết kế GPU giống như của AMD. Cả hai công ty đều sử dụng TSMC cho hoạt động sản xuất của mình và dường như họ hài lòng với việc sản xuất các chip lớn hơn, chuyển gánh nặng về chi phí sang người tiêu dùng.
Tuy nhiên, với sự suy giảm doanh thu liên tục trong lĩnh vực đồ họa, có vẻ như trong vài năm tới, mọi nhà sản xuất GPU sẽ tuân theo cùng một hướng đi.Thực hiện Định luật Moore thông qua thiết kế chipletBất kể khi nào những thay đổi này xảy ra, điều quan trọng là chúng phải xảy ra. Dù có những tiến bộ công nghệ đáng kể trong ngành sản xuất bán dẫn, nhưng vẫn tồn tại một giới hạn về việc thu nhỏ mỗi thành phần.
Để cải thiện hiệu suất của chip, kỹ sư có hai lựa chọn cơ bản – thêm mạch logic mới cùng bộ nhớ hỗ trợ và tăng tốc độ xung nhịp bên trong. Tốc độ xung nhịp của CPU trung bình đã ổn định trong nhiều năm qua. Ví dụ, chip FX-9590 của AMD từ năm 2013 có thể đạt tới 5 GHz trong một số ứng dụng, và tốc độ xung nhịp cao nhất trong các chip hiện tại của AMD là 5.7 GHz (với Ryzen 9 7950X).
Trong kiến trúc Navi 31, có một GCD (Khuôn Phức hợp Đồ họa) chứa lõi và cache L2, và một MCD (Khuôn Phức hợp Bộ đệm) chứa các phần của cache L3 và bộ điều khiển bộ nhớ.
Đối với GPU, chúng chứa ít mạch analog hơn so với phần còn lại của khuôn, nhưng lượng SRAM bên trong đang tăng lên. Đây là lý do tại sao AMD đã áp dụng kiến thức về chiplet vào dòng Radeon 7000 mới nhất của mình, với GPU Radeon RX 7900 bao gồm nhiều chiplet – một khuôn lớn cho các lõi và cache L2, và năm hoặc sáu chiplet nhỏ khác, mỗi chiplet chứa một phần của cache L3 và bộ điều khiển bộ nhớ.
Dịch chuyển những thành phần này ra khỏi khuôn chính cho phép các kỹ sư tăng lượng mạch logic một cách đáng kể mà không cần phải sử dụng các tiến trình sản xuất mới nhất để kiểm soát kích thước chip. Tuy nhiên, thay đổi này không dẫn đến việc mở rộng danh mục card đồ họa, mặc dù nó có thể giúp giảm chi phí tổng thể.
Hiện tại, Intel và Nvidia không cho thấy bất kỳ dấu hiệu nào về việc theo đuổi thiết kế GPU giống như của AMD. Cả hai công ty đều sử dụng TSMC cho hoạt động sản xuất của mình và dường như họ hài lòng với việc sản xuất các chip lớn hơn, chuyển gánh nặng về chi phí sang người tiêu dùng.
Tuy nhiên, với sự suy giảm doanh thu liên tục trong lĩnh vực đồ họa, có vẻ như trong vài năm tới, mọi nhà sản xuất GPU sẽ tuân theo cùng một hướng đi.Thực hiện Định luật Moore thông qua thiết kế chipletBất kể khi nào những thay đổi này xảy ra, điều quan trọng là chúng phải xảy ra. Dù có những tiến bộ công nghệ đáng kể trong ngành sản xuất bán dẫn, nhưng vẫn tồn tại một giới hạn về việc thu nhỏ mỗi thành phần.
Để cải thiện hiệu suất của chip, kỹ sư có hai lựa chọn cơ bản – thêm mạch logic mới cùng bộ nhớ hỗ trợ và tăng tốc độ xung nhịp bên trong. Tốc độ xung nhịp của CPU trung bình đã ổn định trong nhiều năm qua. Ví dụ, chip FX-9590 của AMD từ năm 2013 có thể đạt tới 5 GHz trong một số ứng dụng, và tốc độ xung nhịp cao nhất trong các chip hiện tại của AMD là 5.7 GHz (với Ryzen 9 7950X). Gần đây, Intel đã giới thiệu Core i9-13900KS, có thể đạt tới 6 GHz trong điều kiện thích hợp, nhưng hầu hết các chip của họ hiện tại đều có tốc độ xung nhịp tương đương với AMD.
Tuy nhiên, điều đã thay đổi là số lượng lõi và bộ nhớ SRAM. Chip FX-9590 đã đề cập trước đó có 8 lõi (và 8 luồng) và 8 MB bộ đệm L3, trong khi 7950X3D có 16 lõi, 32 luồng và 128 MB bộ đệm L3. CPU của Intel cũng mở rộng tương tự về số lõi và bộ nhớ SRAM.
GPU đầu tiên của Nvidia, G80, được ra mắt từ năm 2006, có 681 triệu bóng bán dẫn, 128 lõi và 96 kB bộ đệm L2 trong một con chip có diện tích 484 mm vuông. Nhảy về năm 2022, khi AD102 được giới thiệu, nó bao gồm 76.3 tỷ bóng bán dẫn, 18,432 lõi và 98,304 kB bộ nhớ đệm L2 trong khuôn diện tích 608 mm vuông.
