

Hệ cơ sở dữ liệu (tiếng Anh: Database) là tập hợp dữ liệu có cấu trúc và liên kết với nhau, thường được lưu trữ và truy cập qua hệ thống máy tính. Khi cơ sở dữ liệu trở nên phức tạp hơn, chúng thường được thiết kế bằng các phương pháp và mô hình hóa chính thức.
Về mặt vật lý, các máy chủ cơ sở dữ liệu là các máy tính chuyên dụng lưu trữ cơ sở dữ liệu thực tế và chỉ chạy DBMS cùng phần mềm liên quan. Những máy chủ này thường là máy tính đa bộ xử lý, có bộ nhớ rộng rãi và sử dụng hệ thống đĩa RAID để đảm bảo lưu trữ ổn định. RAID giúp phục hồi dữ liệu nếu có lỗi đĩa. Các bộ tăng tốc phần cứng, kết nối qua kênh tốc độ cao, cũng được sử dụng trong các môi trường xử lý giao dịch khối lượng lớn. DBMS là trung tâm của hầu hết các ứng dụng cơ sở dữ liệu, và có thể dựa vào hệ điều hành tiêu chuẩn để cung cấp chức năng.
Do sự quan trọng của thị trường DBMS, các nhà cung cấp máy tính và lưu trữ thường cân nhắc các yêu cầu của DBMS trong các kế hoạch phát triển của họ.
Cơ sở dữ liệu và các hệ quản trị cơ sở dữ liệu (DBMS) có thể được phân loại dựa trên mô hình dữ liệu mà chúng hỗ trợ (như mô hình quan hệ hoặc XML), loại máy tính mà chúng hoạt động trên (từ các cụm máy chủ đến thiết bị di động), ngôn ngữ truy vấn (QL) dùng để truy cập dữ liệu (như SQL hoặc XQuery) và các kỹ thuật nội bộ, ảnh hưởng đến hiệu suất, khả năng mở rộng, độ tin cậy và bảo mật.
Lịch sử
Khả năng, kích thước và hiệu suất của cơ sở dữ liệu và hệ quản trị cơ sở dữ liệu (DBMS) đã tăng trưởng theo cấp số nhân. Sự cải tiến này được thúc đẩy bởi sự tiến bộ công nghệ trong các lĩnh vực bộ xử lý, bộ nhớ, lưu trữ và mạng máy tính. Sự phát triển công nghệ cơ sở dữ liệu có thể được phân chia thành ba giai đoạn chính dựa trên mô hình hoặc cấu trúc dữ liệu: hướng đối tượng, SQL/quan hệ và hậu quan hệ.
Hai mô hình dữ liệu hướng đối tượng ban đầu chính là mô hình phân cấp và mô hình CODASYL (mô hình mạng).
Mô hình quan hệ, được Edgar F. Codd giới thiệu vào năm 1970, đã phá vỡ truyền thống bằng cách nhấn mạnh rằng các ứng dụng nên tìm kiếm dữ liệu theo nội dung thay vì theo các liên kết. Mô hình quan hệ sử dụng các bảng dạng sổ cái, mỗi bảng dành cho một loại thực thể khác nhau. Chỉ đến giữa những năm 1980, phần cứng máy tính mới đủ mạnh để triển khai rộng rãi các hệ thống quan hệ (DBMS cộng với các ứng dụng). Tuy nhiên, vào đầu những năm 1990, các hệ thống quan hệ đã chiếm ưu thế trong tất cả các ứng dụng xử lý dữ liệu quy mô lớn và tính đến năm 2018, chúng vẫn chiếm ưu thế: IBM DB2, Oracle, MySQL và Microsoft SQL Server là các hệ quản trị cơ sở dữ liệu được tìm kiếm nhiều nhất. Ngôn ngữ cơ sở dữ liệu chủ yếu, SQL, được tiêu chuẩn hóa cho mô hình quan hệ, đã ảnh hưởng đến các ngôn ngữ cơ sở dữ liệu cho các mô hình dữ liệu khác. Cơ sở dữ liệu đối tượng được phát triển vào những năm 1980 để giải quyết vấn đề không tương thích của mô hình quan hệ, dẫn đến thuật ngữ 'hậu quan hệ' và sự phát triển của cơ sở dữ liệu quan hệ đối tượng lai.
Cuối những năm 2000, thế hệ cơ sở dữ liệu hậu quan hệ được biết đến với tên gọi cơ sở dữ liệu NoQuery, mang đến các kho lưu trữ khóa-giá trị nhanh và cơ sở dữ liệu định hướng tài liệu. Một 'thế hệ kế tiếp' cạnh tranh được gọi là cơ sở dữ liệu NewQuery đã thử nghiệm các mô hình mới, giữ lại mô hình quan hệ/SQL trong khi hướng đến hiệu suất cao của NoQuery, so với các hệ quản trị cơ sở dữ liệu quan hệ hiện có.
Những năm 1960, DBMS hướng đối tượng
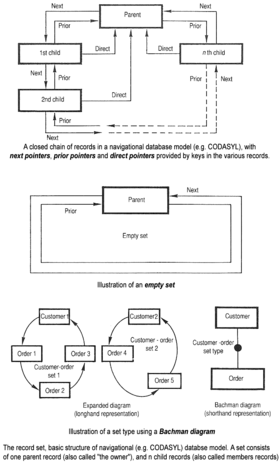
Thuật ngữ cơ sở dữ liệu lần đầu xuất hiện cùng với sự ra đời của bộ lưu trữ truy cập trực tiếp (bao gồm đĩa và băng) từ giữa những năm 1960. Thuật ngữ này được dùng để phân biệt với các hệ thống dựa trên băng trước đó, cho phép sử dụng tương tác chia sẻ thay vì xử lý hàng ngày. Theo từ điển tiếng Anh Oxford, báo cáo năm 1962 của Tập đoàn Phát triển Hệ thống California là lần đầu tiên sử dụng thuật ngữ 'cơ sở dữ liệu' với nghĩa kỹ thuật cụ thể.
Khi máy tính phát triển về tốc độ và khả năng, một số hệ thống cơ sở dữ liệu đa năng đã xuất hiện; vào giữa những năm 1960, nhiều hệ thống như vậy đã được triển khai thương mại. Sự quan tâm đến việc tiêu chuẩn hóa gia tăng và Charles Bachman, người sáng lập sản phẩm như Kho dữ liệu tích hợp (IDS), đã thành lập 'Nhóm nhiệm vụ cơ sở dữ liệu' trong CODASYL, nhóm chịu trách nhiệm tạo và chuẩn hóa COBOL. Năm 1971, Nhóm Nhiệm vụ Cơ sở dữ liệu công bố tiêu chuẩn của họ, thường được gọi là 'phương pháp CODASYL', và ngay sau đó, một số sản phẩm thương mại dựa trên phương pháp này đã được giới thiệu trên thị trường.
Cách tiếp cận của CODASYL, dựa trên mô hình dữ liệu hướng đối tượng 'thủ công', đã tạo ra một mạng lưới lớn các bản ghi liên kết. Các ứng dụng có thể tìm kiếm bản ghi theo một trong ba phương pháp sau:
- Sử dụng khóa chính (gọi là khóa CALC, thường được thực hiện bằng cách băm)
- Hướng đối tượng các mối quan hệ (được gọi là bộ) từ bản ghi này sang bản ghi khác
- Quét toàn bộ bản ghi theo thứ tự liên tiếp
Các hệ thống sau này đã bổ sung cây B để cung cấp các phương thức truy cập thay thế. Nhiều cơ sở dữ liệu CODASYL cũng đã thêm một ngôn ngữ truy vấn cơ bản. Tuy nhiên, trong kiểm tra cuối cùng, CODASYL rất phức tạp và đòi hỏi đào tạo và công sức đáng kể để phát triển các ứng dụng hữu ích.
IBM đã giới thiệu DBMS của riêng mình vào năm 1966, được gọi là Hệ thống Quản lý Thông tin (IMS). IMS là kết quả của phần mềm phát triển cho chương trình Apollo trên System/360. Mặc dù IMS tương tự về khái niệm với CODASYL, nhưng nó sử dụng hệ thống phân cấp chặt chẽ cho mô hình dữ liệu hướng đối tượng thay vì mô hình mạng của CODASYL. Cả hai khái niệm này sau đó được gọi là cơ sở dữ liệu hướng đối tượng, như được thể hiện trong bài thuyết trình Turing Award năm 1973 của Bachman, The Programmer as Navigator. IMS được phân loại là cơ sở dữ liệu phân cấp, trong khi cơ sở dữ liệu TOTAL của IDMS và Cincom Systems được phân loại là cơ sở dữ liệu mạng. Tính đến năm 2014, IMS vẫn đang được sử dụng.
