

Năm năm trước, nhà khoa học máy tính Alan Fern và các đồng nghiệp tại Đại học Oregon, thành phố nhỏ Corvallis, đã bắt đầu tìm kiếm câu trả lời cho một trong những câu hỏi quan trọng nhất về trí tuệ nhân tạo (AI): liệu họ có thể hiểu được cách mà AI suy luận, đưa ra quyết định và lựa chọn hành động của mình hay không?
Con người không thể hiểu hướng đi của một số trò chơi từ năm 1980
Bằng chứng cho khám phá của họ xuất phát từ ba trò chơi arcade cổ điển vào những năm 1980, bao gồm Pong và Space Invaders. Trong các trò chơi này, máy tính học từ các sai lầm và thử nghiệm của mình để phát triển các quy tắc nội bộ, không tuân theo trực giác con người và khó hiểu.
Ban đầu, Fern và đồng nghiệp của ông rất lạc quan, phát triển phương pháp để hiểu sự chú ý của AI trong trò chơi. Tuy nhiên, họ gặp khó khăn trong việc giải mã các chiến lược chiến thắng của nó.
Nhóm nghiên cứu của Fern là một trong 11 nhóm tham gia dự án XAI do DARPA tài trợ, với mục tiêu giúp quân đội hiểu và quản lý hiệu quả các ứng dụng trí tuệ nhân tạo trong môi trường quân sự.
Tuy nhiên, tầm quan trọng của XAI không chỉ giới hạn trong lĩnh vực quân sự. Các nhà nghiên cứu lo ngại rằng sự thiếu hiểu biết về các hệ thống AI có thể làm mất lòng tin của người dùng trong mọi lĩnh vực. Điều này có thể không quá nguy hiểm khi chơi trò chơi hoặc sử dụng các ứng dụng như Uber.
Nhưng vấn đề trở nên nghiêm trọng hơn khi đối diện với các lĩnh vực như y tế hoặc quân sự, nơi sự hiểu biết thiếu về quyết định của AI có thể gây ra hậu quả không lường trước. Cũng đối diện với nguy cơ sai lệch hoặc sai sót trong suy luận, đặc biệt là trong các ứng dụng như ChatGPT và GPT-4.
Matt Turek, một nhà khoa học máy tính tại DARPA, cho biết việc hiểu rõ về AI có thể không bao giờ là một giải pháp chung cho mọi người. Tuy nhiên, với AI ngày càng thâm nhập vào cuộc sống, việc mở hộp đen của nó trở nên càng quan trọng hơn bao giờ hết.
Bí mật của các con số
Thuật ngữ “trí tuệ nhân tạo” thường ám chỉ các chương trình máy tính có khả năng giải quyết các vấn đề mà trước đó chỉ có con người có thể làm được. Mặc dù không phải mọi thuật toán đều phức tạp và khó hiểu. Ví dụ, một nhóm thuật toán được gọi là cây quyết định sử dụng một loạt các bài kiểm tra cụ thể để phân loại thông tin, và quy trình ra quyết định của chúng rất minh bạch.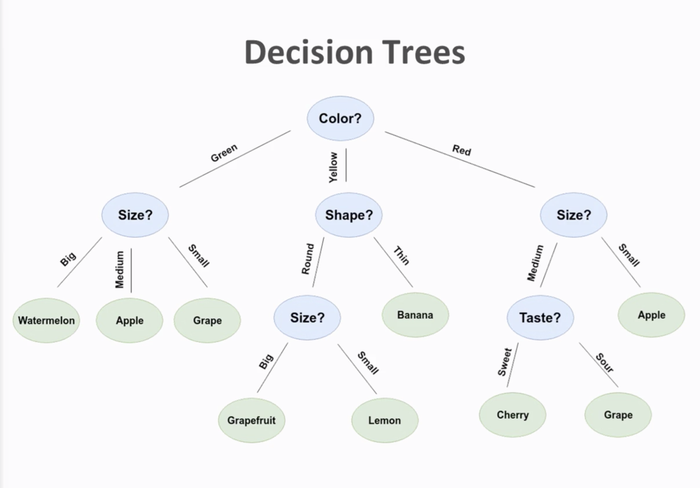 Một ví dụ về thuật toán cây quyết định để phân loại loại trái cây. Mỗi nút trên cây đại diện cho một bài kiểm tra cụ thể, đảm bảo rằng quyết định tại mỗi bước đều rõ ràng và chính xác. Ảnh: LinkedIn.
