

Tuần này, Intel đã tổ chức sự kiện Vision 2024 tại Phoenix, Arizona, để giới thiệu thông tin đầu tiên về kiến trúc chip xử lý trí tuệ nhân tạo Gaudi 3, một sản phẩm được phát triển bởi công ty con của họ, Havana Labs. Trước đó, Intel đã đề cập đến sức mạnh của Gaudi 2, với hiệu năng tiệm cận Nvidia H100. Tuy nhiên, với Gaudi 3, Intel tự tin rằng nó có thể vượt qua H100 trong nhiều tác vụ AI như vận hành các mô hình ngôn ngữ và dịch vụ AI phổ biến. Thời điểm ra mắt Gaudi 3 cũng là lúc Nvidia tung ra chip B200 kiến trúc Blackwell cho đối tác và khách hàng.
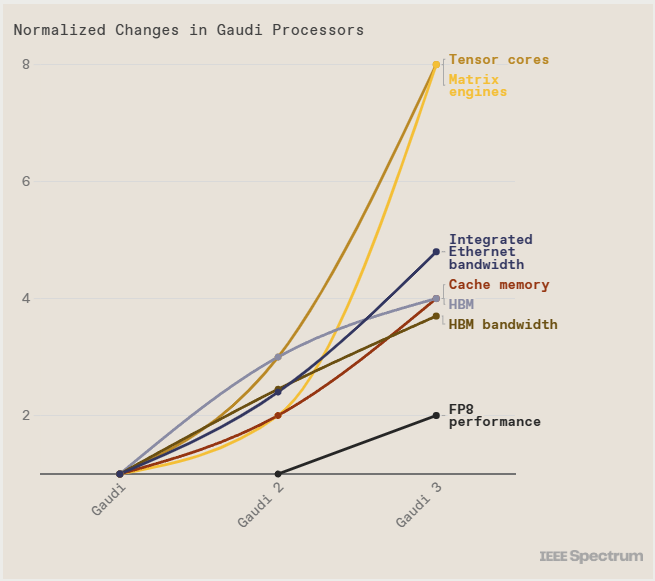 Intel cho biết, trong các thử nghiệm xử lý số thực dấu phẩy động 8-bit, Gaudi 3 có hiệu suất gấp đôi so với thế hệ trước. INT8 là chìa khóa cho việc huấn luyện các mô hình transformer. Với số thực dấu phẩy động BFloat 16, hiệu năng của Gaudi 3 tăng gấp 4 lần so với Gaudi 2.
Intel cho biết, trong các thử nghiệm xử lý số thực dấu phẩy động 8-bit, Gaudi 3 có hiệu suất gấp đôi so với thế hệ trước. INT8 là chìa khóa cho việc huấn luyện các mô hình transformer. Với số thực dấu phẩy động BFloat 16, hiệu năng của Gaudi 3 tăng gấp 4 lần so với Gaudi 2.Intel Gaudi 3 so với Nvidia H100
Tại sự kiện Vision 2024, Intel dự báo rằng, so với H100, tốc độ huấn luyện mô hình với 175 tỷ tham số như GPT-3 của Gaudi 3 sẽ nhanh hơn 40%. Các mô hình từ 7 đến 8 tỷ tham số như LLaMa 2 của Meta cũng sẽ tạo ra chênh lệch hiệu năng lớn hơn, rút ngắn thời gian huấn luyện mô hình ngôn ngữ.Về hiệu năng nội suy dữ liệu từ mô hình ngôn ngữ, Gaudi 3 tạo ra hiệu năng tương đương 95 đến 170% so với H100 của Nvidia với hai phiên bản mô hình LLaMa của Meta. Với mô hình Falcon 180B, 180 tỷ tham số, Gaudi 3 cũng tạo ra hiệu năng nội suy văn bản nhanh gấp 4 lần so với H100 trong một số trường hợp.