Những năm 1970, DBMS quan hệ
Edgar Codd làm việc tại IBM ở San Jose, California, tại một trong các văn phòng của họ, chủ yếu tập trung vào phát triển hệ thống đĩa cứng. Ông không hài lòng với mô hình hướng đối tượng của phương pháp CODASYL, đặc biệt là sự thiếu vắng cơ sở tìm kiếm. Vào năm 1970, ông đã viết một loạt bài báo phác thảo một phương pháp mới để xây dựng cơ sở dữ liệu, dẫn đến bài viết nổi tiếng A Relational Model of Data for Large Shared Data Banks.
Trong bài viết này, ông đã giới thiệu một hệ thống mới để lưu trữ và xử lý cơ sở dữ liệu lớn. Thay vì lưu trữ các bản ghi trong danh sách liên kết tự do như trong CODASYL, Codd đề xuất việc sử dụng các 'bảng' với các bản ghi có độ dài cố định, mỗi bảng đại diện cho một loại thực thể khác nhau. Một hệ thống danh sách liên kết không hiệu quả trong việc lưu trữ cơ sở dữ liệu 'thưa thớt', nơi dữ liệu cho một bản ghi có thể bị bỏ trống. Mô hình quan hệ giải quyết vấn đề này bằng cách phân chia dữ liệu thành nhiều bảng (hoặc quan hệ) được chuẩn hóa, với các phần tử tùy chọn được di chuyển ra khỏi bảng chính chỉ khi cần thiết. Dữ liệu có thể được chèn, xóa và chỉnh sửa dễ dàng trong các bảng, với DBMS thực hiện các công việc bảo trì cần thiết để hiện thị bảng cho ứng dụng/người dùng.
Mô hình quan hệ cũng cho phép mở rộng nội dung của cơ sở dữ liệu mà không cần phải viết lại các liên kết và con trỏ. Phần 'quan hệ' trong mô hình này xuất phát từ việc các thực thể tham chiếu lẫn nhau trong các mối quan hệ một-nhiều, tương tự như mô hình phân cấp truyền thống, và mối quan hệ nhiều-nhiều, như mô hình hướng đối tượng (mạng). Do đó, mô hình quan hệ có thể biểu diễn cả mô hình phân cấp và hướng đối tượng, cũng như mô hình bảng gốc của nó, cho phép áp dụng mô hình thuần túy hoặc kết hợp giữa ba mô hình này theo yêu cầu của ứng dụng.
Một ví dụ phổ biến về việc sử dụng hệ thống cơ sở dữ liệu là theo dõi thông tin người dùng như tên, thông tin đăng nhập, địa chỉ và số điện thoại. Trong cách tiếp cận hướng đối tượng, tất cả dữ liệu này sẽ được lưu trong một bản ghi và các mục không sử dụng sẽ không được lưu trữ. Ngược lại, với cách tiếp cận quan hệ, dữ liệu sẽ được chuẩn hóa thành các bảng như bảng người dùng, bảng địa chỉ và bảng số điện thoại. Bản ghi sẽ chỉ được tạo trong các bảng này khi địa chỉ hoặc số điện thoại thực sự được cung cấp.
Việc kết nối thông tin là cốt lõi của hệ thống này. Trong mô hình quan hệ, thông tin được sử dụng làm 'khóa' để xác định duy nhất một bản ghi cụ thể. Khi thu thập dữ liệu người dùng, thông tin lưu trữ trong các bảng sẽ được tìm bằng khóa này. Ví dụ, nếu tên đăng nhập là duy nhất, địa chỉ và số điện thoại của người dùng sẽ được ghi lại với tên đăng nhập làm khóa. Việc 'kết nối' dữ liệu liên quan để tạo thành một tập hợp đơn giản là điều mà các ngôn ngữ máy tính truyền thống không được thiết kế để thực hiện.
Tương tự như các chương trình hướng đối tượng yêu cầu vòng lặp để thu thập bản ghi, phương pháp quan hệ cũng cần vòng lặp để lấy thông tin từ bất kỳ một bản ghi nào. Codd đề xuất một ngôn ngữ tập hợp, sau này phát triển thành SQL. Ông đã chứng minh qua tính toán tuple rằng hệ thống này có thể hỗ trợ tất cả các hoạt động cơ sở dữ liệu như chèn, cập nhật, và cung cấp một hệ thống đơn giản để tìm và trả về các tập hợp dữ liệu trong một thao tác.
Bài viết của Codd đã thu hút sự chú ý của Eugene Wong và Michael Stonebraker tại Berkeley. Họ bắt đầu dự án INGRES với nguồn vốn từ dự án cơ sở dữ liệu địa lý và các lập trình viên sinh viên để phát triển mã nguồn. INGRES, từ năm 1973, đã cho ra các sản phẩm thử nghiệm đầu tiên và sẵn sàng sử dụng rộng rãi vào năm 1979. INGRES có điểm tương đồng với System R, bao gồm việc sử dụng 'ngôn ngữ' truy cập dữ liệu gọi là QUEL. INGRES sau đó đã chuyển sang tiêu chuẩn SQL.
IBM cũng đã thử nghiệm mô hình quan hệ qua PRTV và một mô hình sản xuất, Business System 12, cả hai đã ngừng hoạt động. Honeywell phát triển MRDS cho Multics và hiện có hai triển khai mới là Alphora Dataphor và Rel. Hầu hết các triển khai DBMS khác được gọi là quan hệ thực chất là các DBMS SQL.
Năm 1970, Đại học Michigan phát triển Hệ thống quản lý thông tin MICRO dựa trên mô hình dữ liệu lý thuyết tập hợp của DL Childs. MICRO được Bộ Lao động Mỹ, Cục Bảo vệ Môi trường Mỹ, và các nhà nghiên cứu từ Đại học Alberta, Đại học Michigan, và Đại học Wayne State sử dụng để quản lý các tập dữ liệu lớn. Hệ thống hoạt động trên máy tính lớn của IBM với Hệ thống đầu cuối Michigan và vẫn được sử dụng đến năm 1998.
Phương pháp tích hợp
Trong thập niên 1970 và 1980, đã có nhiều nỗ lực để phát triển các hệ thống cơ sở dữ liệu tích hợp cả phần cứng lẫn phần mềm. Triết lý cơ bản là sự tích hợp này sẽ mang lại hiệu suất cao hơn với chi phí thấp hơn. Ví dụ điển hình là IBM System/38, dịch vụ Teradata sớm và máy cơ sở dữ liệu của Britton Lee, Inc.
Một cách tiếp cận khác là bộ tăng tốc CAFS của ICL, một bộ điều khiển đĩa phần cứng có khả năng tìm kiếm lập trình. Tuy nhiên, các nỗ lực này thường thất bại do máy cơ sở dữ liệu chuyên dụng không theo kịp sự phát triển nhanh chóng của máy tính đa năng. Hiện tại, hầu hết các hệ thống cơ sở dữ liệu đều là phần mềm chạy trên phần cứng đa năng, sử dụng lưu trữ dữ liệu máy tính đa năng. Dù vậy, ý tưởng này vẫn được các công ty như Netezza và Oracle (Exadata) tiếp tục theo đuổi.
Cuối thập niên 1970, SQL DBMS
IBM bắt đầu phát triển hệ thống nguyên mẫu dựa trên các khái niệm của Codd, được gọi là System R, vào đầu những năm 1970. Phiên bản đầu tiên đã hoàn thiện vào năm 1974/5 và sau đó triển khai trên các hệ thống đa bảng, nơi dữ liệu không cần phải lưu trữ trong một 'khối' lớn. Các phiên bản đa người dùng sau đó đã được thử nghiệm vào năm 1978 và 1979, với một ngôn ngữ truy vấn tiêu chuẩn hóa - SQL - được thêm vào. Các ý tưởng của Codd đã chứng minh tính khả thi và ưu việt hơn so với CODASYL, dẫn đến việc IBM phát triển phiên bản sản xuất thực sự của System R, gọi là SQL/DS, và sau đó là Database 2 (DB2).
Cơ sở dữ liệu Oracle, do Larry Ellison phát triển (hay còn gọi là Oracle), khởi nguồn từ một hướng đi khác dựa trên tài liệu của IBM về Hệ thống R. Mặc dù phiên bản Oracle V1 đã hoàn tất vào năm 1978, nhưng chỉ đến khi Oracle Phiên bản 2 ra mắt vào năm 1979 mới vượt qua IBM trên thị trường.
Stonoplker tiếp tục áp dụng những kinh nghiệm từ INGRES để phát triển cơ sở dữ liệu mới, Postgres, hiện được gọi là PostgreQuery. PostgreSQL hiện được sử dụng cho các ứng dụng toàn cầu quan trọng (các cơ quan đăng ký tên miền .org và .info dùng nó làm kho lưu trữ chính, cùng nhiều công ty và tổ chức tài chính lớn).
