
Nghiên cứu của Google: Học không giám sát đang biến đổi hình ảnh y học
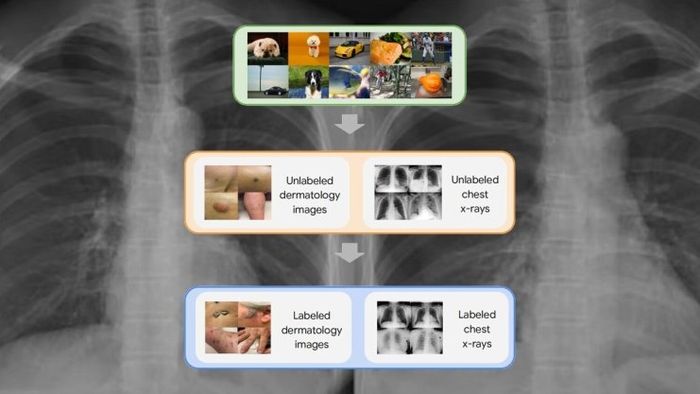
Deep learning hứa hẹn rất nhiều trong lĩnh vực chăm sóc sức khỏe, đặc biệt là trong hình ảnh y học, nơi mà nó có thể giúp cải thiện tốc độ và độ chính xác trong việc chẩn đoán tình trạng của bệnh nhân. Nhưng nó cũng đối mặt với một rào cản nghiêm trọng: Sự thiếu hụt dữ liệu huấn luyện có nhãn.
Trong ngữ cảnh y học, dữ liệu huấn luyện tạo ra chi phí lớn, điều này làm cho việc sử dụng deep learning trở nên rất khó khăn cho nhiều ứng dụng.
Để vượt qua rào cản này, các nhà khoa học đã khám phá các giải pháp khác nhau với mức độ thành công khác nhau. Trong một bài báo mới, các nhà nghiên cứu trí tuệ nhân tạo tại Google đề xuất một kỹ thuật mới sử dụng học không giám sát để huấn luyện các mô hình deep learning cho hình ảnh y học. Kết quả ban đầu cho thấy rằng kỹ thuật này có thể giảm thiểu nhu cầu về dữ liệu có nhãn và cải thiện hiệu suất của các mô hình deep learning trong các ứng dụng y học.
Huấn luyện trước có giám sát
Mạng neural tích chập (CNN) đã chứng minh sự hiệu quả rất cao trong các nhiệm vụ thị giác máy tính. Google là một trong số nhiều tổ chức đã khám phá việc sử dụng nó trong hình ảnh y học. Trong những năm gần đây, phòng nghiên cứu của công ty đã xây dựng nhiều mô hình hình ảnh y học trong các lĩnh vực như mắt học, da liễu, chụp X vú và bệnh lý.
“Có rất nhiều sự hứng thú xung quanh việc áp dụng học sâu vào lĩnh vực y tế, nhưng vẫn còn đầy thách thức vì cần có các mô hình DL chính xác và mạnh mẽ trong lĩnh vực như y tế,” Shekoofeh Azizi, cư dân trí tuệ nhân tạo tại Google Research và tác giả chính của bài báo tự học, nói với TechTalks.
Một trong những thách thức chính của học sâu là cần có lượng dữ liệu được chú thích lớn. Mạng neural lớn yêu cầu hàng triệu ví dụ được gắn nhãn để đạt được độ chính xác tối ưu. Trong cài đặt y tế, việc đánh dấu dữ liệu là một công việc phức tạp và tốn kém.
“Việc có được những “nhãn” này trong môi trường y tế đầy thách thức vì nhiều lý do: nó có thể tốn thời gian và tốn kém cho các chuyên gia lâm sàng, và dữ liệu phải đáp ứng các yêu cầu về quyền riêng tư liên quan trước khi được chia sẻ,” Azizi nói.
Đối với một số điều kiện, các ví dụ rất hiếm khi bắt đầu, và trong một số trường hợp khác, như sàng lọc ung thư vú, có thể mất nhiều năm để các kết quả lâm sàng hiện ra sau khi một hình ảnh y tế được chụp.
Làm phức tạp thêm yêu cầu dữ liệu của các ứng dụng hình ảnh y học là các thay đổi phân phối giữa dữ liệu huấn luyện và môi trường triển khai, như sự thay đổi trong dân số bệnh nhân, sự phổ biến hoặc trình bày của bệnh, và công nghệ y tế được sử dụng cho việc chụp ảnh, Azizi bổ sung.
Một cách phổ biến để giải quyết thiếu hụt dữ liệu y tế là sử dụng huấn luyện trước có giám sát. Trong phương pháp này, một CNN ban đầu được huấn luyện trên một tập dữ liệu hình ảnh được gắn nhãn như ImageNet. Giai đoạn này điều chỉnh các tham số của các lớp mô hình theo các mẫu chung được tìm thấy trong tất cả các loại hình ảnh. Mô hình học sâu đã được huấn luyện sau đó có thể được tinh chỉnh trên một tập hợp hữu hạn các ví dụ được gắn nhãn cho nhiệm vụ mục tiêu.
