
Google đang giảng dạy trí tuệ nhân tạo 'nhìn' và 'nghe' cùng một lúc — đây là lý do quan trọng
Một nhóm nhà khoa học từ Google Research, Viện Alan Turing và Đại học Cambridge vừa giới thiệu một mô hình biến đổi đa phương tiện mới (SOTA) tiên tiến cho trí tuệ nhân tạo.
Nói cách khác, họ đang dạy trí tuệ nhân tạo cách 'nghe' và 'nhìn' đồng thời.
Ở phía trước: Bạn có thể đã nghe về các hệ thống trí tuệ nhân tạo như GPT-3. Ở cơ bản, chúng xử lý và phân loại dữ liệu từ một loại luồng truyền thông cụ thể.
Dưới dạng mô hình tiên tiến hiện tại, nếu bạn muốn phân tích dữ liệu từ một video, bạn cần nhiều mô hình trí tuệ nhân tạo đang chạy đồng thời.
Bạn sẽ cần một mô hình được đào tạo trên video và một mô hình khác được đào tạo trên đoạn âm thanh. Điều này là vì, giống như tai và mắt của bạn là hai hệ thống khác nhau (nhưng liên kết), các thuật toán cần thiết để xử lý các loại âm thanh khác nhau thường khác với những thuật toán được sử dụng để xử lý video.
Theo bài báo của đội:
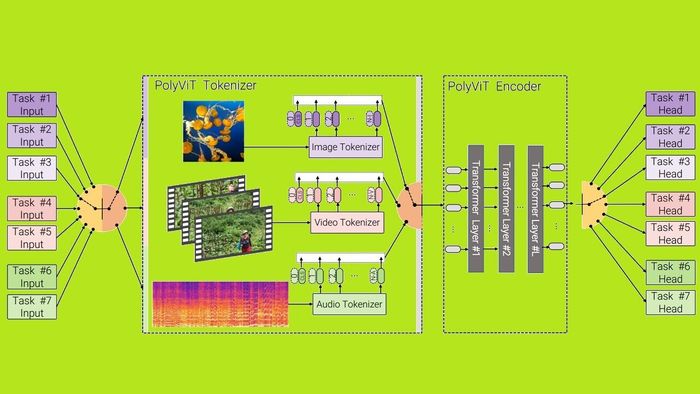
Mặc dù có những tiến bộ gần đây ở nhiều lĩnh vực và nhiệm vụ khác nhau, các phương pháp hiện đại nhất hiện tại đào tạo một mô hình riêng biệt với các tham số mô hình khác nhau cho mỗi nhiệm vụ. Trong công việc này, chúng tôi trình bày một phương pháp đơn giản nhưng hiệu quả để đào tạo một mô hình đồng nhất duy nhất mà đạt được kết quả cạnh tranh, hoặc hiện đại nhất cho việc phân loại hình ảnh, video và âm thanh.
Bối cảnh: Điều đáng kinh ngạc ở đây là đội ngũ không chỉ có khả năng xây dựng một hệ thống đa phương tiện có thể xử lý các nhiệm vụ liên quan cùng một lúc, mà trong quá trình đó họ đã vượt qua các mô hình SOTA hiện tại tập trung vào một nhiệm vụ duy nhất.
Nhóm nghiên cứu đặt tên hệ thống của họ là “PolyVit.” Và theo họ, hiện nó hiện không có đối thủ:
Bằng cách đào tạo các nhiệm vụ khác nhau trên một modal, chúng tôi có thể cải thiện độ chính xác của từng nhiệm vụ cá nhân và đạt được kết quả hiện đại trên 5 bộ dữ liệu phân loại video và âm thanh tiêu chuẩn. Việc đào tạo PolyViT trên nhiều modal và nhiệm vụ dẫn đến một mô hình có hiệu suất tham số thậm chí cao hơn và học biểu diễn tổng quát trên nhiều lĩnh vực.
Hơn nữa, chúng tôi cho thấy rằng việc đào tạo cùng một lúc là đơn giản và thực tế để triển khai, vì chúng tôi không cần điều chỉnh siêu tham số cho mỗi kết hợp bộ dữ liệu, mà chỉ cần điều chỉnh từ quy trình đào tạo tiêu chuẩn của một nhiệm vụ duy nhất.
Quan điểm nhanh: Điều này có thể là một vấn đề lớn cho thế giới kinh doanh. Một trong những vấn đề lớn nhất mà các công ty hy vọng triển khai các ngăn xếp trí tuệ nhân tạo đối mặt là tính tương thích. Có hàng trăm giải pháp máy học và không có đảm bảo rằng chúng sẽ hoạt động cùng nhau.
Điều này dẫn đến các triển khai độc quyền nơi các nhà lãnh đạo IT bị kẹt với một nhà cung cấp duy nhất vì lợi ích của tính tương thích hoặc một phương pháp mix-and-match mang theo nhiều vấn đề phiền toái hơn nó giá trị.
Một mô hình trong đó các hệ thống đa phương tiện trở thành tiêu chuẩn sẽ là một điều cứu rỗi cho các quản trị viên mệt mỏi.
Tất nhiên, đây chỉ là nghiên cứu sớm từ một bài báo pre-print nên không có lý do gì để tin rằng chúng ta sẽ thấy điều này được triển khai rộng rãi trong thời gian sớm.
Nhưng đó là một bước quan trọng hướng tới một hệ thống phân loại một kích thước vừa vặn tất cả, và điều đó thật sự là điều hứng thú.
Hỗ trợ từ: Synced