
 Tiếp tục phân tích về kiến trúc AMD Zen 5. Ở phần 1, mình đã điểm qua những thách thức và cách AMD phát triển Zen 5 dựa trên tầm nhìn của các nhà lãnh đạo. Trong phần 2, mình sẽ đi sâu vào từng khía cạnh của kiến trúc Zen 5, từ front-end đến back-end cùng những kết luận sơ bộ. Mình sẽ dựa trên kết quả thử nghiệm từ các nguồn quốc tế, vì thiếu thời gian và sản phẩm thử nghiệm ở Việt Nam, nên sẽ có dịp khác để cập nhật thêm.
Tiếp tục phân tích về kiến trúc AMD Zen 5. Ở phần 1, mình đã điểm qua những thách thức và cách AMD phát triển Zen 5 dựa trên tầm nhìn của các nhà lãnh đạo. Trong phần 2, mình sẽ đi sâu vào từng khía cạnh của kiến trúc Zen 5, từ front-end đến back-end cùng những kết luận sơ bộ. Mình sẽ dựa trên kết quả thử nghiệm từ các nguồn quốc tế, vì thiếu thời gian và sản phẩm thử nghiệm ở Việt Nam, nên sẽ có dịp khác để cập nhật thêm.Front-end
Vì đã đề cập nhiều về decoder trong phần 1 nên mình sẽ không nhắc lại nữa. Bên cạnh decoder, các thành phần khác như Bộ đệm Tập lệnh (L1I Cache), Bộ tiên đoán nhánh (BPU), và Bộ đệm Vi lệnh (Op Cache) cũng đóng vai trò quan trọng. Đặc biệt, các thành phần này có vẻ như được nhân đôi để phù hợp với bộ decoder kép đã được đề cập trước đó.
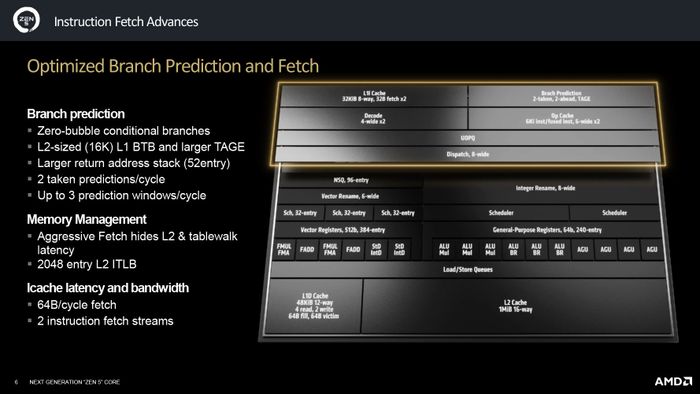
Front-end của Zen 5 với nhiều bộ phận được nhân đôi theo decoder
Trong cấu trúc vi xử lý, BPU có vai trò tương tự như CEO của một công ty. Nó dự đoán các nhánh công việc tiếp theo cần thực hiện để từ đó chuẩn bị danh sách các lệnh cần thiết cho chu kỳ xử lý tiếp theo. Nếu BPU dự đoán sai, các lệnh gửi xuống sẽ trở nên vô nghĩa và quá trình tính toán sẽ không hiệu quả, gây thiệt hại cho hiệu suất làm việc. Trên Zen 5, BPU mới hỗ trợ dự đoán có điều kiện bằng cơ chế zero-bubble. Bộ L1 BTB đã được mở rộng đáng kể so với Zen 4, từ 1.5K lên 16K! Bộ stack địa chỉ trả về cũng được mở rộng hơn (32 vs. 52 entry). Kết quả là BPU Zen 5 có khả năng dự đoán đến 3 cửa sổ/chu kỳ (so với 2 cửa sổ của BPU Zen 4).
Xử lý số nguyên
Phần Execution có thể là điểm khác biệt lớn giữa AMD và Intel. Trong khi Intel bổ sung thêm một lớp OoO để phân loại và tách biệt các vi lệnh INT/FPU, AMD lại phân loại theo chu kỳ (hoặc INT hoặc FPU). Tùy thuộc vào loại vi lệnh, mỗi loại sẽ có Bộ chia lịch (Scheduler) hoặc Bộ sửa tên (Rename) riêng. Bộ Rename INT ở đây cũng có bề rộng 8-wide tương ứng với Dispatch đã nói ở trên.