Trong thập kỷ gần đây, sự quan tâm đến các phương pháp AI tiên tiến đã tăng mạnh, trong đó có mạng thần kinh sâu (deep neural networks) được hình thành từ các nút tính toán. Cấu trúc của chúng bao gồm nhiều lớp, trong đó mỗi lớp đều có những kết nối phức tạp giữa các nút, và quá trình học sâu liên quan đến việc điều chỉnh các trọng số này để tạo ra đầu ra chính xác từ đầu vào.
Một so sánh giữa mạng thần kinh sâu và sơ đồ cây. Trong khi sơ đồ cây có cấu trúc đơn giản và ít lựa chọn, mạng thần kinh sâu có hàng tỷ trọng số khác nhau, làm cho quá trình ra quyết định của nó trở nên phức tạp và khó hiểu.
Điều này khiến cho mạng thần kinh sâu trở nên khó hiểu hơn. Ví dụ, ChatGPT mã hóa thông tin vào hàng tỷ trọng số, làm cho quyết định của nó trở nên mơ hồ và khó giải thích chỉ bằng cách kiểm tra các trọng số.
Một ví dụ về thuật toán cây quyết định để phân loại loại trái cây. Mỗi nút trên cây đại diện cho một bài kiểm tra cụ thể, đảm bảo rằng quyết định tại mỗi bước đều rõ ràng và chính xác. Ảnh: LinkedIn.
Trong thập kỷ gần đây, sự quan tâm đến các phương pháp AI tiên tiến đã tăng mạnh, trong đó có mạng thần kinh sâu (deep neural networks) được hình thành từ các nút tính toán. Cấu trúc của chúng bao gồm nhiều lớp, trong đó mỗi lớp đều có những kết nối phức tạp giữa các nút, và quá trình học sâu liên quan đến việc điều chỉnh các trọng số này để tạo ra đầu ra chính xác từ đầu vào.
Một so sánh giữa mạng thần kinh sâu và sơ đồ cây. Trong khi sơ đồ cây có cấu trúc đơn giản và ít lựa chọn, mạng thần kinh sâu có hàng tỷ trọng số khác nhau, làm cho quá trình ra quyết định của nó trở nên phức tạp và khó hiểu.
Điều này khiến cho mạng thần kinh sâu trở nên khó hiểu hơn. Ví dụ, ChatGPT mã hóa thông tin vào hàng tỷ trọng số, làm cho quyết định của nó trở nên mơ hồ và khó giải thích chỉ bằng cách kiểm tra các trọng số. Một mạng nơ-ron sâu được sử dụng để nhận diện hình ảnh có chứa hình ảnh của con chim hay không. Cấu trúc phức tạp của mạng này bao gồm nhiều lớp và mỗi lớp chứa nhiều nút với các trọng số khác nhau. Các đường đi trong mạng nơ-ron này thường chồng chéo lên nhau, tạo ra sự phức tạp trong việc xử lý thông tin. Ảnh: Analytics Vidhya.
Các mạng nơ-ron sâu đã đem lại nhiều tiến bộ đáng kể trong lĩnh vực trí tuệ nhân tạo, từ hỗ trợ chẩn đoán bệnh cho các bác sĩ đến tạo ra các hình ảnh mang phong cách của các nghệ sĩ nổi tiếng, cũng như việc sáng tác văn bản giống con người và phát triển các phương tiện tự động.
Hiểu biết về các mạng nơ-ron sâu trở nên ngày càng quan trọng. Ví dụ, trong lĩnh vực y tế, các hệ thống AI được sử dụng để hỗ trợ các bác sĩ trong việc chẩn đoán các bệnh từ nhẹ đến nặng, giúp phân loại bệnh nhân và đưa ra quyết định chăm sóc phù hợp. Nếu người dùng không hiểu rõ về hoạt động của các hệ thống AI này, họ có thể không tin tưởng hoặc sử dụng chúng một cách hiệu quả. 'Những lời giải thích thực sự làm tăng niềm tin,' ông Turek nói.
