
DALL-E 2 thể hiện sức mạnh của học sâu tạo sinh, nhưng gây tranh cãi về các thực hành trí tuệ nhân tạo

Bài viết này là một phần của sự theo dõi của chúng tôi về những điều mới nhất trong nghiên cứu AI.
Trung tâm nghiên cứu trí tuệ nhân tạo OpenAI lại khiến dư luận xôn xao, lần này với DALL-E 2, một mô hình học máy có khả năng tạo ra những hình ảnh tuyệt vời từ mô tả văn bản. DALL-E 2 xây dựng trên sự thành công của người tiền nhiệm của mình, DALL-E, và cải thiện chất lượng và độ phân giải của hình ảnh đầu ra nhờ các kỹ thuật học sâu tiên tiến.
Thông báo về DALL-E 2 đi kèm với chiến dịch truyền thông trên mạng xã hội do các kỹ sư của OpenAI và CEO Sam Altman chia sẻ những bức ảnh tuyệt vời được tạo ra bởi mô hình học máy sinh sáng trên Twitter.
DALL-E 2 cho thấy cộng đồng nghiên cứu trí tuệ nhân tạo đã đi xa trong việc khai thác sức mạnh của học sâu và giải quyết một số giới hạn của nó. Nó cũng mở ra cái nhìn về cách mô hình học sâu sinh sáng có thể mở khóa các ứng dụng sáng tạo mới cho mọi người sử dụng. Đồng thời, nó nhắc nhở chúng ta về một số khó khăn vẫn còn trong nghiên cứu trí tuệ nhân tạo và những tranh cãi cần được giải quyết.
Vẻ đẹp của DALL-E 2
Giống như các thông báo quan trọng khác của OpenAI, DALL-E 2 đi kèm với một bài báo chi tiết và một bài đăng blog tương tác hiển thị cách mô hình học máy hoạt động. Cũng có một video cung cấp tổng quan về khả năng của công nghệ và giới hạn của nó.
DALL-E 2 là một 'mô hình sinh sáng', một nhánh đặc biệt của học máy tạo ra đầu ra phức tạp thay vì thực hiện các nhiệm vụ dự đoán hoặc phân loại trên dữ liệu đầu vào. Bạn cung cấp DALL-E 2 mô tả văn bản và nó tạo ra một hình ảnh phù hợp với mô tả.
Các mô hình sinh sáng là một lĩnh vực nóng trong nghiên cứu đã nhận được nhiều sự chú ý với sự giới thiệu của mạng đ對抗 nhiễu sinh (GAN) vào năm 2014. Lĩnh vực này đã có những cải tiến đáng kể trong những năm gần đây, và các mô hình sinh sáng đã được sử dụng cho nhiều nhiệm vụ đa dạng, bao gồm tạo ra khuôn mặt nhân tạo, deepfake, giọng nói tổng hợp và nhiều nhiệm vụ khác.
Tuy nhiên, điều làm DALL-E 2 nổi bật so với các mô hình sinh sáng khác là khả năng duy trì tính nhất quán ngữ nghĩa trong các hình ảnh nó tạo ra.
Ví dụ, những hình ảnh sau (từ bài đăng blog của DALL-E 2) được tạo ra từ mô tả 'Một phi hành gia đang cưỡi một con ngựa'. Một trong những mô tả kết thúc bằng 'như một bức vẽ bằng bút chì' và cái khác 'theo phong cách chân dung thực tế'

Mô hình duy trì sự nhất quán trong cách vẽ người phi hành gia ngồi trên lưng con ngựa và giữ tay phía trước. Loại nhất quán này thể hiện trong hầu hết các ví dụ mà OpenAI đã chia sẻ.
Các ví dụ dưới đây (cũng từ trang web của OpenAI) cho thấy một tính năng khác của DALL-E 2, đó là tạo ra các biến thể của một hình ảnh đầu vào. Ở đây, thay vì cung cấp cho DALL-E 2 mô tả văn bản, bạn cung cấp cho nó một hình ảnh và nó cố gắng tạo ra các hình dạng khác của cùng một hình ảnh. Ở đây, DALL-E duy trì các mối quan hệ giữa các yếu tố trong hình ảnh, bao gồm cô gái, laptop, tai nghe, con mèo, đèn thành phố phía sau và bầu trời đêm với mặt trăng và đám mây.

