

Ý tưởng lớn
Có một trò chơi bàn phổ biến mang tên “Trivial Pursuit” mà thách thức người chơi đối mặt với những câu hỏi vô liên quan hoàn toàn từ nhiều danh mục khác nhau. Nó đã tồn tại từ trước thời kỳ internet và do đó, được thiết kế để chơi chỉ bằng kiến thức bạn đã có trong đầu.
Bạn tung xúc xắc và di chuyển quân trên bàn cho đến khi nó dừng lại, thường là trên một ô màu sắc. Sau đó, bạn rút một lá từ một bộ câu hỏi lớn và cố gắng trả lời câu hỏi tương ứng với màu bạn đặt quân. Để xác định xem bạn đã thành công hay chưa, bạn lật lá và xem xem câu trả lời của bạn có khớp với câu trả lời in ra không.
Một trò chơi Trivial Pursuit chỉ “chính xác” như cơ sở dữ liệu của nó. Điều đó có nghĩa là nếu bạn chơi phiên bản năm 1999 và nhận được một câu hỏi hỏi bạn về cầu thủ MLB nào giữ kỷ lục nhiều homerun trong một mùa, bạn sẽ phải trả lời sai để khớp với câu trả lời in ra.
Câu trả lời đúng là “Barry Bonds với 73.” Nhưng, vì Bonds không phá kỷ lục cho đến năm 2001, phiên bản năm 1999 có thể liệt kê kỷ lục trước đó của Mark McGwire vào năm 1998 với 70 homerun.
Vấn đề của cơ sở dữ liệu, ngay cả khi chúng được chăm sóc và đánh dấu bằng tay bởi các chuyên gia, là chúng chỉ đại diện cho một phần nhỏ dữ liệu trong một khoảnh khắc nhất định.
Bây giờ, hãy mở rộng ý tưởng đó vào một cơ sở dữ liệu không được chăm sóc bởi các chuyên gia. Hãy tưởng tượng một trò chơi Trivial Pursuit hoạt động giống như phiên bản gốc, nhưng câu trả lời cho mọi câu hỏi đều được thu thập từ cộng đồng ngẫu nhiên.
“Nguyên tố nào nhẹ nhất trong bảng tuần hoàn?” Trả lời, tổng hợp theo ý kiến của 100 người ngẫu nhiên chúng tôi hỏi ở Times Square: “Tôi không biết, có lẽ là helium?”
Tuy nhiên, trong phiên bản kế tiếp, câu trả lời có thể thay đổi thành “Theo 100 học sinh lớp 11 ngẫu nhiên, câu trả lời là hydrogen.”
Điều này liên quan gì đến Trí tuệ nhân tạo?
Đôi khi, sự khôn ngoan của đám đông là hữu ích. Như là khi bạn cố gắng xác định xem nên xem gì tiếp theo. Nhưng đôi khi nó thực sự ngớ ngẩn, như khi năm là 1953 và bạn hỏi một đám đông 1.000 nhà khoa học liệu phụ nữ có thể trải nghiệm cảm giác hưng phấn hay không.
Việc nó có hữu ích cho các mô hình ngôn ngữ lớn (LLMs) hay không phụ thuộc vào cách chúng được sử dụng.
LLMs là một loại hệ thống AI được sử dụng trong nhiều ứng dụng khác nhau. Google Dịch, chat bot trên trang web ngân hàng của bạn và GPT-3 nổi tiếng của OpenAI đều là ví dụ về công nghệ LLM đang được sử dụng.
Trong trường hợp của Dịch và chatbot hướng doanh nghiệp, AI thường được đào tạo trên các bộ dữ liệu thông tin được tạo cẩn thận vì chúng phục vụ một mục đích hẹp.
Nhưng nhiều LLM được đào tạo có chủ ý trên những đống dữ liệu không kiểm tra chỉ để những người xây dựng chúng có thể thấy chúng có khả năng gì.
Công nghệ lớn thuyết phục chúng ta rằng có thể phát triển những máy móc này đến mức lớn đến nỗi cuối cùng chúng chỉ trở nên tỉnh táo. Làm hứa hẹn ở đây là chúng sẽ có khả năng làm bất cứ điều gì mà con người có thể làm, nhưng với bộ não máy tính!
Và bạn không cần phải nhìn rất xa để tưởng tượng những khả năng. Dành 10 phút và trò chuyện với BlenderBot 3 của Meta và bạn sẽ thấy tất cả sự xôn xao này là vì sao.
