
 Đội ngũ Intel đã cải tiến và sáng tạo như thế nào đối với các nhân Performance và Efficient trong dòng vi xử lý Lunar Lake (LNL) để tạo ra thế hệ mới?
Đội ngũ Intel đã cải tiến và sáng tạo như thế nào đối với các nhân Performance và Efficient trong dòng vi xử lý Lunar Lake (LNL) để tạo ra thế hệ mới?P-core Lion Cove - Sáng tạo hoặc không gì cả
Kể từ Alder Lake, Intel đã áp dụng kiến trúc hybrid tương tự như big.LITTLE của ARM. Lunar Lake (LNL) tiếp tục xu hướng này với hai loại nhân x86: P-core Lion Cove và E-core Skymont. Trong đó, Lion Cove là trung tâm sức mạnh của toàn bộ con chip, tương tự như Zen 5 của AMD.

Front-end
Front-end là phần đầu tiên trong kiến trúc chip, nơi tiếp nhận các yêu cầu từ hệ điều hành. Trên Lion Cove, khu vực này đã được mở rộng đáng kể. Bộ dự đoán rẽ nhánh (BPU) – thiết bị dự đoán các tập lệnh sẽ được sử dụng trong các chu kỳ sau – đã được mở rộng gấp 8 lần so với thế hệ trước! BPU đóng vai trò giống như một thư ký, hỗ trợ bộ giải mã (decoder) phân phối công việc cho các thành phần thực thi. Sự mở rộng này cho thấy Intel đang cố gắng tối ưu hóa số lượng tập lệnh có thể xử lý.

Để hỗ trợ thêm cho bộ giải mã, các µQueue và µCache được sử dụng. Trên các vi xử lý hiện đại, các lệnh không được xử lý ngay lập tức mà được chia thành các vi lệnh (micro-ops) để đơn giản hóa quá trình thực thi sau đó. Đây cũng là điểm mà ranh giới giữa CISC và RISC trở nên mờ nhạt - sự khác biệt chủ yếu chỉ nằm ở phần front-end, nơi các lệnh có độ dài khác nhau, còn khi chuyển thành vi lệnh thì không còn sự khác biệt đáng kể. µCache của Lion Cove được mở rộng lên 12-wide, tăng 1.5 lần so với 8-wide của Redwood Cove. Kích thước µQueue cũng được gia tăng, tuy nhiên Intel không công bố cụ thể con số chính xác.
Máy Thực Thi Out-of-order (OoO)
Lion Cove mang đến một kiến trúc hoàn toàn mới, và khu vực OoO thể hiện rõ điều đó. Thành phần Retire đã được tách biệt hoàn toàn khỏi nhóm Allocate/Rename/Ellimation/Zero Idiom. Lý do chính là vì Retire cần phải mở rộng kích thước lên đến 12-wide. Nhóm Allocate cũng được mở rộng lên 8-wide, tương đương với kích thước của bộ giải mã. Đặc biệt, thanh ghi Scheduler giờ đây được phân chia rõ ràng thành Integer và Vector (floating-point), cho thấy sự chuyên biệt hóa trong vai trò của chúng.


Số lượng cửa sổ tập lệnh đã được nâng từ 512 lên 576, và số cổng xử lý cũng tăng từ 12 lên 18. Trong đó, 4 cổng được dành cho FPU (Vector), 6 cổng cho INT, và 8 cổng phục vụ cho việc phân loại xử lý địa chỉ dữ liệu (AGU).
Thực Thi
Lion Cove có sự khác biệt rõ rệt so với các kiến trúc trước đó khi tách riêng FPU khỏi INT. Trước đây, FPU và INT cùng chia sẻ các cổng để tiếp nhận công việc từ front-end/OoO, nhưng giờ đây FPU đã được tách biệt hoàn toàn. Theo quan điểm của mình, có thể Pat Gelsinger đang hướng Intel trở lại thị trường siêu máy tính (HPC), nơi mà AMD đang chiếm ưu thế. Pat Gelsinger cũng là một trong những kỹ sư kỳ cựu đã tham gia vào dự án Itanium, một trong những dự án đầy tham vọng của Intel.