Các ví dụ khác cho thấy rằng DALL-E 2 có vẻ hiểu về chiều sâu và chiều sâu, một thách thức lớn đối với các thuật toán xử lý hình ảnh 2D.
Ngay cả khi các ví dụ trên trang web của OpenAI đã được lựa chọn kỹ lưỡng, chúng vẫn ấn tượng. Và những ví dụ được chia sẻ trên Twitter cho thấy rằng DALL-E 2 có vẻ đã tìm ra cách biểu diễn và sao chép các mối quan hệ giữa các yếu tố xuất hiện trong một hình ảnh, ngay cả khi nó đang 'mơ' ra điều gì đó lần đầu tiên.
Thực tế, để chứng minh tài năng của DALL-E 2, Altman đã đăng trên Twitter và yêu cầu người dùng đề xuất yêu cầu để đưa vào mô hình sáng tạo. Kết quả (xem chuỗi dưới đây) rất thú vị.
Khoa học đằng sau DALL-E 2
DALL-E 2 tận dụng CLIP và mô hình diffusion, hai kỹ thuật học sâu tiên tiến được tạo ra trong vài năm qua. Nhưng ở tâm hồn, nó chia sẻ cùng một khái niệm như tất cả các mạng neural sâu khác: học biểu diễn.
Lý tưởng, mô hình máy học nên có thể học các đặc trưng tiềm ẩn giữ nguyên qua các điều kiện ánh sáng, góc nhìn và môi trường nền khác nhau. Nhưng như thường thấy, các mô hình học sâu thường học những biểu diễn sai lầm. Ví dụ, một mạng neural có thể nghĩ rằng các pixel màu xanh lá cây là một đặc trưng của lớp “cừu” vì tất cả các hình ảnh cừu nó đã thấy trong quá trình đào tạo đều chứa nhiều cỏ. Một mô hình khác đã được đào tạo trên các hình ảnh của dơi được chụp vào ban đêm có thể coi bóng tối là một đặc trưng của tất cả các hình ảnh dơi và phân loại sai hình ảnh dơi được chụp vào ban ngày. Những mô hình khác có thể trở nên nhạy cảm với việc các đối tượng được tập trung ở giữa hình ảnh và đặt trước một loại nền nhất định.
Việc học những biểu diễn sai lầm là một phần lý do tại sao các mạng neural dễ vỡ, nhạy cảm với các thay đổi trong môi trường và kém chung nhận diện vượt ra khỏi dữ liệu đào tạo của chúng. Điều này cũng là lý do tại sao các mạng neural được đào tạo cho một ứng dụng cần phải điều chỉnh lại cho các ứng dụng khác — các đặc trưng của các lớp cuối cùng của mạng neural thường rất cụ thể cho một nhiệm vụ và không thể tổng quát hóa được cho các ứng dụng khác.
Lý thuyết, bạn có thể tạo một bộ dữ liệu đào tạo lớn chứa mọi loại biến thể dữ liệu mà mạng neural nên có thể xử lý. Nhưng việc tạo và gán nhãn cho một bộ dữ liệu như vậy sẽ đòi hỏi sự nỗ lực của con người lớn và là không thực tế.
Đây là vấn đề mà Contrastive Learning-Image Pre-training (CLIP) giải quyết. CLIP đào tạo hai mạng neural song song trên hình ảnh và chú thích của chúng. Một trong những mạng học các biểu diễn hình ảnh và một mạng khác học các biểu diễn của văn bản tương ứng. Trong quá trình đào tạo, hai mạng cố gắng điều chỉnh các tham số của chúng để những hình ảnh và mô tả tương tự tạo ra các nhúng tương tự.