Vào năm 1965, Gordon Moore, một trong những người sáng lập Fairchild Semiconductor, đã quan sát rằng trong những năm đầu tiên của việc sản xuất chip, mật độ các thành phần bên trong chip tăng gấp đôi mỗi năm với chi phí sản xuất tối thiểu cố định. Quan sát này đã trở thành Định luật Moore, được hiểu là 'số lượng bóng bán dẫn trong chip tăng gấp đôi sau mỗi hai năm', dựa trên xu hướng sản xuất.
Gần đây, Intel đã giới thiệu Core i9-13900KS, có thể đạt tới 6 GHz trong điều kiện thích hợp, nhưng hầu hết các chip của họ hiện tại đều có tốc độ xung nhịp tương đương với AMD.
Tuy nhiên, điều đã thay đổi là số lượng lõi và bộ nhớ SRAM. Chip FX-9590 đã đề cập trước đó có 8 lõi (và 8 luồng) và 8 MB bộ đệm L3, trong khi 7950X3D có 16 lõi, 32 luồng và 128 MB bộ đệm L3. CPU của Intel cũng mở rộng tương tự về số lõi và bộ nhớ SRAM.
GPU đầu tiên của Nvidia, G80, được ra mắt từ năm 2006, có 681 triệu bóng bán dẫn, 128 lõi và 96 kB bộ đệm L2 trong một con chip có diện tích 484 mm vuông. Nhảy về năm 2022, khi AD102 được giới thiệu, nó bao gồm 76.3 tỷ bóng bán dẫn, 18,432 lõi và 98,304 kB bộ nhớ đệm L2 trong khuôn diện tích 608 mm vuông.
Vào năm 1965, Gordon Moore, một trong những người sáng lập Fairchild Semiconductor, đã quan sát rằng trong những năm đầu tiên của việc sản xuất chip, mật độ các thành phần bên trong chip tăng gấp đôi mỗi năm với chi phí sản xuất tối thiểu cố định. Quan sát này đã trở thành Định luật Moore, được hiểu là 'số lượng bóng bán dẫn trong chip tăng gấp đôi sau mỗi hai năm', dựa trên xu hướng sản xuất. Đến nay, Định luật Moore vẫn là một mô tả khá chính xác về sự phát triển của ngành công nghiệp bán dẫn trong gần sáu thập kỷ. Sự tiến bộ về mạch logic và bộ nhớ trong cả CPU và GPU đã đạt được những thành tựu đáng kể nhờ vào các cải tiến liên tục trong các nút tiến trình, làm cho các thành phần trở nên nhỏ hơn qua mỗi năm.
Tuy nhiên, không thể mong chờ xu hướng này tiếp tục mãi mãi, bất kể công nghệ mới nổi ra sao.
Thay vì đợi đến giới hạn này, các công ty như AMD và Intel đã chuyển sang sử dụng chiplet, khám phá nhiều cách khác nhau để kết hợp chúng nhằm tiếp tục tiến tới trong việc tạo ra các bộ xử lý mạnh mẽ hơn bao giờ hết.
Trong những thập kỷ sắp tới, một chiếc PC trung bình có thể chứa các CPU và GPU có kích thước bằng bàn tay của bạn, nhưng khi gỡ bỏ bộ tản nhiệt, bạn sẽ tìm thấy một loạt các con chip nhỏ – không chỉ ba hoặc bốn, mà hàng chục con, tất cả được sắp xếp một cách tài tình như những ô gạch và xếp chồng lên nhau. Do đó, sự thống trị của chiplet chỉ mới bắt đầu.
Lược dịch từ bài viết của Nick Evanson trên TechSpot.
Đến nay, Định luật Moore vẫn là một mô tả khá chính xác về sự phát triển của ngành công nghiệp bán dẫn trong gần sáu thập kỷ. Sự tiến bộ về mạch logic và bộ nhớ trong cả CPU và GPU đã đạt được những thành tựu đáng kể nhờ vào các cải tiến liên tục trong các nút tiến trình, làm cho các thành phần trở nên nhỏ hơn qua mỗi năm.
Tuy nhiên, không thể mong chờ xu hướng này tiếp tục mãi mãi, bất kể công nghệ mới nổi ra sao.
Thay vì đợi đến giới hạn này, các công ty như AMD và Intel đã chuyển sang sử dụng chiplet, khám phá nhiều cách khác nhau để kết hợp chúng nhằm tiếp tục tiến tới trong việc tạo ra các bộ xử lý mạnh mẽ hơn bao giờ hết.
Trong những thập kỷ sắp tới, một chiếc PC trung bình có thể chứa các CPU và GPU có kích thước bằng bàn tay của bạn, nhưng khi gỡ bỏ bộ tản nhiệt, bạn sẽ tìm thấy một loạt các con chip nhỏ – không chỉ ba hoặc bốn, mà hàng chục con, tất cả được sắp xếp một cách tài tình như những ô gạch và xếp chồng lên nhau. Do đó, sự thống trị của chiplet chỉ mới bắt đầu.
Lược dịch từ bài viết của Nick Evanson trên TechSpot.