Tại Thụy Điển, bài viết của Codd cũng đã được nghiên cứu, dẫn đến việc phát triển Mimer SQL từ giữa những năm 1970 tại Đại học Uppsala. Năm 1984, dự án này được hợp nhất thành một doanh nghiệp độc lập.
Một mô hình dữ liệu khác, mô hình quan hệ thực thể, đã xuất hiện vào năm 1976 và trở nên phổ biến trong thiết kế cơ sở dữ liệu nhờ vào sự mô tả quen thuộc hơn so với mô hình quan hệ trước đó. Sau đó, các cấu trúc mối quan hệ thực thể được tích hợp thêm như một cấu trúc mô hình dữ liệu cho mô hình quan hệ, và sự khác biệt giữa hai cấu trúc dần trở nên không quan trọng.
Những năm 1980, trên máy tính để bàn
Những năm 1980 đánh dấu sự xuất hiện của máy tính để bàn, mở ra kỷ nguyên mới với các công cụ mạnh mẽ như Lotus 1-2-3 cho bảng tính và dBASE cho quản lý cơ sở dữ liệu. dBASE được biết đến với sự đơn giản và dễ tiếp cận, giúp người dùng không cần lo lắng về các thao tác phức tạp liên quan đến việc mở, đọc và đóng tệp. C. Wayne Ratliff, nhà sáng lập dBASE, nhấn mạnh rằng phần mềm này đã giảm bớt rất nhiều công việc khó khăn cho người dùng, cho phép họ tập trung vào công việc chính. dBASE trở thành một trong những phần mềm bán chạy nhất trong những năm 1980 và đầu 1990.
Những năm 1990, hướng đối tượng
Những năm 1990 chứng kiến sự phát triển mạnh mẽ của lập trình hướng đối tượng, cùng với đó là sự thay đổi trong cách quản lý dữ liệu. Các nhà phát triển và thiết kế bắt đầu coi dữ liệu trong cơ sở dữ liệu như các đối tượng, với các thuộc tính như địa chỉ, số điện thoại, và tuổi được gán trực tiếp cho đối tượng đó. Điều này thay đổi cách thức quan hệ dữ liệu, chuyển từ các trường riêng lẻ sang các đối tượng và thuộc tính của chúng. Thuật ngữ 'không khớp trở kháng quan hệ đối tượng' mô tả sự khó khăn trong việc chuyển đổi giữa các đối tượng lập trình và bảng cơ sở dữ liệu. Các cơ sở dữ liệu đối tượng và cơ sở dữ liệu quan hệ đối tượng đã cố gắng giải quyết vấn đề này bằng cách cung cấp ngôn ngữ hướng đối tượng hoặc mở rộng SQL để thay thế cho SQL thuần túy. Các thư viện ánh xạ quan hệ đối tượng (ORM) cũng được phát triển để giải quyết vấn đề này trong lập trình.
Những năm 2000, NoSQL và NewSQL
Cơ sở dữ liệu XML là một loại cơ sở dữ liệu hướng tài liệu, cho phép truy vấn dựa trên thuộc tính của tài liệu XML. Chúng chủ yếu được sử dụng trong các ứng dụng mà dữ liệu được tổ chức dưới dạng tài liệu, với cấu trúc có thể thay đổi từ rất linh hoạt đến rất cứng nhắc. Ví dụ về các ứng dụng này bao gồm bài báo khoa học, bằng sáng chế, hồ sơ thuế và hồ sơ nhân sự.
Cơ sở dữ liệu NoSQL nổi bật với tốc độ nhanh chóng, không yêu cầu cấu trúc bảng cố định, và tránh các thao tác kết hợp phức tạp bằng cách lưu trữ dữ liệu không chuẩn hóa. Chúng được thiết kế để mở rộng theo chiều ngang một cách linh hoạt.
Gần đây, nhu cầu về cơ sở dữ liệu phân tán với khả năng chịu lỗi phân vùng cao đã tăng mạnh. Tuy nhiên, theo định lý CAP, không có hệ thống phân tán nào có thể đồng thời đảm bảo tính nhất quán, tính sẵn sàng và khả năng phân vùng. Một hệ thống phân tán có thể đáp ứng được hai trong ba yêu cầu này, nhưng không thể đáp ứng cả ba. Do đó, nhiều cơ sở dữ liệu NoSQL hiện đang áp dụng tính nhất quán cuối cùng để đảm bảo dung sai phân vùng và tính sẵn sàng với mức độ nhất quán dữ liệu giảm.
NewSQL là một loại cơ sở dữ liệu quan hệ hiện đại, thiết kế để cung cấp hiệu suất mở rộng giống như các hệ thống NoSQL, hỗ trợ khối lượng công việc xử lý giao dịch trực tuyến (đọc-ghi) mà vẫn duy trì sử dụng SQL và đảm bảo các nguyên tắc ACID của cơ sở dữ liệu truyền thống.
Trường hợp sử dụng
Cơ sở dữ liệu được triển khai để hỗ trợ hoạt động nội bộ của tổ chức và cải thiện các tương tác trực tuyến với khách hàng và nhà cung cấp (xem phần mềm Doanh nghiệp).
Cơ sở dữ liệu được sử dụng để lưu trữ thông tin quản trị và các dữ liệu chuyên biệt như dữ liệu kỹ thuật hoặc mô hình kinh tế. Ví dụ bao gồm hệ thống thư viện máy tính, hệ thống đặt vé máy bay, hệ thống kiểm kê thiết bị máy tính và nhiều hệ thống quản lý nội dung khác lưu trữ các trang web dưới dạng bộ sưu tập trong cơ sở dữ liệu.
Phân loại
Cơ sở dữ liệu có thể được phân loại dựa trên loại nội dung của chúng, chẳng hạn như thư mục, tài liệu văn bản, dữ liệu thống kê hoặc đối tượng đa phương tiện. Một cách phân loại khác là dựa trên lĩnh vực ứng dụng, ví dụ như kế toán, soạn nhạc, điện ảnh, ngân hàng, sản xuất hoặc bảo hiểm. Cũng có thể phân loại theo các yếu tố kỹ thuật như cấu trúc cơ sở dữ liệu hoặc loại giao diện. Phần này giới thiệu một số thuật ngữ được sử dụng để mô tả các loại cơ sở dữ liệu khác nhau.
- Cơ sở dữ liệu trong bộ nhớ chủ yếu hoạt động từ bộ nhớ chính, nhưng thường được sao lưu vào các hệ thống lưu trữ không thay đổi. Loại cơ sở dữ liệu này nhanh hơn cơ sở dữ liệu trên đĩa, và do đó thường được dùng trong các ứng dụng yêu cầu thời gian phản hồi nhanh, chẳng hạn như trong thiết bị mạng viễn thông.
- Cơ sở dữ liệu hoạt động bao gồm một kiến trúc hướng sự kiện có khả năng đáp ứng các điều kiện bên trong và bên ngoài cơ sở dữ liệu. Các ứng dụng có thể bao gồm giám sát an ninh, cảnh báo, thu thập dữ liệu và ủy quyền. Nhiều cơ sở dữ liệu hoạt động cung cấp các tính năng kích hoạt cơ sở dữ liệu.
- Cơ sở dữ liệu đám mây dựa trên công nghệ đám mây, với cả cơ sở dữ liệu và phần lớn DBMS nằm từ xa, “trong đám mây”. Các ứng dụng được phát triển bởi lập trình viên và được người dùng cuối truy cập qua trình duyệt web và API mở.
- Kho dữ liệu lưu trữ dữ liệu từ cơ sở dữ liệu hoạt động và thường từ các nguồn bên ngoài như công ty nghiên cứu thị trường. Kho dữ liệu trở thành nguồn trung tâm cho quản lý và người dùng cuối khác, những người không có quyền truy cập vào dữ liệu hoạt động. Ví dụ, dữ liệu bán hàng có thể được tổng hợp thành tổng số hàng tuần và chuyển đổi từ mã sản phẩm nội bộ sang UPC để so sánh với dữ liệu ACNielsen. Các thành phần cơ bản của kho dữ liệu bao gồm trích xuất, phân tích, khai thác dữ liệu, chuyển đổi, tải và quản lý dữ liệu để sử dụng tiếp.
- Cơ sở dữ liệu suy diễn kết hợp lập trình logic với cơ sở dữ liệu quan hệ.
- Cơ sở dữ liệu phân tán là loại cơ sở dữ liệu mà dữ liệu và DBMS trải rộng trên nhiều máy tính.
- Cơ sở dữ liệu hướng tài liệu được thiết kế để lưu trữ, truy xuất và quản lý thông tin theo định dạng tài liệu hoặc bán cấu trúc. Đây là một trong những loại cơ sở dữ liệu chính của NoSQL.