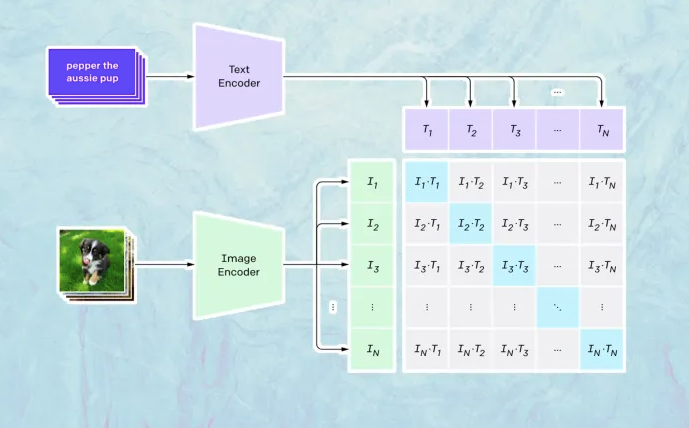 Contrastive Learning — Image Pre-training
Contrastive Learning — Image Pre-trainingMột trong những lợi ích chính của CLIP là nó không cần phải có nhãn cho dữ liệu đào tạo của mình cho một ứng dụng cụ thể. Nó có thể được đào tạo trên số lượng lớn hình ảnh và mô tả mơ hồ có thể được tìm thấy trên web. Ngoài ra, mà không có ranh giới cứng của các danh mục cổ điển, CLIP có thể học các biểu diễn linh hoạt hơn và tổng quát hóa cho nhiều nhiệm vụ. Ví dụ, nếu một hình ảnh được mô tả là “một bé trai ôm một chú chó con” và một hình ảnh khác được mô tả là “một bé trai đang cưỡi một con ngựa,” mô hình sẽ có thể học một biểu diễn mạnh mẽ hơn về “bé trai” là gì và cách nó liên quan đến các yếu tố khác trong hình ảnh.
CLIP đã chứng minh được rất hữu ích cho học một lần vài lần, nơi mà một mô hình máy học được hiển thị ngay lập tức để thực hiện các nhiệm vụ mà nó chưa được đào tạo.
Kỹ thuật máy học khác được sử dụng trong DALL-E 2 là “diffusion,” một loại mô hình sinh tạo học cách tạo ra hình ảnh bằng cách dần dần làm ồn và giảm nhiễu các ví dụ đào tạo của nó. Mô hình diffusion tương tự như autoencoders, biến dữ liệu đầu vào thành biểu diễn nhúng và sau đó tái tạo dữ liệu gốc từ thông tin nhúng.
DALL-E đào tạo một mô hình CLIP trên hình ảnh và chú thích. Sau đó, nó sử dụng mô hình CLIP để đào tạo mô hình diffusion. Đơn giản, mô hình diffusion sử dụng mô hình CLIP để tạo các nhúng cho yêu cầu văn bản và hình ảnh tương ứng của nó. Sau đó, nó cố gắng tạo ra hình ảnh tương ứng với văn bản.
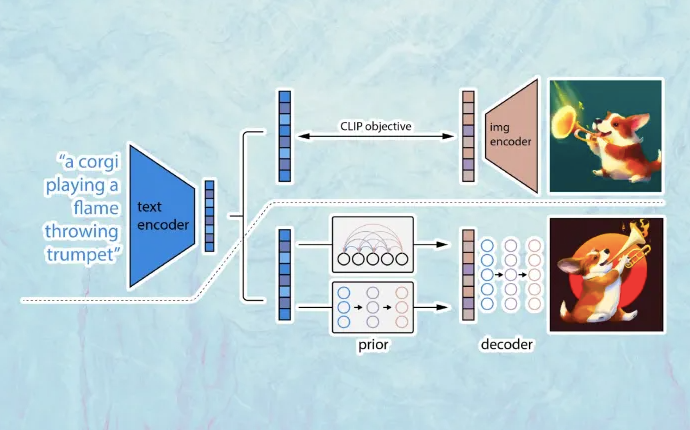 DALL-E 2 architecture<img loading="lazy" class="wp-image-1384787" src="https://cdn0.tnwcdn.com/wp-content/blogs.dir/1/files/2022/04/Screen-Shot-2022-04-15-at-15.33.51.png" alt="DALL-E 2" width="911" height="568" srcset="https://cdn0.tnwcdn.com/wp-content/blogs.dir/1/files/2022/04/Screen-Shot-2022-04-15-at-15.33.51.png 690w, https://cdn0.tnwcdn.com/wp-content/blogs.dir/1/files/2022/04/Screen-Shot-2022-04-15-at-15.33.51-280x174.png 280w, https://cdn0.tnwcdn.com/wp-content/blogs.dir/1/files/2022/04/Screen-Shot-2022-04-15-at-15.33.51-217x135.png 217w, https://cdn0.tnwcdn.com/wp-content/blogs.dir/1/files/2022/04/Screen-Shot-2022-04-15-at-15.33.51-433x270.png 433w">