Nhiều nghiên cứu đã chỉ ra rằng huấn luyện trước có giám sát có ích trong các ứng dụng như hình ảnh y tế, nơi dữ liệu được gắn nhãn ít. Tuy nhiên, huấn luyện trước có giám sát cũng có những hạn chế riêng của nó.
“Mô hình thông thường để huấn luyện các mô hình hình ảnh y tế là học chuyển giao, trong đó các mô hình được huấn luyện trước đầu tiên bằng học có giám sát trên ImageNet. Tuy nhiên, có một sự thay đổi lớn về miền giữa hình ảnh tự nhiên trong ImageNet và hình ảnh y tế, và nghiên cứu trước đây đã chỉ ra rằng việc huấn luyện trước có giám sát trên ImageNet có thể không tối ưu cho việc phát triển các mô hình hình ảnh y tế,” Azizi nói.
Huấn luyện trước tự giám sát
Học tự giám sát đã nổi lên như một lĩnh vực nghiên cứu hứa hẹn trong những năm gần đây. Trong học tự giám sát, các mô hình học sâu học các biểu diễn của dữ liệu huấn luyện mà không cần nhãn. Nếu thực hiện đúng, học tự giám sát có thể mang lại lợi ích lớn trong các miền nơi dữ liệu được gắn nhãn ít và dữ liệu chưa gắn nhãn là dồi dào.
Bên ngoài các cài đặt y tế, Google đã phát triển một số kỹ thuật học tự giám sát để huấn luyện mạng neural cho các nhiệm vụ thị giác máy tính. Trong đó có Simple Framework for Contrastive Learning (SimCLR), được trình bày tại hội nghị ICML 2020. Học thông qua so sánh sử dụng các cắt và biến thể khác nhau của cùng một hình ảnh để huấn luyện mạng neural cho đến khi nó học được các biểu diễn mạnh mẽ chống lại sự thay đổi.
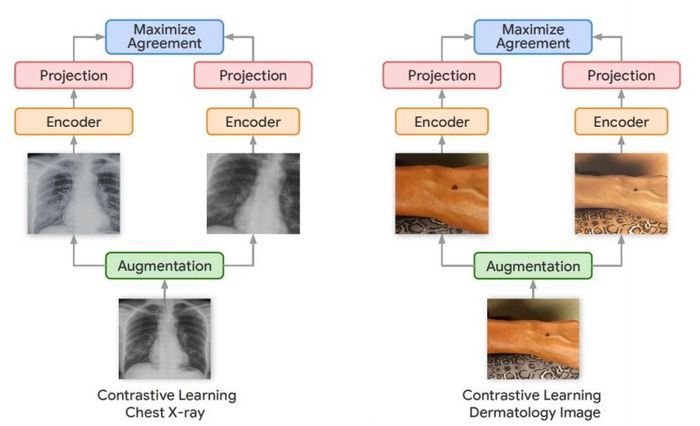
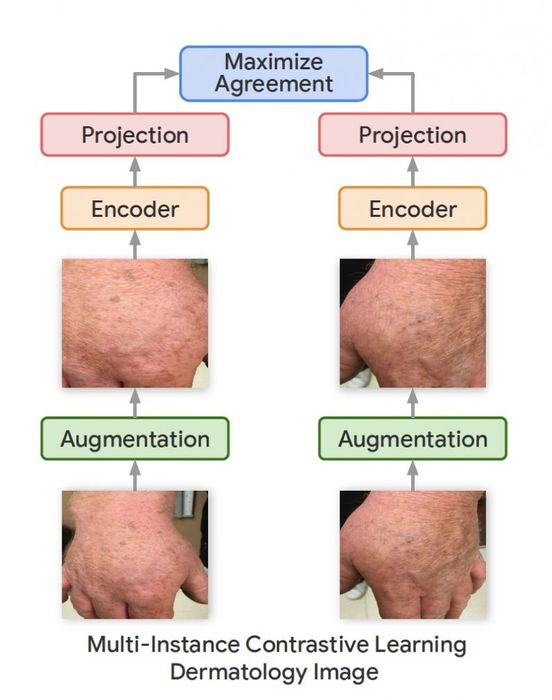
Trong công việc mới của họ, nhóm nghiên cứu Google đã sử dụng một biến thể của khung SimCLR được gọi là Multi-Instance Contrastive Learning (MICLe), học các biểu diễn mạnh mẽ hơn bằng cách sử dụng nhiều hình ảnh của cùng một điều kiện. Điều này thường xảy ra trong các tập dữ liệu y tế, nơi có nhiều hình ảnh của cùng một bệnh nhân, mặc dù các hình ảnh có thể không được gắn nhãn cho việc học có giám sát.