- Hệ thống cơ sở dữ liệu nhúng là DBMS tích hợp chặt chẽ với ứng dụng phần mềm, yêu cầu quyền truy cập vào dữ liệu mà không cần bảo trì liên tục và ẩn khỏi người dùng cuối của ứng dụng.
- Cơ sở dữ liệu người dùng cuối bao gồm dữ liệu do người dùng cuối phát triển, chẳng hạn như tài liệu, bảng tính, bản trình bày, đa phương tiện và các tệp khác. Một số sản phẩm hỗ trợ loại cơ sở dữ liệu này, thường có chức năng đơn giản hơn so với DBMS chính thức.
- Hệ thống cơ sở dữ liệu liên kết bao gồm nhiều cơ sở dữ liệu riêng biệt, mỗi cái có DBMS riêng, được quản lý như một cơ sở dữ liệu duy nhất bởi một hệ thống quản lý cơ sở dữ liệu liên kết (FDBMS), tích hợp các DBMS tự trị để cung cấp một cái nhìn khái niệm tích hợp.
- Thuật ngữ đa cơ sở dữ liệu đôi khi được dùng như từ đồng nghĩa với cơ sở dữ liệu liên kết, dù nó có thể chỉ nhóm các cơ sở dữ liệu ít tích hợp hơn, sử dụng phần mềm trung gian và giao thức cam kết nguyên tử (ACP) như giao thức cam kết hai pha để thực hiện các giao dịch phân tán.
- Cơ sở dữ liệu đồ thị là loại cơ sở dữ liệu NoSQL sử dụng các cấu trúc đồ thị với các nút, cạnh và thuộc tính để lưu trữ và thể hiện thông tin. Cơ sở dữ liệu đồ thị chung có thể lưu trữ bất kỳ loại đồ thị nào, trong khi cơ sở dữ liệu đồ thị chuyên dụng như bộ ba và cơ sở dữ liệu mạng cung cấp các tính năng đặc biệt hơn.
- DBMS mảng là loại DBMS NoSQL cho phép mô hình hóa, lưu trữ và truy xuất các mảng đa chiều lớn, như hình ảnh vệ tinh và dữ liệu mô phỏng khí hậu.
- Trong cơ sở dữ liệu siêu văn bản hoặc hypermedia, bất kỳ từ hoặc đoạn văn nào có thể được siêu liên kết với một đối tượng như đoạn văn bản, bài viết, hình ảnh hoặc video. Loại cơ sở dữ liệu này rất hữu ích để tổ chức lượng lớn thông tin khác nhau, chẳng hạn như bách khoa toàn thư trực tuyến. World Wide Web là một cơ sở dữ liệu siêu văn bản phân tán lớn.
- Cơ sở tri thức (KB) là loại cơ sở dữ liệu đặc biệt dành cho quản lý kiến thức, cung cấp phương tiện để thu thập, tổ chức và khai thác kiến thức trên máy tính, tương tự như bộ sưu tập dữ liệu về các vấn đề và giải pháp liên quan.
- Cơ sở dữ liệu di động có thể được thực hiện hoặc đồng bộ hóa từ thiết bị điện toán di động.
- Cơ sở dữ liệu hoạt động lưu trữ dữ liệu chi tiết về hoạt động của tổ chức, xử lý khối lượng cập nhật cao qua các giao dịch. Ví dụ bao gồm cơ sở dữ liệu khách hàng, cơ sở dữ liệu nhân sự và hệ thống hoạch định nguồn lực doanh nghiệp, theo dõi các hoạt động tài chính, hàng tồn kho và thông tin sản phẩm.
- Cơ sở dữ liệu song song cải thiện hiệu suất bằng cách phân chia và thực hiện song song các tác vụ như tải dữ liệu, xây dựng chỉ mục và xử lý truy vấn.
- Các kiến trúc DBMS song song chính được xây dựng dựa trên các cấu hình phần cứng cơ bản bao gồm:
- Kiến trúc bộ nhớ dùng chung, nơi nhiều bộ xử lý chia sẻ cùng một không gian bộ nhớ chính cũng như bộ lưu trữ khác.
- Kiến trúc đĩa chia sẻ, trong đó mỗi đơn vị xử lý (thường là nhiều bộ xử lý) có bộ nhớ chính riêng, nhưng tất cả cùng sử dụng bộ lưu trữ chung.
- Kiến trúc không chia sẻ, trong đó mỗi đơn vị xử lý có bộ nhớ chính và bộ lưu trữ riêng biệt.
- Các kiến trúc DBMS song song chính được xây dựng dựa trên các cấu hình phần cứng cơ bản bao gồm:
- Cơ sở dữ liệu xác suất áp dụng logic mờ để rút ra kết luận từ dữ liệu không chính xác.
- Cơ sở dữ liệu thời gian thực xử lý các giao dịch với tốc độ nhanh để kết quả được phản hồi và xử lý ngay lập tức.
- Cơ sở dữ liệu không gian lưu trữ dữ liệu có tính năng đa chiều. Các truy vấn bao gồm những câu hỏi dựa trên vị trí, ví dụ: 'Khách sạn gần nhất ở đâu trong khu vực của tôi?'.
- Cơ sở dữ liệu tạm thời tích hợp các yếu tố thời gian, chẳng hạn như mô hình dữ liệu tạm thời và phiên bản tạm thời của SQL. Các yếu tố thời gian bao gồm thời gian hợp lệ và thời gian giao dịch.
- Cơ sở dữ liệu định hướng thuật ngữ dựa trên cơ sở dữ liệu hướng đối tượng, thường được tùy chỉnh cho một lĩnh vực cụ thể.
- Cơ sở dữ liệu phi cấu trúc được thiết kế để lưu trữ các đối tượng đa dạng không phù hợp với cấu trúc chung. Nó có thể bao gồm email, tài liệu, tạp chí, đa phương tiện, v.v. Mặc dù tên gọi có thể gây nhầm lẫn vì một số đối tượng có thể có cấu trúc, toàn bộ bộ sưu tập có thể không phù hợp với một khung cấu trúc cụ thể. Hiện nay, nhiều DBMS hỗ trợ dữ liệu phi cấu trúc theo nhiều cách và các DBMS chuyên dụng đang ngày càng phát triển.
Giao tiếp cơ sở dữ liệu
Hệ quản trị cơ sở dữ liệu
Hệ quản trị cơ sở dữ liệu (DBMS) là phần mềm quản lý và tổ chức cơ sở dữ liệu. Nó cung cấp giao diện giữa cơ sở dữ liệu với người dùng hoặc ứng dụng để thực hiện các thao tác như tạo, sửa đổi, truy vấn và xóa dữ liệu.
Viết tắt DBMS có thể chỉ ra các mô hình cơ sở dữ liệu cơ bản như RDBMS cho mô hình quan hệ, OODBMS hoặc ORDBMS cho mô hình đối tượng, và ORDBMS cho mô hình quan hệ đối tượng. Các ký hiệu khác như DDBMS có thể chỉ các hệ thống quản lý cơ sở dữ liệu phân tán.
Chức năng của một DBMS có thể khác nhau tùy vào loại. Các chức năng cơ bản bao gồm lưu trữ, truy xuất và cập nhật dữ liệu. Theo Codd, một DBMS đa mục đích nên cung cấp các chức năng và dịch vụ sau đây:
- Lưu trữ, truy xuất và cập nhật dữ liệu
- Danh mục người dùng có thể truy cập hoặc từ điển dữ liệu mô tả siêu dữ liệu
- Hỗ trợ giao dịch và đồng thời
- Khả năng phục hồi dữ liệu nếu xảy ra sự cố
- Quản lý quyền truy cập và cập nhật dữ liệu
- Hỗ trợ truy cập từ các vị trí từ xa
- Thực hiện các ràng buộc để đảm bảo dữ liệu tuân thủ quy tắc nhất định
DBMS thường cung cấp một loạt các công cụ để quản trị cơ sở dữ liệu hiệu quả, bao gồm các công cụ nhập, xuất, giám sát, phân mảnh và phân tích. Phần cốt lõi của DBMS, liên kết giữa cơ sở dữ liệu và giao diện ứng dụng, đôi khi được gọi là công cụ cơ sở dữ liệu.
Các DBMS thường có các tham số cấu hình có thể điều chỉnh được, cả tĩnh và động, như lượng bộ nhớ chính tối đa mà cơ sở dữ liệu có thể sử dụng trên máy chủ. Xu hướng hiện nay là giảm thiểu cấu hình thủ công và, đặc biệt với các cơ sở dữ liệu nhúng, việc quản trị tự động là rất quan trọng.
Các DBMS lớn của doanh nghiệp thường mở rộng cả về kích thước lẫn chức năng, kết quả của hàng ngàn năm phát triển công nghệ và nỗ lực của con người.