INT trên Zen 5 có 6 ALU và 4 AGU
Dù vậy, INT trên Zen 5 chỉ có 6 ALU và 4 AGU, tăng từ 4 ALU và 3 AGU trên Zen 4. Tuy nhiên, Decoder Zen 4 có bề rộng 4-wide, dẫn đến Execution trên Zen 4 dư thừa so với Front-end. Do đó, INT Zen 5 có phần không đồng đều so với Front-end. Điểm cộng là việc phân chia vi lệnh theo chu kỳ cho phép Front-end gửi nhiệm vụ cho FPU khi INT đang bận và ngược lại. Trong thiết kế chip, các thế hệ kiến trúc đầu tiên thường không hoàn hảo và sẽ có các vấn đề để cải thiện trong các phiên bản sau. Điều này do hạn chế về 'quỹ' transistor, buộc các kỹ sư phải cân nhắc đánh đổi. Dù sao, so với Lion Cove chỉ có 6 ALU INT, Zen 5 vẫn được xem là ngang bằng.
Xử lý số thực
Trong khi các phép toán số nguyên thường xuyên được sử dụng trong cuộc sống hàng ngày, các phép toán số thực lại xử lý những tác vụ nặng nề hơn như render, giải mã/mã hóa video, chơi game 3D, và tính toán AI. Do đó, FPU là một thành phần tiêu tốn nhiều transistor, chỉ đứng sau Cache (vì phần lớn transistor hiện nay được dùng cho bộ nhớ). Trên Zen 5, FPU được đầu tư đáng kể, phản ánh tầm nhìn của Lisa Su rằng CPU vẫn là trung tâm để cạnh tranh với Intel và NVIDIA trên lĩnh vực server/HPC (siêu máy tính).

FPU trên Zen 5 với khả năng xử lý AVX-512
Điều này cũng lý giải tại sao các thế hệ chip Intel dành cho người dùng phổ thông (Core) gần đây đã loại bỏ các tập lệnh AVX-512 (mặc dù chúng vẫn có mặt trên dòng Xeon cho server). Lisa Su dường như có quan điểm khác về việc này...
Back-end
Khi một nhà máy mở rộng sản xuất và thêm nhiều dây chuyền làm việc, kho chứa hàng cũng phải được mở rộng tương ứng. Điểm thay đổi lớn nhất ở Back-end Zen 5 là L1 Data Cache, vì đây là nơi tiếp nhận 'hàng hóa' từ cả INT và FPU. Mặc dù dung lượng L1D Zen 5 chỉ tăng nhẹ từ 32 KB lên 48 KB so với Zen 4, số liên kết nhớ (associativity) đã được nâng từ 8-way lên 12-way. Số liên kết này thể hiện khả năng 'giao hàng' của bộ nhớ với các bộ phận khác. Ví dụ, nhiều cao tốc liên kết giữa các thành phố giúp hàng hóa lưu thông dễ dàng hơn. AMD cho biết L1D Zen 5 có độ trễ 4 chu kỳ, điều này rất ấn tượng vì L0 của Lion Cove cũng có độ trễ tương tự và dung lượng tương đương. Thường thì AMD không bằng Intel về tốc độ cache.

L1 và L2 Cache được nâng cấp mạnh về khả năng liên kết nhớ
Khả năng nhập/chứa dữ liệu của Zen 5 cũng cao hơn so với Zen 4, từ 3/1 lên 4/2 ống lệnh. Bộ TLB hỗ trợ L1/L2 đã tăng từ 72/3072 (Zen 4) lên 96/4096 entry (Zen 5). Đặc biệt, nếu toán tử là 512b thì năng lực nhập/chứa giảm còn 2/1 lệnh/chu kỳ. Hơn nữa, 4 ống lệnh nạp INT có thể được gộp lại thành 2 ống FP khi cần. Dung lượng L2 Cache (chứa dữ liệu và tập lệnh) vẫn giữ nguyên ở 1 MB, nhưng độ liên kết đã tăng lên 16-way (gấp đôi so với 8-way trên Zen 4), cho phép đạt băng thông 64b/chu kỳ. Dữ liệu từ L1I hoặc L1D có thể được sao chép sang L2 với tốc độ 64b/chu kỳ.