Một mạng nơ-ron sâu được sử dụng để nhận diện hình ảnh có chứa hình ảnh của con chim hay không. Cấu trúc phức tạp của mạng này bao gồm nhiều lớp và mỗi lớp chứa nhiều nút với các trọng số khác nhau. Các đường đi trong mạng nơ-ron này thường chồng chéo lên nhau, tạo ra sự phức tạp trong việc xử lý thông tin. Ảnh: Analytics Vidhya.
Các mạng nơ-ron sâu đã đem lại nhiều tiến bộ đáng kể trong lĩnh vực trí tuệ nhân tạo, từ hỗ trợ chẩn đoán bệnh cho các bác sĩ đến tạo ra các hình ảnh mang phong cách của các nghệ sĩ nổi tiếng, cũng như việc sáng tác văn bản giống con người và phát triển các phương tiện tự động.
Hiểu biết về các mạng nơ-ron sâu trở nên ngày càng quan trọng. Ví dụ, trong lĩnh vực y tế, các hệ thống AI được sử dụng để hỗ trợ các bác sĩ trong việc chẩn đoán các bệnh từ nhẹ đến nặng, giúp phân loại bệnh nhân và đưa ra quyết định chăm sóc phù hợp. Nếu người dùng không hiểu rõ về hoạt động của các hệ thống AI này, họ có thể không tin tưởng hoặc sử dụng chúng một cách hiệu quả. 'Những lời giải thích thực sự làm tăng niềm tin,' ông Turek nói.Khám phá bên trong cơ chế của Trí Tuệ Nhân Tạo
Để thực hiện mục tiêu này, DARPA đã bắt đầu chương trình XAI vào năm 2015, dưới sự lãnh đạo của nhà khoa học máy tính David Gunning của DARPA. (Turek sau đó tiếp quản chương trình vào năm 2018.) Chương trình được thúc đẩy bởi sự tiến bộ của các mạng nơ-ron sâu, ví dụ như việc phân loại hình ảnh chính xác. Các nhà nghiên cứu nhận ra tiềm năng lớn của những hệ thống này, nhưng cũng ngày càng lo ngại về tính mờ nhạt tương tự như hộp đen của chúng. Một số hệ thống Trí Tuệ Nhân Tạo cũng đưa ra kết quả đáng lo ngại cần phải được giải thích, như các xu hướng gia tăng phân biệt chủng tộc hoặc các định kiến khác tiềm ẩn trong dữ liệu huấn luyện của chúng.Lớp thứ hai sẽ bao gồm các mô hình không chỉ dự đoán mà còn đưa ra giải thích mà con người có thể hiểu được.mô phỏngmột mô hình có khả năng phân loại một cách hiệu quả những gì đã diễn ra bên trong hộp đen, thậm chí không cần phải xem xét bên trongTôi tin rằng điều quan trọng nhất của điều này là có thể phân loại các tình huống khẩn cấp một cách dễ dàng và không gây tranh cãi.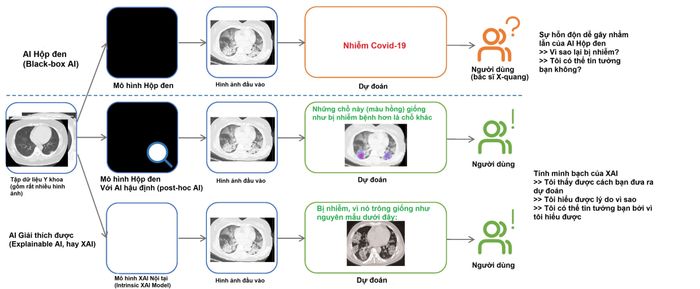 Biểu đồ so sánh trực quan giữa AI 'hộp đen' và AI có khả năng tự giải thích, và cách mà kết quả ảnh hưởng đến người dùng. Nhánh trên cùng thể hiện quy trình của mô hình 'hộp đen'. Thông thường, nó chỉ cung cấp các kết quả là các loại phân loại (ví dụ: COVID hoặc không phải COVID). Hai nhánh còn lại (ở giữa và dưới cùng) đại diện cho hai phương pháp XAI. Cụ thể, mô hình XAI ở giữa biểu thị ví dụ về bản đồ độ nổi bật và mô hình thứ hai (ở dưới cùng) là phương pháp nguyên mẫu, tức là so sánh với hình chụp thực tế của bệnh nhân. Ảnh: MDPI