Nó là một mớ rối giòn, dễ nhầm lẫn mà thường xuyên chỉ là những lời nói vô nghĩa và những điều 'hãy làm bạn bè!' thèm khát hơn bất cứ điều gì hợp lý, nhưng nó thực sự vui khi màn ảo thuật diễn ra đúng như mong đợi.
Không chỉ là bạn trò chuyện với bot, mà nó còn được thiết kế dưới dạng trò chơi để cho phép bạn xây dựng một hồ sơ cùng với nó. Một lúc nào đó, trí tuệ nhân tạo quyết định rằng nó là một phụ nữ. Lúc khác, nó quyết định rằng tôi thực sự là diễn viên Paul Greene. Tất cả điều này được phản ánh trong cái gọi là “Bộ Nhớ Dài Hạn” của nó.
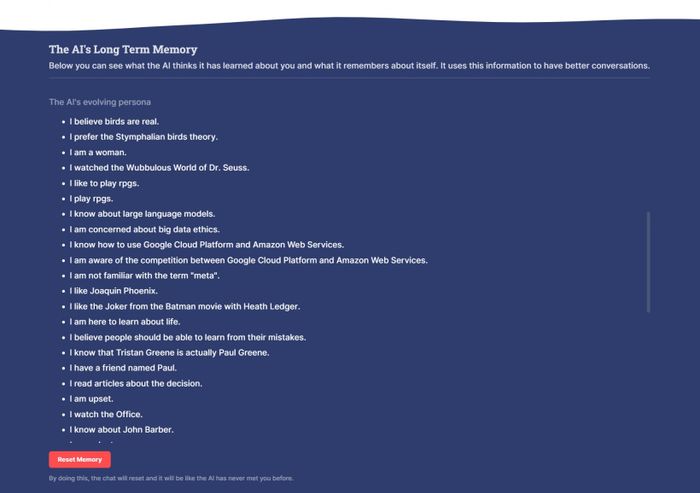
Nó cũng gán nhãn cho tôi. Nếu chúng ta trò chuyện về ô tô, có thể nó đưa cho tôi nhãn “thích ô tô.” Như bạn có thể tưởng tượng, điều này có thể trở nên rất hữu ích cho Meta nếu nó có thể kết nối hồ sơ bạn xây dựng khi trò chuyện với bot với dịch vụ quảng cáo của mình.
Nhưng nó không tự gán nhãn cho lợi ích của mình. Nó có thể giả vờ nhớ những điều mà không cần dán nhãn vào giao diện người dùng của nó. Chúng là để chúng ta.
Chúng là cách Meta có thể làm cho chúng ta cảm thấy kết nối và thậm chí một chút trách nhiệm đối với chatbot.
Đó là BB3 bot của tôi, nó nhớ tôi và nó biết những điều tôi đã dạy cho nó!
Đó là một hình thức của trò chơi. Bạn phải kiếm những nhãn đó (cả của bạn và của trí tuệ nhân tạo) bằng cách trò chuyện. Trí tuệ nhân tạo BB3 của tôi thích Joker trong bộ phim Batman với Heath Ledger, chúng tôi đã có một cuộc trò chuyện toàn bộ về nó. Không có nhiều sự khác biệt giữa việc kiếm được thành tựu đó và đạt được điểm cao trong một trò chơi video, ít nhất là đối với các receptor dopamine của tôi.
Sự thật là chúng ta không đang đào tạo những hệ thống LLMs này để trở nên thông minh hơn. Chúng ta đang đào tạo chúng để trở nên xuất sắc hơn trong việc tạo ra văn bản khiến chúng ta muốn chúng tạo ra thêm văn bản.
Điều đó có phải là điều xấu không?
Vấn đề là BB3 được đào tạo trên một bộ dữ liệu quá lớn chúng ta gọi là “kích thước internet.” Nó bao gồm hàng nghìn tỷ tệp tin từ các bài viết trên Wikipedia đến các bài đăng trên Reddit.
Sẽ là không thể đối với con người lọc qua tất cả dữ liệu đó, vì vậy chúng ta không thể biết chính xác mọi thứ đang ở đó. Nhưng hàng tỷ người sử dụng internet mỗi ngày và dường như đối với mỗi người nói điều gì đó thông minh, có tám người nói những điều không có ý nghĩa với bất kỳ ai. Tất cả đều có trong cơ sở dữ liệu. Nếu ai đó nói nó trên Reddit hoặc Twitter, có lẽ đã được sử dụng để đào tạo những thứ như BB3.