DBMS nhiều người dùng ngày xưa chỉ cho phép ứng dụng trên cùng một máy tính truy cập qua thiết bị đầu cuối hoặc phần mềm giả lập thiết bị đầu cuối. Kiến trúc máy chủ và máy khách phát triển cho phép ứng dụng nằm trên máy khách và cơ sở dữ liệu trên máy chủ, dẫn đến việc phân phối xử lý. Tiến xa hơn, kiến trúc đa nhiệm kết hợp máy chủ ứng dụng và máy chủ web, với giao diện người dùng qua trình duyệt web và cơ sở dữ liệu chỉ kết nối trực tiếp với tầng kế cận.
DBMS đa mục đích thường cung cấp các API công cộng và tùy chọn bộ xử lý cho các ngôn ngữ cơ sở dữ liệu như SQL, cho phép các ứng dụng tương tác với cơ sở dữ liệu. Các DBMS đặc biệt có thể sử dụng API riêng và được tùy chỉnh cho một ứng dụng cụ thể. Ví dụ, hệ thống email thực hiện nhiều chức năng của DBMS đa mục đích như chèn, xóa tin nhắn, xử lý tệp đính kèm, tra cứu danh sách chặn, và liên kết tin nhắn với địa chỉ email.
Một số thành tựu đáng chú ý của Hệ quản trị cơ sở dữ liệu (DBMS):
- DBMS đã đơn giản hóa việc quản lý dữ liệu, thay vì lưu trữ dữ liệu trong các tập tin riêng lẻ, giúp truy xuất thông tin nhanh chóng và dễ dàng hơn.
- DBMS cung cấp phương pháp tổ chức dữ liệu hiệu quả hơn, bằng cách sắp xếp dữ liệu thành các bảng và quan hệ rõ ràng, giảm thiểu lặp lại và tăng tính rõ ràng.
- DBMS phát triển các ngôn ngữ truy vấn mạnh mẽ như SQL, giúp thực hiện các truy vấn phức tạp một cách nhanh chóng và hiệu quả.
- DBMS cung cấp bảo mật dữ liệu, với các công cụ xác thực người dùng, kiểm soát quyền truy cập và bảo vệ dữ liệu khỏi các mối đe dọa bên ngoài.
- DBMS đã cải tiến công nghệ lưu trữ dữ liệu, từ ổ đĩa cứng đến hệ thống RAID và lưu trữ dự phòng, cung cấp khả năng lưu trữ an toàn và tin cậy.
- DBMS hỗ trợ xử lý dữ liệu lớn, với các công nghệ như điện toán đám mây, Hadoop, và Spark, giúp xử lý khối lượng dữ liệu lớn và dữ liệu không gian, thời gian một cách hiệu quả.
Ứng dụng
Tương tác với cơ sở dữ liệu diễn ra qua các chương trình ứng dụng kết nối với DBMS. Điều này có thể bao gồm từ các công cụ cơ sở dữ liệu cho phép người dùng thực hiện truy vấn SQL bằng văn bản hoặc giao diện đồ họa, đến các trang web sử dụng cơ sở dữ liệu để lưu trữ và truy xuất thông tin.
Giao diện ứng dụng
Lập trình viên thực hiện tương tác với cơ sở dữ liệu (hoặc nguồn dữ liệu) thông qua các giao diện ứng dụng (API) hoặc ngôn ngữ cơ sở dữ liệu. API hoặc ngôn ngữ sử dụng cần được DBMS hỗ trợ, có thể gián tiếp qua bộ xử lý trung gian hoặc API cầu nối. Một số API như ODBC hoạt động độc lập với cơ sở dữ liệu, trong khi các API khác bao gồm JDBC và ADO.NET.
Ngôn ngữ cơ sở dữ liệu
Ngôn ngữ cơ sở dữ liệu là loại ngôn ngữ đặc thù, được thiết kế để thực hiện một hoặc nhiều loại tác vụ sau, thường được phân thành các ngôn ngữ con như sau:
- Ngôn ngữ kiểm soát dữ liệu (DCL) - quản lý quyền truy cập dữ liệu;
- Ngôn ngữ định nghĩa dữ liệu (DDL) - thiết lập các loại dữ liệu như tạo, thay đổi hoặc xóa, và các mối quan hệ giữa chúng;
- Ngôn ngữ thao tác dữ liệu (DML) - thực hiện các thao tác như thêm, cập nhật hoặc xóa các bản ghi dữ liệu;
- Ngôn ngữ truy vấn dữ liệu (DQL) - cho phép truy vấn và tính toán thông tin từ dữ liệu.
Ngôn ngữ cơ sở dữ liệu thường được thiết kế cho một mô hình dữ liệu cụ thể. Một số ví dụ tiêu biểu là:
- SQL tích hợp các chức năng của định nghĩa dữ liệu, thao tác dữ liệu và truy vấn vào một ngôn ngữ duy nhất. Đây là một trong những ngôn ngữ đầu tiên cho mô hình quan hệ, mặc dù có một số khác biệt so với mô hình của Codd (như việc sắp xếp các hàng và cột trong bảng). SQL đã được công nhận là tiêu chuẩn bởi ANSI vào năm 1986 và ISO vào năm 1987, và các tiêu chuẩn này đã được cập nhật thường xuyên để phù hợp với các DBMS quan hệ.
- OQL là ngôn ngữ chuẩn cho mô hình đối tượng (do Nhóm quản lý dữ liệu đối tượng phát triển), ảnh hưởng đến thiết kế của nhiều ngôn ngữ truy vấn hiện đại như JDOQL và EJB QL.
- XQuery là ngôn ngữ truy vấn XML chuẩn, được áp dụng bởi các hệ thống cơ sở dữ liệu XML như MarkLogic và eXist, các cơ sở dữ liệu quan hệ có hỗ trợ XML như Oracle và DB2, và các bộ xử lý XML trong bộ nhớ như Saxon.
- SQL/XML kết hợp các khả năng của XQuery với SQL.
Ngôn ngữ cơ sở dữ liệu cũng có thể bao gồm những tính năng như:
- Cấu hình và quản lý các công cụ lưu trữ đặc thù cho DBMS
- Tính toán để điều chỉnh kết quả truy vấn, chẳng hạn như đếm, tổng hợp, trung bình, sắp xếp, nhóm và tham chiếu chéo
- Áp đặt các hạn chế thực thi (ví dụ: trong cơ sở dữ liệu ô tô, chỉ cho phép một loại động cơ trên mỗi xe)
- Phiên bản giao diện lập trình ứng dụng của ngôn ngữ truy vấn, giúp lập trình viên làm việc thuận tiện hơn
Lưu trữ
Lưu trữ cơ sở dữ liệu là phần vật lý chứa dữ liệu của cơ sở dữ liệu. Nó tương ứng với mức độ nội bộ (vật lý) trong cấu trúc cơ sở dữ liệu. Nó bao gồm toàn bộ thông tin cần thiết (như siêu dữ liệu, 'dữ liệu về dữ liệu' và cấu trúc dữ liệu bên trong) để chuyển đổi mức khái niệm và cấp độ bên ngoài từ mức nội bộ khi cần thiết. Việc lưu trữ dữ liệu vĩnh viễn thường do công cụ cơ sở dữ liệu hay còn gọi là 'công cụ lưu trữ' đảm nhiệm. Mặc dù DBMS thường truy cập qua hệ điều hành cơ bản (và có thể sử dụng các hệ thống tệp của hệ điều hành làm trung gian), các thuộc tính lưu trữ và cấu hình là rất quan trọng cho hiệu quả hoạt động của DBMS và do đó được quản trị cơ sở dữ liệu duy trì chặt chẽ. Một DBMS, trong quá trình hoạt động, luôn giữ cơ sở dữ liệu của nó trong một loại lưu trữ nhất định (ví dụ: bộ nhớ và lưu trữ ngoại vi). Dữ liệu cơ sở dữ liệu và thông tin bổ sung, có thể ở quy mô rất lớn, được mã hóa thành các bit. Dữ liệu thường được lưu trữ theo các cấu trúc hoàn toàn khác với cách nhìn của dữ liệu ở cấp độ khái niệm và bên ngoài, nhưng được tối ưu hóa để phục vụ nhu cầu tính toán và truy vấn của người dùng và chương trình (ví dụ: khi truy vấn cơ sở dữ liệu).
Một số DBMS cho phép chỉ định mã hóa ký tự được sử dụng cho lưu trữ dữ liệu, cho phép nhiều mã hóa khác nhau cùng tồn tại trong một cơ sở dữ liệu.