Biểu đồ so sánh trực quan giữa AI 'hộp đen' và AI có khả năng tự giải thích, và cách mà kết quả ảnh hưởng đến người dùng. Nhánh trên cùng thể hiện quy trình của mô hình 'hộp đen'. Thông thường, nó chỉ cung cấp các kết quả là các loại phân loại (ví dụ: COVID hoặc không phải COVID). Hai nhánh còn lại (ở giữa và dưới cùng) đại diện cho hai phương pháp XAI. Cụ thể, mô hình XAI ở giữa biểu thị ví dụ về bản đồ độ nổi bật và mô hình thứ hai (ở dưới cùng) là phương pháp nguyên mẫu, tức là so sánh với hình chụp thực tế của bệnh nhân. Ảnh: MDPIAI tự giải thích được chính mình thì đáng tin cậy hơn
Turek cho biết, các nhà nghiên cứu hàng đầu trong cộng đồng AI từng nghi ngờ rằng những lời giải thích tốt hơn có thể dẫn đến hiệu suất kém hơn, nhưng một số dự án của DARPA đã chứng minh ngược lại. Trong một số trường hợp, các mô hình được đào tạo để đưa ra lời giải thích đã cho kết quả tốt hơn so với các mô hình không thể giải thích được. Turek nói: “Điều này là điều chúng tôi không mong đợi và chắc chắn không trực giác từ đầu.' Nhóm của Yuan là một ví dụ điển hình. Trước khi gia nhập Meta, Yuan đã tham gia vào một dự án tại Đại học California Los Angeles để phát triển một trò chơi dựa trên trí tuệ nhân tạo, tương tự như trò chơi Minesweeper, trong đó một rô-bốt trinh sát tự động điều hướng qua một cánh đồng nguy hiểm đầy bom. Khi AI ra quyết định, nó sẽ gửi các mô tả bằng ngôn ngữ đơn giản về lý do hành động của nó cho người dùng, người này có thể đưa ra phản hồi. Chẳng hạn, dựa trên sở thích của người dùng về tuyến đường nhanh nhất, ngắn nhất hoặc an toàn nhất, rô-bốt sẽ điều chỉnh lý do và hành vi của mình. Hầu hết các hệ thống AI được xây dựng để đạt được một mục tiêu cụ thể, Yuan nói, nhưng rô-bốt trinh sát của Yuan có thể chuyển sang một nhiệm vụ mới do tương tác với người dùng. Ông nói: “Mục tiêu có thể thay đổi bất cứ lúc nào, nhưng không có cách nào chúng tôi có thể lập trình điều đó vào mô hình.' Quân đội là một trong những tổ chức sử dụng trí tuệ nhân tạo để thực hiện các nhiệm vụ công nghệ cao, tính hệ trọng cao và tiềm ẩn nguy hiểm. Hiểu rõ cách mà AI ra quyết định có thể giúp người dùng quản lý, gỡ lỗi hiệu quả hơn và quan trọng hơn là tin tưởng vào các đối tác máy móc của họ. Ảnh: Shutterstock/sibky2016.Một hệ thống có khả năng đưa ra lời khuyên được xem là đáng tin cậy hơn đối với người dùng so với một hệ thống không có khả năng giải thích.