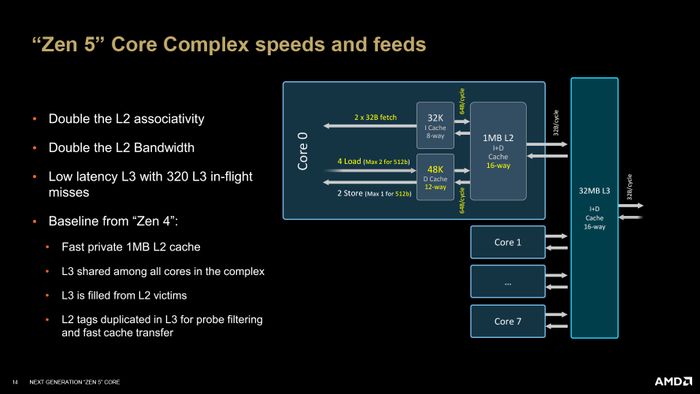
Mô hình trao đổi dữ liệu giữa các Cache của Zen 5
Tuy nhiên, khi sao chép từ L2 Cache sang L3 Cache (được chia sẻ giữa 8 nhân Zen 5), băng thông giảm xuống còn 32b/chu kỳ. Từ L3 Cache sang các bộ phận khác cũng là 32b/chu kỳ. L3 Cache có dung lượng 32 MB (trung bình 4 MB/nhân) và liên kết 16-way. Với cấu trúc này, chúng ta có một die CCD Zen 5 cơ bản, bao gồm 8 nhân Zen 5, L3 Cache 32 MB, SMU quản lý toàn bộ khối CCD và bộ liên kết Infinity Fabric để kết nối với các chiplet khác (I/O die, CCD, GDC). Trừ những trường hợp monolithic như Strix Point, các sản phẩm Ryzen/EPYC khác của AMD sẽ dựa trên việc ghép các die CCD này với các die CCD và I/O khác. Trong đó, nhân Zen 5/5c là 'linh hồn' của tất cả.
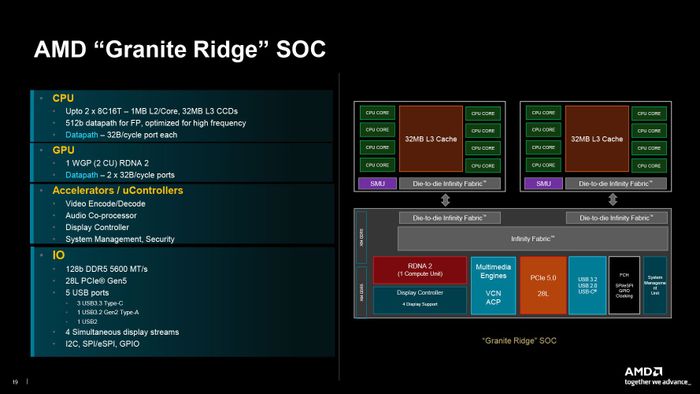
Hình dáng cơ bản của một chip Ryzen Zen 5 cho desktop
Những đánh giá sơ bộ và kết luận cuối cùng
Chúng ta đã khám phá cơ bản về kiến trúc Zen 5 của AMD. Đây là một trong những cải tiến quan trọng nhất của AMD kể từ thế hệ Zen 1 và Bulldozer. Trước sự thay đổi không ngừng của thị trường công nghệ, Zen 5 không chỉ phải cạnh tranh với Lion Cove của Intel mà còn đối đầu với Snapdragon của Qualcomm, và có thể cả MediaTek, Samsung, Huawei. Hiện tại, các đánh giá sơ bộ về Zen 5 đã được công bố, bao gồm cả trên Windows và Linux. (Lưu ý rằng những kết quả này được thực hiện trước khi Windows 11 có bản cập nhật mới.)