DALL-E 2 architecture<img loading="lazy" class="wp-image-1384787" src="https://cdn0.tnwcdn.com/wp-content/blogs.dir/1/files/2022/04/Screen-Shot-2022-04-15-at-15.33.51.png" alt="DALL-E 2" width="911" height="568" srcset="https://cdn0.tnwcdn.com/wp-content/blogs.dir/1/files/2022/04/Screen-Shot-2022-04-15-at-15.33.51.png 690w, https://cdn0.tnwcdn.com/wp-content/blogs.dir/1/files/2022/04/Screen-Shot-2022-04-15-at-15.33.51-280x174.png 280w, https://cdn0.tnwcdn.com/wp-content/blogs.dir/1/files/2022/04/Screen-Shot-2022-04-15-at-15.33.51-217x135.png 217w, https://cdn0.tnwcdn.com/wp-content/blogs.dir/1/files/2022/04/Screen-Shot-2022-04-15-at-15.33.51-433x270.png 433w">Tranh cãi về học sâu và nghiên cứu trí tuệ nhân tạo
Hiện tại, DALL-E 2 chỉ sẽ được cung cấp cho một số người dùng có đăng ký trong danh sách chờ. Kể từ khi phát hành GPT-2, OpenAI đã do dự trong việc phát hành các mô hình AI của mình cho công chúng. GPT-3, mô hình ngôn ngữ tiên tiến nhất của họ, chỉ có sẵn thông qua giao diện API. Không có quyền truy cập vào mã nguồn và tham số thực tế của mô hình.
Chính sách của OpenAI không phát hành các mô hình của mình cho công chúng đã không được cộng đồng trí tuệ nhân tạo đánh giá cao và đã thu hút sự chỉ trích từ một số nhân vật nổi tiếng trong lĩnh vực này.
DALL-E 2 cũng đã làm nổi lên một số mâu thuẫn lâu dài về cách tiế approach ưa thích đối với trí tuệ nhân tạo tổng quát. Điều đột phá mới nhất của OpenAI đã chắc chắn chứng minh rằng với kiến trúc phù hợp và độ chệch quy nạp, bạn vẫn có thể nén xuống nhiều hơn từ các mạng neural.
Những người ủng hộ các phương pháp học sâu thuần túy đã nhảy vào cơ hội để mỉa mai đối thủ của họ, bao gồm một bài luận gần đây của nhà tâm thần học Gary Marcus mang tựa đề, “Deep Learning is Hitting a Wall.” Marcus ủng hộ một phương pháp lai kết hợp mạng neural với hệ thống biểu tượng.
Dựa trên các ví dụ đã được đội ngũ OpenAI chia sẻ, DALL-E 2 dường như thể hiện một số khả năng thông thường đã thiếu hụt trong học sâu lâu nay. Nhưng vẫn cần phải xem cách mức độ thông thường và ổn định ngữ nghĩa đi xa đến đâu, và làm thế nào DALL-E 2 và những người kế nhiệm của nó sẽ đối phó với các khái niệm phức tạp như hợp thành.
Bài báo DALL-E 2 đề cập đến một số hạn chế của mô hình trong việc tạo văn bản và cảnh phức tạp. Đáp lại các tweet nhiều đến anh, Marcus chỉ ra rằng thực tế bài báo DALL-E 2 chứng minh một số điểm anh đã đưa ra trong các bài báo và tiểu luận của mình.
Một số nhà khoa học đã chỉ ra rằng bất kể kết quả thú vị của DALL-E 2, một số thách thức chính của trí tuệ nhân tạo vẫn chưa được giải quyết. Melanie Mitchell, Giáo sư tại Viện nghiên cứu Santa Fe và tác giả của Trí tuệ nhân tạo: Hướng dẫn cho những người suy nghĩ, đưa ra một số câu hỏi quan trọng trong một chuỗi tweet.
Mitchell đề cập đến vấn đề Bongard, một bộ thách thức kiểm tra sự hiểu biết về các khái niệm như sự giống nhau, kề cận, số lượng, hòn đá cô lập/đóng cửa.