Quân đội là một trong những tổ chức sử dụng trí tuệ nhân tạo để thực hiện các nhiệm vụ công nghệ cao, tính hệ trọng cao và tiềm ẩn nguy hiểm. Hiểu rõ cách mà AI ra quyết định có thể giúp người dùng quản lý, gỡ lỗi hiệu quả hơn và quan trọng hơn là tin tưởng vào các đối tác máy móc của họ. Ảnh: Shutterstock/sibky2016.Một hệ thống có khả năng đưa ra lời khuyên được xem là đáng tin cậy hơn đối với người dùng so với một hệ thống không có khả năng giải thích.Tuy nhiên, không phải mọi lời giải thích đều đáng tin
Một thách thức lớn là đánh giá được mức độ tin cậy và toàn diện của một lời giải thích để áp dụng trong thực tế. Sau khi Fern thất vọng với kết quả không nhất quán từ các hệ thống AI chơi game arcade của mình, ông đã nghiên cứu kỹ lưỡng các nghiên cứu khác tuyên bố đã làm sáng tỏ bí ẩn của mạng nơ-ron - và ông đã tìm thấy những gì mình mong muốn. Ví dụ, một số nhóm tuyên bố rằng việc kích hoạt các nút tính toán trong mạng nơ-ron của họ tương ứng với một số mẩu thông tin cụ thể, mặc dù sự tương ứng chỉ chính xác trong 60% thời gian, Fern nói. “Nhưng nếu tôi đang nói chuyện với bạn và mỗi khi bạn nói 'mèo', và điều đó chỉ có nghĩa là 'mèo' trong 60% thời gian, thì bạn không phải là người đáng tin cậy để nói chuyện.'Chúng ta có thể hiểu ý kiến của ông Fern thông qua ví dụ sau: Giả sử bạn đang trò chuyện qua mạng với một người mù (đóng vai trò như AI) và muốn hỏi anh ta thấy con vật gì trong sân nhà. Người đó có thể nhận biết một cách mập mờ con gà đang ở đó. Tuy nhiên, vì anh ta không thấy rõ con vật và chỉ chạm vào nó trong 60% thời gian, 40% còn lại không chạm vào được, dù anh ấy vẫn khẳng định rằng đó là con gà. Do đó, người mù đó không phải là một người đáng tin cậy khi bạn muốn xác định con vật nào đang ở trong sân, và với AI cũng tương tự như vậy. Trong một cuộc trò chuyện năm 2019 có tựa đề “Đừng để bị đánh lừa bởi những lời giải thích,” ông tỏ ra nghi ngờ về các kết quả đã được công bố tuyên bố sẽ “giải thích” cách AI nhận dạng hình ảnh hoạt động. “Ở một mức độ nào đó, mớ hỗn độn này giống như việc xem bói trên lá trà,” Fern nói. Rudin, từ trường Đại học Duke, chỉ ra rằng nếu một lời giải thích sai dù chỉ là 10%, thì có thể nó không đáng tin cậy. Bà nói: “Hơn nữa, 10% đó có lẽ là 10% dữ liệu khó phân loại và quan trọng nhất.”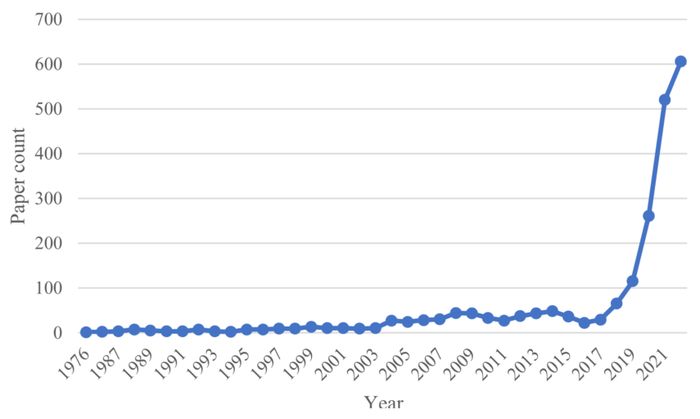 Số lượng công trình về XAI được thêm vào mỗi năm từ 1976 đến 2021. Trục ngang biểu thị năm xuất bản và trục đứng thể hiện số lượng công trình được thêm vào trong một năm nhất định. Ảnh: MDPI
Fern cho biết, việc xây dựng AI có thể diễn giải và giải thích có một mục tiêu quan trọng, ngay cả khi không phải là điều mà các nhà nghiên cứu đã tưởng tượng ban đầu. Ông nghĩ rằng việc tạo ra các lời giải thích sẽ hữu ích trong việc gỡ lỗi hệ thống—ví dụ: nếu hệ thống AI của xe hơi có thể giải thích cách nó nhầm một chiếc xe tải với một cây cối hoặc tại sao nó lại nghĩ rằng nhiễm trùng phổi là một khối u khi chụp CT, thì các lập trình viên có thể gỡ lỗi thuật toán được. “Nếu một lời giải thích dường như sai lầm, thì có thể chỉ ra một vấn đề trong hệ thống,” Fern nói.