“Dữ liệu không được gắn nhãn thường có sẵn với số lượng lớn trong các lĩnh vực y tế khác nhau. Một điểm khác biệt quan trọng là chúng tôi sử dụng nhiều quan điểm của bệnh lý cơ bản thường có trong tập dữ liệu hình ảnh y tế để xây dựng các cặp hình ảnh cho việc học tự giám sát thông qua so sánh,” Azizi nói.
Khi một mô hình học sâu tự giám sát được huấn luyện trên các góc nhìn khác nhau của cùng một mục tiêu, nó học được các biểu diễn mạnh mẽ hơn đối với sự thay đổi trong góc nhìn, điều kiện hình ảnh và các yếu tố khác có thể ảnh hưởng tiêu cực đến hiệu suất của nó.
Tổng kết
Khung học tự giám sát mà các nhà nghiên cứu Google sử dụng bao gồm ba bước. Đầu tiên, mạng neural mục tiêu được huấn luyện trên các ví dụ từ tập dữ liệu ImageNet bằng cách sử dụng SimCLR. Tiếp theo, mô hình được huấn luyện thêm bằng MICLe trên một tập dữ liệu y tế có nhiều hình ảnh cho mỗi bệnh nhân. Cuối cùng, mô hình được điều chỉnh tinh chỉnh trên một tập dữ liệu hạn chế các hình ảnh được gắn nhãn cho ứng dụng mục tiêu.
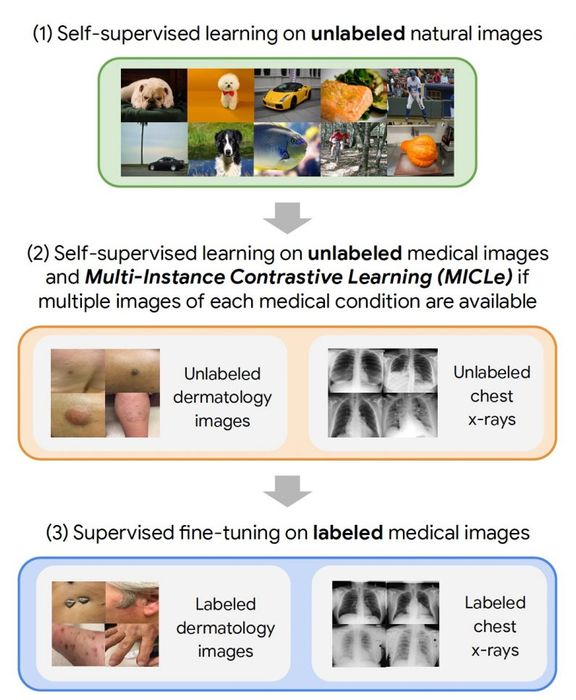
Các nhà nghiên cứu đã kiểm tra khung hình ảnh trên hai nhiệm vụ phân tích da liễu và tia X ngực. So với việc huấn luyện trước có giám sát, phương pháp tự giám sát cung cấp cải thiện đáng kể về độ chính xác, hiệu suất nhãn và khái quát hóa ngoài phân phối của các mô hình hình ảnh y tế, điều này đặc biệt quan trọng cho các ứng dụng lâm sàng. Và nó yêu cầu ít dữ liệu được gắn nhãn hơn nhiều.
“Sử dụng học tự giám sát, chúng tôi đã chỉ ra rằng chúng ta có thể giảm đáng kể nhu cầu về dữ liệu được gắn nhãn đắt tiền để xây dựng các mô hình phân loại hình ảnh y tế,” Azizi nói. Đặc biệt, trong nhiệm vụ da liễu, họ đã có thể huấn luyện các mạng neural để phù hợp với hiệu suất mô hình cơ sở khi chỉ sử dụng một năm phần tư dữ liệu được gắn nhãn.
“Hy vọng điều này sẽ dẫn đến việc tiết kiệm đáng kể về chi phí và thời gian cho việc phát triển các mô hình trí tuệ nhân tạo trong lĩnh vực y tế. Chúng tôi hy vọng phương pháp này sẽ truyền cảm hứng cho các nghiên cứu trong các ứng dụng chăm sóc sức khỏe mới, nơi việc có được dữ liệu được gắn nhãn đã gặp khó khăn,” Azizi nói.
Bài viết này được ban đầu xuất bản bởi Ben Dickson trên TechTalks, một trang xuất bản nghiên cứu xu hướng trong công nghệ, cách chúng ảnh hưởng đến cách chúng ta sống và kinh doanh, cũng như các vấn đề mà chúng giải quyết. Nhưng chúng tôi cũng thảo luận về mặt xấu của công nghệ, những hậu quả đen tối của công nghệ mới và những điều chúng ta cần phải cảnh giác. Bạn có thể đọc bài viết gốc tại đây.