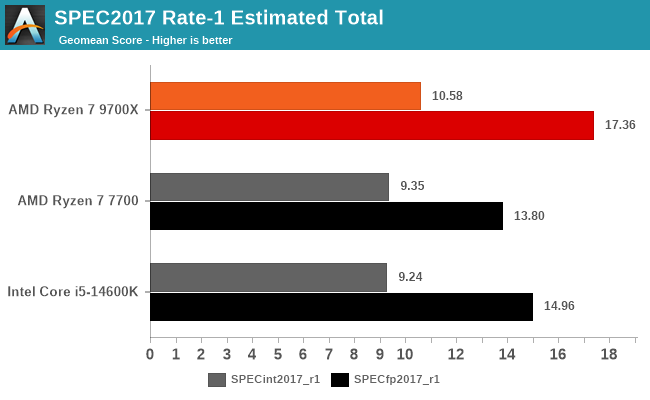
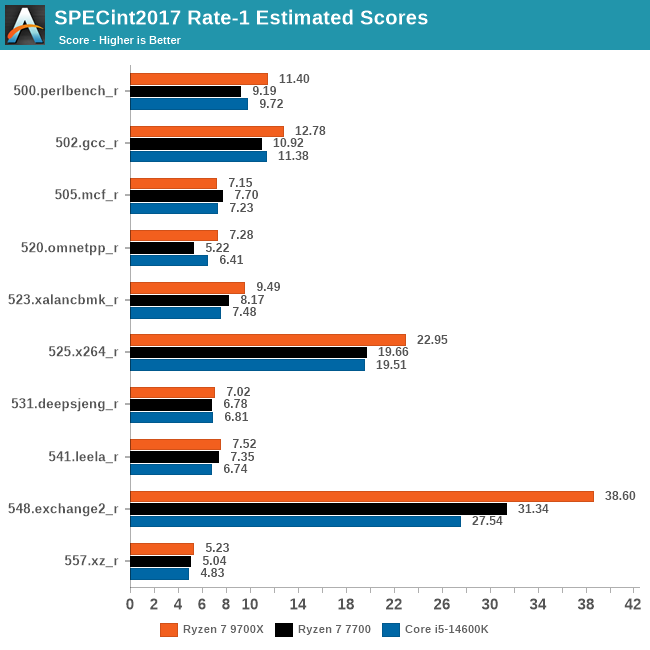
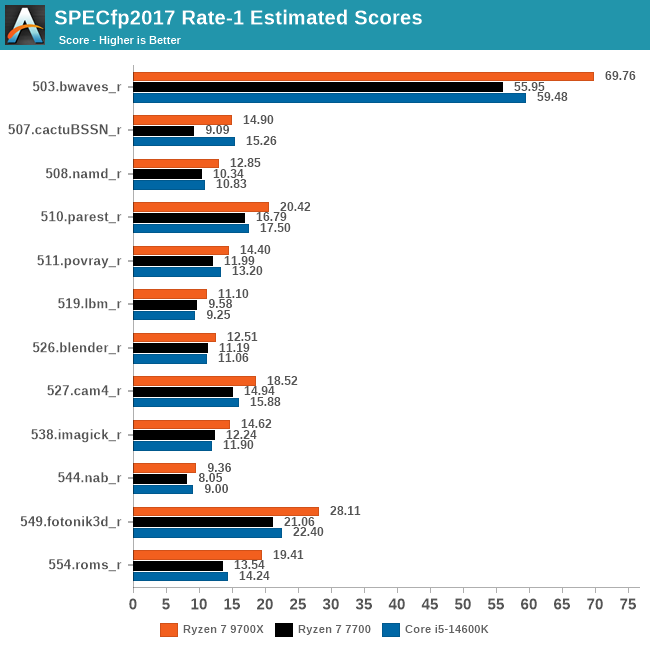
So sánh hiệu suất đơn luồng giữa Zen 4, Zen 5 và Raptor Lake
Thực tế, AMD đã công bố rằng IPC của Zen 5 cao hơn 16% so với Zen 4. Mặc dù sự khác biệt về decoder nhìn có vẻ không lớn (4-wide so với 8-wide), nhưng điều này không phản ánh toàn bộ câu chuyện. Zen 4 đã đạt đến đỉnh cao của 4-wide và mang lại hiệu suất vượt trội so với Zen 1, trong khi Zen 5 mới bắt đầu khai thác 8-wide. Vì vậy, sự khác biệt giữa Zen 4 và Zen 5 là hợp lý. Zen 6 và các thế hệ tiếp theo chắc chắn sẽ tiếp tục cải thiện IPC, nhưng đó là câu chuyện của tương lai.
Khi so sánh với Intel, đặc biệt là về hiệu suất đơn luồng, các vi xử lý Raptor Lake (thế hệ 13/14) với cấu trúc 6-wide decoder cho thấy chúng thua kém Zen 5. Tuy nhiên, khi thực hiện benchmark đa luồng với sự kết hợp của cả P-core và E-core, sự khác biệt có thể không rõ ràng.