“Chúng ta con người có thể giải quyết những câu đố hình ảnh này nhờ vào kiến thức cơ bản và khả năng trừu tượng linh hoạt và so sánh của chúng ta,” Mitchell tweet. “Nếu một hệ thống AI như vậy được tạo ra, tôi sẽ tin rằng lĩnh vực này đang đạt được tiến triển thực sự về trí tuệ cấp độ con người. Cho đến khi đó, tôi sẽ ngưỡng mộ những sản phẩm ấn tượng của học máy và dữ liệu lớn, nhưng sẽ không nhầm lẫn chúng với tiến triển về trí tuệ tổng quát.”
Trường hợp kinh doanh cho DALL-E 2
Kể từ khi chuyển từ tổ chức phi lợi nhuận sang mô hình lợi nhuận có giới hạn, OpenAI đã cố gắng đạt được sự cân bằc giữa nghiên cứu khoa học và phát triển sản phẩm. Đối tác chiến lược của công ty với Microsoft đã mang lại cho nó các kênh mạnh mẽ để thương mại hóa một số công nghệ của mình, bao gồm GPT-3 và Codex.
Trong một bài đăng trên blog, Altman đề xuất một khả năng ra mắt sản phẩm DALL-E 2 vào mùa hè. Nhiều nhà phân tích đã đề xuất các ứng dụng cho DALL-E 2, như tạo đồ họa cho các bài viết (tôi nhất định có thể sử dụng một số cho bài viết của tôi) và chỉnh sửa cơ bản trên hình ảnh. DALL-E 2 sẽ giúp nhiều người thể hiện sự sáng tạo của họ mà không cần kỹ năng đặc biệt với các công cụ.
Altman cho rằng tiến bộ trong trí tuệ nhân tạo đang dẫn chúng ta đến “một thế giới trong đó ý tưởng tốt là giới hạn cho những gì chúng ta có thể làm, chứ không phải là kỹ năng cụ thể.”
Trong mọi trường hợp, những ứng dụng thú vị hơn của DALL-E sẽ xuất hiện khi càng nhiều người dùng thử nghiệm nó. Ví dụ, ý tưởng cho Copilot và Codex xuất hiện khi người dùng bắt đầu sử dụng GPT-3 để tạo mã nguồn cho phần mềm.
Nếu OpenAI phát hành một dịch vụ API trả phí theo mô hình của GPT-3, thì ngày càng nhiều người sẽ có khả năng xây dựng ứng dụng với DALL-E 2 hoặc tích hợp công nghệ này vào các ứng dụng hiện tại. Nhưng như đã xảy ra với GPT-3, xây dựng một mô hình kinh doanh xung quanh sản phẩm DALL-E 2 tiềm năng sẽ đối mặt với những thách thức riêng của nó. Rất nhiều điều sẽ phụ thuộc vào chi phí đào tạo và vận hành DALL-E 2, chi tiết chưa được công bố.
Và với tư cách là chủ sở hữu giấy phép độc quyền của công nghệ GPT-3, Microsoft sẽ là người chiến thắng chính của mọi đổi mới xây dựng trên nền tảng DALL-E 2 vì nó có thể làm điều này nhanh chóng và hiệu quả chi phí. Như GPT-3, DALL-E 2 là một lời nhắc rằng khi cộng đồng AI tiếp tục hướng tới việc đào tạo các mạng nơ-ron lớn hơn trên tập dữ liệu đào tạo ngày càng lớn hơn, quyền lực sẽ tiếp tục được tập trung trong vài công ty rất giàu có có tài nguyên tài chính và kỹ thuật cần thiết cho nghiên cứu AI.
Bài viết gốc của Ben Dickson đã được xuất bản trên TechTalks, một xuất bản phẩm nghiên cứu các xu hướng trong công nghệ, cách chúng ảnh hưởng đến cuộc sống và kinh doanh của chúng ta, và những vấn đề mà chúng giải quyết. Nhưng chúng tôi cũng thảo luận về mặt tối của công nghệ, những hậu quả tăm tối của công nghệ mới, và những điều chúng ta cần phải để ý. Bạn có thể đọc bài viết gốc tại đây.