So với H200, sức mạnh của Gaudi 3 dao động từ 80 đến 110% hiệu năng H100 với LLaMa, và vận hành Falcon 180B nhanh hơn 3.8 lần.
Intel Gaudi 3 so với Nvidia B200
Hiện tại, cả hai sản phẩm này đều chưa chính thức ra mắt và chưa được triển khai trong các trung tâm dữ liệu chạy dịch vụ AI phục vụ hàng chục, hàng trăm triệu người trên toàn cầu. Tuy nhiên, có một số thông số kỹ thuật có thể so sánh giữa Gaudi 3 và B200. Trong đó, dung lượng và băng thông bộ nhớ HBM trên die của chip xử lý AI là vô cùng quan trọng.
Ngoài sức mạnh xử lý của các nhân tensor và ma trận, dung lượng bộ nhớ là yếu tố quan trọng với ngành nghiên cứu và triển khai AI. Với các mô hình AI hiện nay có hàng chục tỷ tham số, hai khía cạnh này trở nên ngày càng quan trọng hơn.
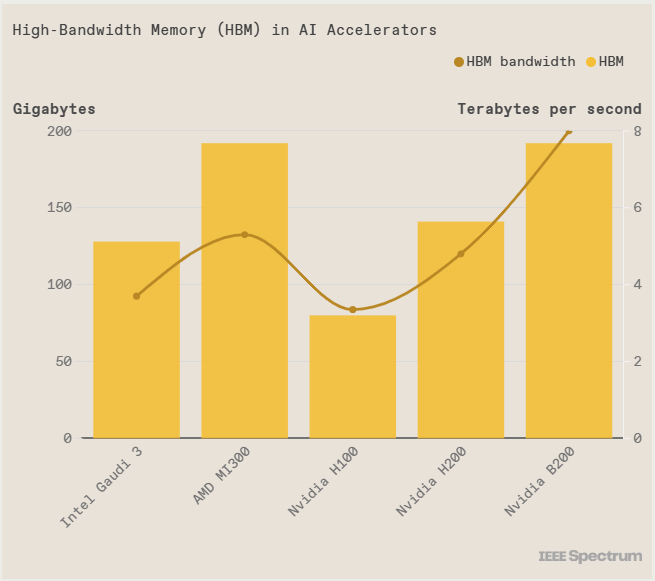
Cả Intel Gaudi 3 và Nvidia B200 đều được trang bị bộ nhớ RAM HBM, được xếp lớp DRAM lên bộ điều khiển để cung cấp dữ liệu cho chip xử lý. Để các cụm HBM này có thể được tích hợp trực tiếp vào các nhân tensor và ma trận trên chip xử lý AI, cần sử dụng các công nghệ đóng gói chip cao cấp nhất hiện nay, như cầu nối silic EMIB của Intel hoặc CoWoS của TSMC, tạo ra các kết nối băng thông cao giữa bộ nhớ và chip logic.
Gaudi 3 có dung lượng bộ nhớ lớn hơn so với Nvidia H100, nhưng thua kém so với H200, B200 của Nvidia và Instinct MI300 của AMD. Sử dụng công nghệ chip nhớ HBM2e thay vì HBM3, như trong 4 sản phẩm được so sánh, có thể tạo ra lợi thế cạnh tranh về giá mỗi con chip mà Intel cung cấp cho khách hàng.
Một điểm nữa cần lưu ý, Gaudi 3 được sản xuất trên tiến trình N5 của TSMC thay vì Intel 7 hoặc Intel 4. Trong khi đó, Blackwell B200 được sản xuất trên tiến trình N4 của TSMC, một phiên bản nâng cấp 5nm của N3, hiện đang được sử dụng để sản xuất chip xử lý tiêu dùng cho Apple, có trong iPhone và Mac. Theo TSMC, N4P mang lại cải tiến về hiệu suất 11%, hiệu quả tiêu thụ điện tăng 22% và mật độ transistor tăng 6% so với N5.
Theo IEEE Spectrum