Ngoài ra, mong đợi mọi thuật toán đều có khả năng tự giải thích một cách tương tự là không thực tế, Fern nói thêm. Ông nhấn mạnh: “Nhận được một điều gì đó mà con người có thể hiểu (lời giải thích) cho nhiều vấn đề thực sự khó khăn mà mạng lưới thần kinh đang giải quyết là điều không thể.” Đồng thời, nghiên cứu về XAI, bao gồm cả những khám phá của nhóm của Fern, đã chỉ ra rằng việc hiểu khả năng giải thích là một thách thức lớn. Ông lưu ý: “Ngay cả con người cũng không biết tất cả những yếu tố góp phần vào quyết định của họ.” Ý của ông là nếu con người không hiểu hết thì cũng đừng mong AI hiểu hết mọi thứ liên quan đến quyết định của nó. Tuy nhiên, Fern tin rằng có thể cải thiện sự hiểu biết về cách các hệ thống này hoạt động thông qua những tiến bộ trong cả lĩnh vực máy tính và nhận thức.
Khi các ứng dụng thực tế ngày càng dựa vào các quyết định của hệ thống AI, việc hiểu cách quy trình ra quyết định hoạt động sẽ trở nên cực kỳ quan trọng để xây dựng lòng tin và tránh gây hại. Shafto nói: “Chúng tôi mong muốn thấy những kết quả tốt hơn.”
Trích từ báo cáo của Stephen Ornes, PNAS
Số lượng công trình về XAI được thêm vào mỗi năm từ 1976 đến 2021. Trục ngang biểu thị năm xuất bản và trục đứng thể hiện số lượng công trình được thêm vào trong một năm nhất định. Ảnh: MDPI
Fern cho biết, việc xây dựng AI có thể diễn giải và giải thích có một mục tiêu quan trọng, ngay cả khi không phải là điều mà các nhà nghiên cứu đã tưởng tượng ban đầu. Ông nghĩ rằng việc tạo ra các lời giải thích sẽ hữu ích trong việc gỡ lỗi hệ thống—ví dụ: nếu hệ thống AI của xe hơi có thể giải thích cách nó nhầm một chiếc xe tải với một cây cối hoặc tại sao nó lại nghĩ rằng nhiễm trùng phổi là một khối u khi chụp CT, thì các lập trình viên có thể gỡ lỗi thuật toán được. “Nếu một lời giải thích dường như sai lầm, thì có thể chỉ ra một vấn đề trong hệ thống,” Fern nói.
Ngoài ra, mong đợi mọi thuật toán đều có khả năng tự giải thích một cách tương tự là không thực tế, Fern nói thêm. Ông nhấn mạnh: “Nhận được một điều gì đó mà con người có thể hiểu (lời giải thích) cho nhiều vấn đề thực sự khó khăn mà mạng lưới thần kinh đang giải quyết là điều không thể.” Đồng thời, nghiên cứu về XAI, bao gồm cả những khám phá của nhóm của Fern, đã chỉ ra rằng việc hiểu khả năng giải thích là một thách thức lớn. Ông lưu ý: “Ngay cả con người cũng không biết tất cả những yếu tố góp phần vào quyết định của họ.” Ý của ông là nếu con người không hiểu hết thì cũng đừng mong AI hiểu hết mọi thứ liên quan đến quyết định của nó. Tuy nhiên, Fern tin rằng có thể cải thiện sự hiểu biết về cách các hệ thống này hoạt động thông qua những tiến bộ trong cả lĩnh vực máy tính và nhận thức.
Khi các ứng dụng thực tế ngày càng dựa vào các quyết định của hệ thống AI, việc hiểu cách quy trình ra quyết định hoạt động sẽ trở nên cực kỳ quan trọng để xây dựng lòng tin và tránh gây hại. Shafto nói: “Chúng tôi mong muốn thấy những kết quả tốt hơn.”
Trích từ báo cáo của Stephen Ornes, PNAS