Các công cụ lưu trữ sử dụng các cấu trúc lưu trữ cơ sở dữ liệu mức thấp khác nhau để tuần tự hóa mô hình dữ liệu, giúp ghi dữ liệu vào phương tiện lưu trữ lựa chọn. Các kỹ thuật như lập chỉ mục có thể được áp dụng để nâng cao hiệu suất. Lưu trữ cơ sở dữ liệu thường theo định hướng hàng, nhưng cũng có các cơ sở dữ liệu định hướng cột và tương quan.
Quan điểm cụ thể hóa
Thường thì lưu trữ dự phòng được áp dụng để cải thiện hiệu suất. Ví dụ điển hình là lưu trữ các khung nhìn cụ thể hóa, bao gồm các khung nhìn bên ngoài hoặc kết quả của các truy vấn thường xuyên. Việc lưu trữ các quan điểm như vậy giúp tiết kiệm tài nguyên tính toán đáng kể mỗi khi chúng cần được truy cập. Tuy nhiên, nhược điểm của việc sử dụng khung nhìn cụ thể hóa là chi phí phát sinh khi cập nhật để đảm bảo tính đồng bộ với dữ liệu gốc và chi phí lưu trữ dự phòng.
Sao chép nhân rộng
Trong một số trường hợp, cơ sở dữ liệu áp dụng phương pháp lưu trữ dự phòng thông qua sao chép đối tượng cơ sở dữ liệu (tạo ra một hoặc nhiều bản sao) để tăng cường khả năng truy cập dữ liệu (cải thiện hiệu suất cho nhiều người dùng truy cập cùng một đối tượng và cung cấp khả năng phục hồi khi một cơ sở dữ liệu phân tán gặp sự cố). Việc cập nhật đối tượng nhân rộng cần được đồng bộ hóa giữa các bản sao. Trong nhiều trường hợp, toàn bộ cơ sở dữ liệu sẽ được nhân rộng.
Bảo mật
Bảo mật cơ sở dữ liệu liên quan đến mọi khía cạnh của việc bảo vệ dữ liệu, chủ sở hữu và người dùng của cơ sở dữ liệu. Điều này bao gồm việc ngăn chặn việc sử dụng trái phép và bảo vệ dữ liệu khỏi sự truy cập không mong muốn từ các cá nhân hoặc phần mềm không được phép.
Kiểm soát truy cập cơ sở dữ liệu là quá trình quản lý ai có quyền truy cập vào thông tin trong cơ sở dữ liệu. Điều này có thể bao gồm các đối tượng cụ thể hoặc cấu trúc dữ liệu để truy cập thông tin. Các quyền truy cập được thiết lập bởi các nhân viên được ủy quyền sử dụng các công cụ bảo mật DBMS đặc biệt.
Việc quản lý quyền truy cập có thể được thực hiện trên cơ sở từng cá nhân hoặc qua việc phân quyền cho các nhóm. Trong các mô hình phức tạp hơn, quyền truy cập được quản lý qua các vai trò cụ thể. Bảo mật dữ liệu ngăn không cho người dùng trái phép xem hoặc thay đổi cơ sở dữ liệu. Sử dụng mật khẩu cho phép người dùng truy cập toàn bộ cơ sở dữ liệu hoặc các phần cụ thể. Ví dụ, cơ sở dữ liệu nhân viên có thể chứa dữ liệu tổng thể về nhân viên, nhưng một nhóm chỉ có thể xem dữ liệu bảng lương, trong khi nhóm khác chỉ có quyền truy cập vào dữ liệu y tế và lịch sử làm việc.
Bảo mật dữ liệu chủ yếu liên quan đến việc bảo vệ các khối dữ liệu, cả về mặt vật lý (ngăn ngừa hư hỏng, phá hủy hoặc xóa) và về mặt giải mã thông tin (như phân tích chuỗi bit để xác định số thẻ tín dụng hợp lệ).
Theo dõi và thay đổi các bản ghi nhật ký để kiểm tra ai đã truy cập, thay đổi gì và khi nào. Dịch vụ ghi nhật ký hỗ trợ phân tích cơ sở dữ liệu sau này bằng cách giữ lại hồ sơ về các lần truy cập và thay đổi. Đôi khi mã ứng dụng được dùng để ghi lại thay đổi thay vì thực hiện trực tiếp trên cơ sở dữ liệu. Hệ thống giám sát có thể được thiết lập để phát hiện các vi phạm an ninh.
Giao dịch và xử lý giao dịch đồng thời
Giao dịch cơ sở dữ liệu giúp duy trì tính toàn vẹn và khả năng chịu lỗi của dữ liệu sau sự cố. Một giao dịch cơ sở dữ liệu bao gồm nhiều thao tác trên cơ sở dữ liệu (như đọc, ghi, lấy khóa, v.v.), được quản lý bởi hệ thống cơ sở dữ liệu và các hệ thống khác. Mỗi giao dịch có các giới hạn rõ ràng về chương trình/mã thực thi trong giao dịch, được xác định qua các lệnh giao dịch đặc biệt của lập trình viên.
ACID là từ viết tắt mô tả các đặc tính lý tưởng của giao dịch cơ sở dữ liệu: tính nguyên tử, tính nhất quán, sự cô lập và độ bền.
Di chuyển
Cơ sở dữ liệu được xây dựng trên một DBMS không thể trực tiếp di chuyển sang một DBMS khác (tức là, không thể chạy trên hệ thống khác). Tuy nhiên, có thể cần di chuyển cơ sở dữ liệu giữa các DBMS vì các lý do như chi phí, chức năng, và hiệu suất. Việc di chuyển yêu cầu chuyển đổi dữ liệu từ DBMS này sang DBMS khác, đồng thời giữ nguyên các ứng dụng liên quan (như các chương trình ứng dụng). Quá trình chuyển đổi nên duy trì các mức kiến trúc bên ngoài và khái niệm của cơ sở dữ liệu. Việc di chuyển cơ sở dữ liệu phức tạp hoặc lớn có thể rất tốn kém và cần xem xét kỹ lưỡng. Mặc dù có công cụ hỗ trợ di chuyển giữa các DBMS, thường thì nhà cung cấp DBMS cung cấp các công cụ hỗ trợ nhập dữ liệu từ các DBMS khác.
Xây dựng, bảo trì và điều chỉnh
Sau khi hoàn thiện thiết kế cơ sở dữ liệu cho ứng dụng, bước tiếp theo là thực hiện xây dựng cơ sở dữ liệu. Thường thì một DBMS đa dụng sẽ được chọn cho nhiệm vụ này. DBMS cung cấp các giao diện cần thiết để các quản trị viên cấu hình cấu trúc dữ liệu của ứng dụng trong mô hình dữ liệu của DBMS. Các giao diện khác sẽ được sử dụng để thiết lập các tham số cần thiết như bảo mật và phân bổ lưu trữ.
Khi cơ sở dữ liệu đã sẵn sàng (bao gồm tất cả các cấu trúc dữ liệu và thành phần cần thiết), nó sẽ được nạp dữ liệu ứng dụng ban đầu (quá trình khởi tạo cơ sở dữ liệu, thường được thực hiện qua một dự án riêng biệt; nhiều DBMS có giao diện hỗ trợ nhập dữ liệu hàng loạt). Trong một số trường hợp, cơ sở dữ liệu có thể hoạt động ngay cả khi chưa có dữ liệu và dữ liệu sẽ được thu thập dần trong suốt quá trình sử dụng.
Sau khi cơ sở dữ liệu đã được tạo, khởi tạo và nạp dữ liệu, nó cần được bảo trì. Các tham số của cơ sở dữ liệu có thể cần điều chỉnh và cơ sở dữ liệu có thể cần tối ưu hóa hiệu suất. Cấu trúc dữ liệu của ứng dụng có thể cần cập nhật hoặc mở rộng, và các chương trình ứng dụng mới có thể được phát triển để nâng cao chức năng của ứng dụng.
Sao lưu và khôi phục
Đôi khi cần khôi phục cơ sở dữ liệu về trạng thái trước đó vì nhiều lý do, chẳng hạn như lỗi phần mềm hoặc cập nhật dữ liệu sai. Để làm điều này, sao lưu dữ liệu được thực hiện định kỳ hoặc liên tục, lưu giữ trạng thái dữ liệu và cấu trúc của cơ sở dữ liệu trong các tệp sao lưu. Khi cần khôi phục, các tệp này được sử dụng để đưa cơ sở dữ liệu trở lại trạng thái đã lưu.
Phân tích tĩnh
Kỹ thuật phân tích tĩnh không chỉ áp dụng cho phần mềm mà còn cho các ngôn ngữ truy vấn. Cụ thể, khung giải thích * Tóm tắt đã được mở rộng sang ngôn ngữ truy vấn cho cơ sở dữ liệu quan hệ nhằm hỗ trợ các kỹ thuật gần đúng. Ngữ nghĩa của các ngôn ngữ truy vấn có thể được điều chỉnh theo sự trừu tượng phù hợp với miền dữ liệu cụ thể. Trừu tượng trong hệ thống cơ sở dữ liệu quan hệ có nhiều ứng dụng, đặc biệt là trong bảo mật như kiểm soát truy cập chi tiết, hình mờ, v.v.