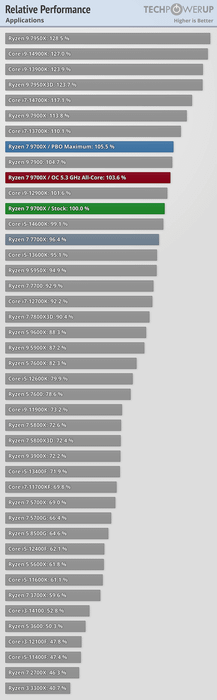

Tổng quan hiệu suất của Zen 5 trên Windows
Một điểm đáng chú ý là Zen 5 có vẻ hoạt động hiệu quả hơn trên hệ điều hành Linux. Theo báo cáo từ Phoronix, các chip Zen 5 6 nhân (9600X) và 8 nhân (9700X) của AMD chỉ thua kém một chút so với các chip desktop đắt nhất hiện nay của Intel như 13900K và 14900K (24 nhân với 8 nhân P)! Thậm chí, chúng còn cạnh tranh mạnh mẽ với các dòng Ryzen Zen 4. Một số trang web cho rằng do giới hạn TDP 65W, các chip Ryzen Zen 5 bị hạn chế khả năng turbo boost khi chạy đa luồng. Tuy nhiên, khi kích hoạt PBO, hiệu suất tăng vọt, tương tự như việc mở khóa ECU trong các cuộc đua.
Dĩ nhiên, khi turbo boost, chip sẽ tiêu tốn nhiều điện năng hơn. Tuy nhiên, nhờ được sản xuất trên tiến trình TSMC N4P, Ryzen Zen 5 vẫn tiết kiệm điện hơn các vi xử lý Core 13/14 của Intel. Điều khiến tôi tò mò là Arrow Lake được sản xuất bởi TSMC sẽ tiêu tốn điện như thế nào? Có vẻ như cuộc chiến PC 2024 còn nhiều điều thú vị để chờ đợi.
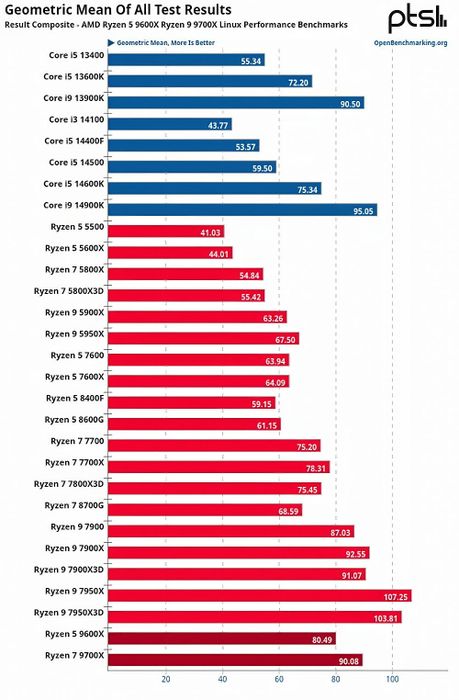
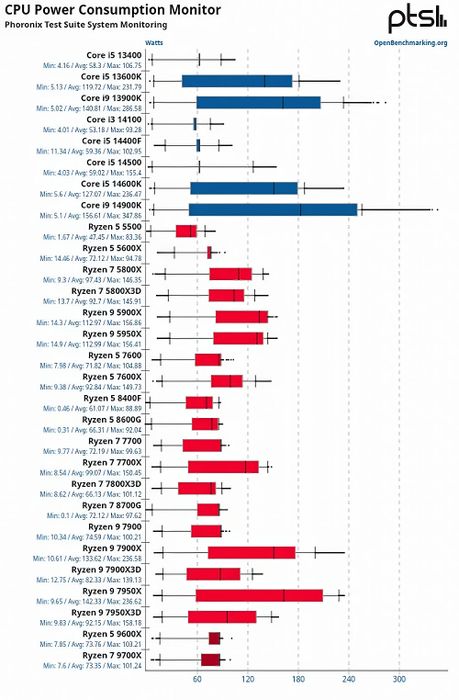
Tổng quan hiệu suất của Zen 5 trên Linux
Tóm lại, Zen 5 chứng tỏ AMD đang đi đúng hướng. Kiến trúc mới mạnh mẽ hơn, khai thác hiệu quả hơn các công nghệ quan trọng như AVX-512 và AI, và còn nhiều tiềm năng để cải tiến trong tương lai. Đây chắc chắn là một bước tiến vững chắc cho các sản phẩm sắp tới của AMD.