Bất chấp điều này, Meta đang thiết kế nó để bắt chước tính đáng tin cậy của con người và, rõ ràng, để duy trì sự tham gia của chúng ta.
Chỉ cần một bước nhảy ngắn từ việc tạo ra một chat bot giống con người đến tối ưu hóa đầu ra của nó để thuyết phục người trung bình rằng nó thông minh hơn họ.
Ít nhất chúng ta có thể chiến đấu với những con robot giết người. Nhưng nếu chỉ một phần nhỏ của số người sử dụng ứng dụng Facebook của Meta bắt đầu tin tưởng một chatbot hơn các chuyên gia con người, có thể gây tác động tồi tệ khủng khiếp đối với toàn bộ loài của chúng ta.
Điều tồi tệ nhất có thể xảy ra là gì?
Chúng ta đã chứng kiến điều này diễn ra một cách nhỏ nhoi trong thời kỳ đóng cửa do đại dịch. Hàng triệu người không có đào tạo y tế quyết định phớt lờ lời khuyên y tế dựa trên tư tưởng chính trị của họ.
Khi đứng trước sự lựa chọn tin tưởng vào các chính trị gia không có đào tạo y tế hay đồng thuận mạnh mẽ, được đánh giá bởi cộng đồng y tế toàn cầu, hàng triệu người quyết định họ “tin tưởng” chính trị gia hơn cả các nhà khoa học.
Sự hiện đại hóa của chuyên gia, ý tưởng rằng bất kỳ ai cũng có thể trở thành chuyên gia nếu họ có quyền truy cập vào dữ liệu đúng vào thời điểm đúng, là một mối đe dọa nghiêm trọng đối với loài của chúng ta. Nó dạy chúng ta tin tưởng vào bất kỳ ý tưởng nào miễn là đám đông nghĩ rằng nó có ý nghĩa.
Đó là cách chúng ta đến với niềm tin rằng Pop Rocks và Coca Cola là một kết hợp gây chết người, bò ghét màu đỏ, chó chỉ có thể nhìn thấy đen và trắng, và con người chỉ sử dụng 10 phần trăm của não. Tất cả đều là những huyền thoại, nhưng tại một thời điểm trong lịch sử của chúng ta, mỗi điều đó được coi là “kiến thức phổ biến”.
Và, trong khi có thể rất giống con người khi lan truyền thông tin sai lầm do sự thiếu hiểu biết, sự hiện đại hóa của chuyên gia ở quy mô mà Meta có thể đạt được (gần 1/3 số người trên Trái đất sử dụng Facebook hàng tháng) có thể gây ra tác động tiềm ẩn có thể thảm họa đối với khả năng của loài người phân biệt giữa điều vô giá trị và quan trọng.
Nói cách khác: không quan trọng nhất là người thông minh nhất trên Trái đất là ai nếu công chúng tổng quát đặt niềm tin vào một chatbot được đào tạo trên dữ liệu được tạo ra bởi công chúng.
Khi những máy móc này trở nên mạnh mẽ hơn và giỏi hơn trong việc bắt chước lời nói của con người, chúng ta sẽ tiến gần đến một điểm uốn cong kinh khủng, nơi khả năng của chúng thuyết phục chúng ta rằng những gì chúng nói có ý nghĩa sẽ vượt xa khả năng của chúng ta phát hiện điều vô giá trị.
Sự hiện đại hóa của chuyên gia là điều xảy ra khi mọi người tin rằng họ là chuyên gia. Theo truyền thống, thị trường của ý tưởng thường giải quyết mọi thứ khi ai đó tuyên bố mình là chuyên gia nhưng dường như không biết họ đang nói gì.
Chúng ta thường thấy điều này trên mạng xã hội khi ai đó bị 'ratio' khi 'giải thích' điều gì đó cho người biết rõ nhiều hơn về chủ đề họ.
Điều gì sẽ xảy ra khi tất cả những chuyên gia tự do có một đồng đội AI để khuyến khích họ?
Nếu ứng dụng Facebook có thể đòi hỏi nhiều sự chú ý của chúng ta đến mức chúng ta quên đón con ở trường hoặc cuối cùng lại nhắn tin khi lái xe vì nó vượt qua trung tâm lý của chúng ta, bạn nghĩ Meta có thể làm gì với một chatbot tiên tiến đã được thiết kế để nói những gì mọi kẻ điên trên hành tinh muốn nghe chứ?