Các tính năng khác
Các tính năng khác của DBMS có thể bao gồm:
- Nhật ký cơ sở dữ liệu - Giúp lưu lại lịch sử các hoạt động đã thực hiện.
- Thành phần đồ họa để tạo đồ thị và biểu đồ, đặc biệt trong hệ thống kho dữ liệu.
- Trình tối ưu hóa truy vấn - Tối ưu hóa các truy vấn để chọn cách thực thi truy vấn hiệu quả nhất (các bước thực hiện sẽ được sắp xếp để tính toán kết quả). Có thể tùy chỉnh cho từng công cụ lưu trữ cụ thể.
- Công cụ hoặc móc để thiết kế cơ sở dữ liệu, lập trình ứng dụng, bảo trì chương trình ứng dụng, giám sát và phân tích hiệu suất cơ sở dữ liệu, giám sát cấu hình cơ sở dữ liệu, cấu hình phần cứng DBMS (DBMS và cơ sở dữ liệu liên quan có thể trải rộng trên máy tính, mạng và đơn vị lưu trữ), ánh xạ cơ sở dữ liệu liên quan (đặc biệt là DBMS phân tán), phân bổ lưu trữ và giám sát bố cục cơ sở dữ liệu, di chuyển lưu trữ, v.v.
Ngày càng có nhiều yêu cầu tích hợp tất cả các chức năng cơ bản vào một hệ thống duy nhất để xây dựng, kiểm tra và triển khai quản lý cơ sở dữ liệu và kiểm soát nguồn. Dựa trên các xu hướng trong ngành phần mềm, một số thị trường đã xuất hiện như 'DevOps cho cơ sở dữ liệu'.
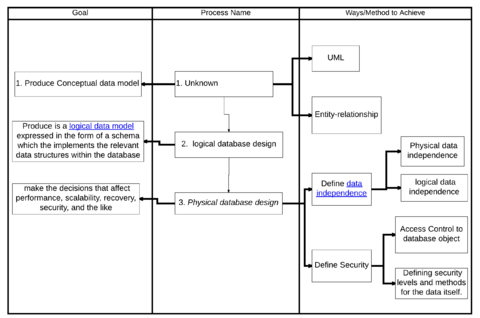
Thiết kế và mô hình
Nhiệm vụ đầu tiên của nhà thiết kế cơ sở dữ liệu là xây dựng một mô hình dữ liệu khái niệm phản ánh cấu trúc thông tin sẽ được lưu trữ trong cơ sở dữ liệu. Một cách phổ biến là phát triển mô hình quan hệ thực thể, thường dùng công cụ vẽ. Một phương pháp khác là Ngôn ngữ mô hình thống nhất. Mô hình dữ liệu thành công phải phản ánh chính xác tình trạng của thế giới bên ngoài: ví dụ, nếu một người có thể có nhiều số điện thoại, mô hình cần ghi nhận điều đó. Thiết kế mô hình dữ liệu khái niệm yêu cầu hiểu biết sâu về lĩnh vực ứng dụng; thường liên quan đến việc đặt câu hỏi chi tiết về những gì quan trọng với tổ chức, như 'khách hàng có thể đồng thời là nhà cung cấp không?' hoặc 'nếu sản phẩm có hai loại bao bì khác nhau, có phải là cùng một sản phẩm hay hai sản phẩm khác nhau?' hoặc 'nếu máy bay bay từ New York đến Dubai qua Frankfurt, đó có phải là một chuyến bay hay hai (hoặc ba)?' Các câu trả lời giúp xác định các định nghĩa về thuật ngữ cho các thực thể và các mối quan hệ của chúng.
Quá trình xây dựng mô hình dữ liệu khái niệm thường liên quan đến việc thu thập thông tin từ quy trình kinh doanh hoặc phân tích quy trình công việc trong tổ chức. Điều này giúp xác định thông tin cần thiết trong cơ sở dữ liệu và những gì có thể loại bỏ. Ví dụ, điều này giúp quyết định liệu cơ sở dữ liệu cần lưu trữ dữ liệu lịch sử cùng với dữ liệu hiện tại hay không.
Sau khi hoàn thiện mô hình dữ liệu khái niệm theo yêu cầu của người dùng, bước tiếp theo là chuyển đổi nó thành một lược đồ thực thi các cấu trúc dữ liệu trong cơ sở dữ liệu. Quá trình này được gọi là thiết kế cơ sở dữ liệu logic và kết quả là một mô hình dữ liệu lôgic dưới dạng lược đồ. Mặc dù mô hình dữ liệu khái niệm không phụ thuộc vào công nghệ cơ sở dữ liệu, mô hình dữ liệu lôgic sẽ được điều chỉnh theo mô hình cơ sở dữ liệu mà DBMS chọn. (Mô hình dữ liệu và mô hình cơ sở dữ liệu thường được dùng thay thế, nhưng trong bài viết này, mô hình dữ liệu chỉ thiết kế cơ sở dữ liệu cụ thể và mô hình cơ sở dữ liệu dùng để chỉ ký hiệu mô hình thể hiện thiết kế đó.)
Mô hình cơ sở dữ liệu phổ biến nhất cho các hệ thống đa năng là mô hình quan hệ, cụ thể là mô hình quan hệ được thể hiện bằng ngôn ngữ SQL. Quá trình thiết kế cơ sở dữ liệu logic với mô hình này sử dụng phương pháp chuẩn hóa. Mục tiêu của chuẩn hóa là đảm bảo rằng mỗi 'thực tế' cơ bản chỉ xuất hiện một lần, giúp các hoạt động chèn, cập nhật và xóa tự động duy trì tính nhất quán.
Giai đoạn cuối cùng trong thiết kế cơ sở dữ liệu là thực hiện các quyết định ảnh hưởng đến hiệu suất, khả năng mở rộng, phục hồi, bảo mật, và các yếu tố khác, tùy thuộc vào DBMS cụ thể. Đây được gọi là thiết kế cơ sở dữ liệu vật lý và đầu ra là mô hình dữ liệu vật lý. Mục tiêu chính là tính độc lập dữ liệu, tức là các quyết định tối ưu hóa hiệu suất sẽ không ảnh hưởng đến người dùng cuối và ứng dụng. Có hai loại độc lập dữ liệu: độc lập dữ liệu vật lý và độc lập dữ liệu logic. Thiết kế vật lý được định hướng chủ yếu bởi yêu cầu hiệu suất và cần hiểu biết sâu về khối lượng công việc, mẫu truy cập dự kiến và các tính năng của DBMS đã chọn.
Một yếu tố khác của thiết kế cơ sở dữ liệu vật lý là bảo mật. Điều này bao gồm việc xác định quyền truy cập cho các đối tượng cơ sở dữ liệu cũng như các mức và phương pháp bảo mật cho dữ liệu.
Mô hình
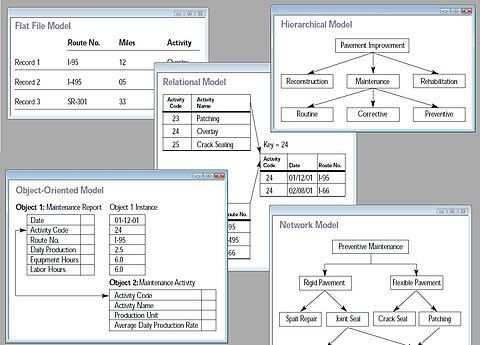
Mô hình cơ sở dữ liệu là dạng mô hình dữ liệu định nghĩa cấu trúc logic của cơ sở dữ liệu, xác định cách dữ liệu được lưu trữ, tổ chức và thao tác. Ví dụ điển hình nhất là mô hình quan hệ (hoặc phiên bản SQL của quan hệ), sử dụng định dạng bảng để tổ chức dữ liệu.
Các loại mô hình dữ liệu logic phổ biến cho cơ sở dữ liệu bao gồm:
- Cơ sở dữ liệu hướng đối tượng
- Mô hình cơ sở dữ liệu phân cấp
- Mô hình mạng
- Cơ sở dữ liệu đồ thị
- Mô hình quan hệ
- Mô hình quan hệ Entity
- Mô hình quan hệ thực thể nâng cao
- Mô hình đối tượng
- Mô hình tài liệu
- Mô hình giá trị thuộc tính Entity
- Lược đồ sao
Một cơ sở dữ liệu quan hệ đối tượng kết hợp hai cấu trúc dữ liệu liên quan với nhau.
Các kiểu mô hình dữ liệu vật lý bao gồm:
- Chỉ số ngược
- Tệp phẳng
Các kiểu mô hình khác bao gồm:
- Mô hình liên kết
- Mô hình đa chiều
- Mô hình mảng
- Mô hình đa giá trị
Các mô hình chuyên biệt được tối ưu hóa cho từng loại dữ liệu cụ thể:
- Cơ sở dữ liệu XML
- Mô hình ngữ nghĩa
- Cửa hàng nội dung
- Cửa hàng sự kiện
- Mô hình chuỗi thời gian
Các cấp độ xem bên ngoài, khái niệm và nội bộ
Một hệ thống quản lý cơ sở dữ liệu cung cấp ba dạng chế độ xem dữ liệu:
- Cấp độ bên ngoài xác định cách mà mỗi nhóm người dùng cuối nhìn nhận tổ chức dữ liệu trong cơ sở dữ liệu. Một cơ sở dữ liệu có thể có nhiều chế độ xem ở cấp độ bên ngoài.
- Cấp độ khái niệm kết hợp các quan điểm bên ngoài khác nhau thành một cái nhìn toàn diện và đồng nhất. Nó tổng hợp tất cả các cấp độ xem bên ngoài và không nằm trong phạm vi quan tâm của người dùng cuối, mà chủ yếu phục vụ các nhà phát triển và quản trị viên cơ sở dữ liệu.
- Cấp độ nội bộ (hoặc cấp độ vật lý) liên quan đến cách dữ liệu được tổ chức bên trong DBMS. Điều này bao gồm chi phí, hiệu suất, khả năng mở rộng và các vấn đề hoạt động khác. Nó bao gồm việc sắp xếp lưu trữ dữ liệu, sử dụng cấu trúc lưu trữ như chỉ mục để cải thiện hiệu suất, và đôi khi lưu trữ dữ liệu của các chế độ xem riêng lẻ (chế độ xem cụ thể) nếu điều đó có lợi cho hiệu suất. Nó cân bằng tất cả các yêu cầu hiệu suất từ các chế độ xem bên ngoài, có thể xung đột, nhằm tối ưu hóa hiệu suất tổng thể cho tất cả các hoạt động.
Mặc dù thường chỉ có một chế độ xem khái niệm (hoặc logic) và một chế độ xem vật lý (hoặc nội bộ) cho dữ liệu, số lượng chế độ xem bên ngoài có thể rất đa dạng. Điều này cho phép người dùng tiếp cận thông tin cơ sở dữ liệu theo cách phù hợp với nhu cầu kinh doanh, thay vì từ góc độ kỹ thuật. Ví dụ, bộ phận tài chính của công ty cần thông tin chi tiết về thanh toán của tất cả nhân viên cho mục đích chi phí, trong khi bộ phận nhân sự chỉ cần biết thông tin nhân viên mà không cần chi tiết thanh toán. Do đó, các phòng ban khác nhau yêu cầu quan điểm khác nhau về cơ sở dữ liệu của công ty.
Kiến trúc cơ sở dữ liệu ba cấp liên quan đến độc lập dữ liệu, một trong những yếu tố chính của mô hình quan hệ. Ý tưởng là các thay đổi ở một cấp độ không ảnh hưởng đến chế độ xem ở các cấp độ khác. Ví dụ, sự thay đổi ở cấp độ nội bộ không tác động đến các ứng dụng được xây dựng trên giao diện khái niệm, giúp giảm thiểu ảnh hưởng của việc thay đổi cấu trúc vật lý để cải thiện hiệu suất.
Khung nhìn khái niệm cung cấp một mức độ trừu tượng giữa các cấp độ bên trong và bên ngoài. Nó đưa ra một cái nhìn tổng quát về cơ sở dữ liệu, không phụ thuộc vào các cấu trúc cụ thể của các chế độ xem bên ngoài khác nhau, đồng thời che giấu các chi tiết về cách dữ liệu được lưu trữ hoặc quản lý (mức độ nội bộ). Về lý thuyết, mỗi cấp độ và thậm chí mỗi chế độ xem bên ngoài có thể được đại diện bởi một mô hình dữ liệu khác nhau. Tuy nhiên, trong thực tế, một DBMS cụ thể thường sử dụng cùng một mô hình dữ liệu cho cả cấp độ bên ngoài và khái niệm (chẳng hạn như mô hình quan hệ). Cấp độ bên trong, ẩn bên trong DBMS và phụ thuộc vào cách triển khai, yêu cầu mức độ chi tiết khác và sử dụng các cấu trúc dữ liệu riêng biệt.
Sự phân tách giữa các cấp độ bên ngoài, khái niệm, và bên trong là một đặc điểm quan trọng của việc triển khai mô hình cơ sở dữ liệu quan hệ, đặc trưng cho các hệ thống cơ sở dữ liệu hiện đại của thế kỷ 21.
Nghiên cứu
Công nghệ cơ sở dữ liệu đã là một lĩnh vực nghiên cứu sôi động từ những năm 1960, không chỉ trong giới học thuật mà còn trong các nhóm nghiên cứu và phát triển của các công ty, như nghiên cứu của IBM. Các hoạt động nghiên cứu bao gồm cả lý thuyết và phát triển các nguyên mẫu. Những chủ đề nghiên cứu nổi bật bao gồm các mô hình cơ sở dữ liệu, khái niệm giao dịch nguyên tử, các kỹ thuật kiểm soát đồng thời, ngôn ngữ truy vấn và tối ưu hóa truy vấn, cũng như RAID, và nhiều vấn đề khác.
Lĩnh vực nghiên cứu cơ sở dữ liệu có nhiều tạp chí học thuật chuyên ngành (như ACM Transactions on Database Systems - TODS, Data & Knowledge Engineering - DKE) và các hội nghị thường niên (như ACM SIGMOD, ACM PODS, VLDB, IEEE ICDE).
Chú thích
Sách tham khảo
- Bachman, Charles W. (1973). “The Programmer as Navigator”. Communications of the ACM. 16 (11): 653–658. doi:10.1145/355611.362534. Đã bỏ qua tham số không rõ
|subscription=(gợi ý|url-access=) (trợ giúp)
- Beynon-Davies, Paul (2003). Database Systems (ấn bản 3). Palgrave Macmillan. ISBN 978-1403916013.
- Chapple, Mike (2005). “SQL Fundamentals”. Databases. About.com. Lưu trữ bản gốc 22 tháng 2, 2009. Truy cập 28 tháng 1, 2009.
- Childs, David L. (1968a). “Description of a set-theoretic data structure” (PDF). CONCOMP (Research in Conversational Use of Computers) Project. Technical Report 3. University of Michigan.
- Childs, David L. (1968b). “Feasibility of a set-theoretic data structure: a general structure based on a reconstituted definition” (PDF). CONCOMP (Research in Conversational Use of Computers) Project. Technical Report 6. University of Michigan.
- Chong, Raul F.; Wang, Xiaomei; Dang, Michael; Snow, Dwaine R. (2007). “Introduction to DB2”. Understanding DB2: Learning Visually with Examples (ấn bản 2). ISBN 978-0131580183. Truy cập 17 tháng 3, 2013.
- Codd, Edgar F. (1970). “A Relational Model of Data for Large Shared Data Banks” (PDF). Communications of the ACM. 13 (6): 377–387. doi:10.1145/362384.362685.
- Connolly, Thomas M.; Begg, Carolyn E. (2014). Database Systems – A Practical Approach to Design Implementation and Management (ấn bản 6). Pearson. ISBN 978-1292061184.
- Date, C. J. (2003). An Introduction to Database Systems (ấn bản 8). Pearson. ISBN 978-0321197849.
- Halder, Raju; Cortesi, Agostino (2011). “Abstract Interpretation of Database Query Languages” (PDF). Computer Languages, Systems & Structures. 38 (2): 123–157. doi:10.1016/j.cl.2011.10.004. ISSN 1477-8424.
- Hershey, William; Easthope, Carol (1972). A set theoretic data structure and retrieval language. Spring Joint Computer Conference, May 1972. ACM SIGIR Forum. 7 (4). tr. 45–55. doi:10.1145/1095495.1095500.
- Nelson, Anne Fulcher; Nelson, William Harris Morehead (2001). Building Electronic Commerce: With Web Database Constructions. Prentice Hall. ISBN 978-0201741308.
- North, Ken (10 tháng 3, 2010). “Sets, Data Models and Data Independence”. Dr. Dobb's. Lưu trữ bản gốc 24 tháng 10, 2010.
- Tsitchizris, Dionysios C.; Lochovsky, Fred H. (1982). Data Models. Prentice–Hall. ISBN 978-0131964280.
- Ullman, Jeffrey; Widom, Jennifer (1997). A First Course in Database Systems. Prentice–Hall. ISBN 978-0138613372.
Những lĩnh vực chính của khoa học máy tính |
|---|
Mạng ngữ nghĩa |
|---|