Pat không chỉ đơn thuần tách riêng FPU và INT, mà còn cải thiện khả năng xử lý của từng phần. So với Redwood Cove, các thành phần trong cụm INT của Lion Cove đều được nâng cấp thêm một đơn vị (6 ALU, 3 JUMP, 3 SHIFT), trong khi MUL tăng gấp ba lần. FPU của Lion Cove cũng được tăng cường với 4 ALU (tăng từ 3) và 2 FP Divider (tăng từ 1). Tổng thể, khả năng xử lý của Lion Cove vượt trội hơn so với Redwood Cove và mạnh mẽ hơn nhiều so với Cypress Cove (hiện đang được sử dụng trên Core đời 14).
Back-end
Các cải tiến ở trên sẽ không có giá trị nếu Lion Cove không có sự nâng cấp tương ứng về bộ nhớ. Nếu xét theo ví dụ nhà máy, front-end giống như ban giám đốc gửi công việc xuống, OoO là phòng quản lý sản xuất, và execution là các dây chuyền sản xuất. Thì back-end chính là bộ phận lưu kho (kho nội bộ xưởng - kho tổng nằm ngoài hay DRAM). Khi nhà máy mở rộng sản xuất, kho cũng phải được mở rộng tương ứng, nếu không hàng hóa sản xuất ra sẽ bị ùn tắc, dẫn đến giảm sản lượng.


Trên Lion Cove, một điểm đáng chú ý là sự xuất hiện của L0 Cache. Về cơ bản, nó tương đương với L1 Cache trên Redwood Cove (48 KB), nhưng có độ trễ giảm từ 5 xuống 4 chu kỳ. Lion Cove vẫn sở hữu L1 Cache nhưng với dung lượng lớn hơn (192 KB) và độ trễ cao hơn (9 chu kỳ). L2 Cache có độ trễ tăng nhẹ từ 16 lên 17 chu kỳ, nhưng dung lượng lại được mở rộng đáng kể lên đến 2.5/3 MB (3 MB có thể là phiên bản dành cho máy chủ).
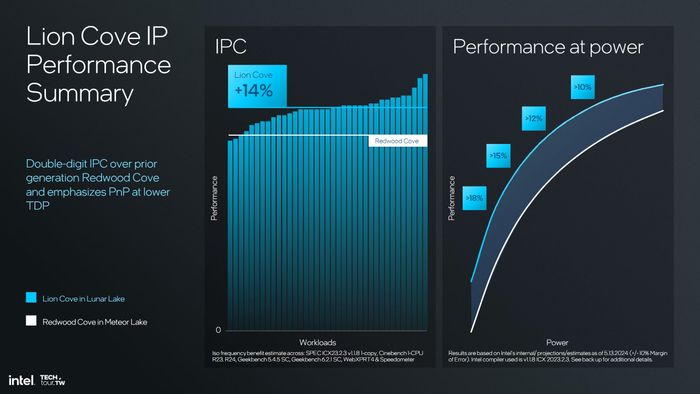
Tổng quan, phần back-end của Lion Cove được thiết kế rộng rãi hơn rất nhiều, nhằm chứa đựng nhiều dữ liệu hơn so với trước. Intel cho biết rằng, về tổng thể, Lion Cove có mức IPC cao hơn 14% so với Redwood Cove.
Bỏ Hyper-Threading để tiết kiệm không gian silicon?
Nếu bạn là người quan tâm đến công nghệ PC, chắc hẳn bạn đã quen thuộc với Hyper-Threading (HTT) hay SMT (tên gọi chung trong ngành). Đây là một tính năng mà Intel rất tự hào và đã quảng bá trong suốt hơn 20 năm. SMT được Intel ca ngợi đến mức đã từng có những cuộc tranh luận rằng chip AMD 'kém' hơn vì không có SMT (trong các thế hệ Zen trước). Nhưng điều đáng lưu ý là các chip M của Apple hay Snapdragon của Qualcomm, dù không có SMT, vẫn hoạt động mạnh mẽ. Do đó, việc có SMT hay không phụ thuộc vào mục tiêu thiết kế chip, chứ không phải là yếu tố quyết định sức mạnh của nó.
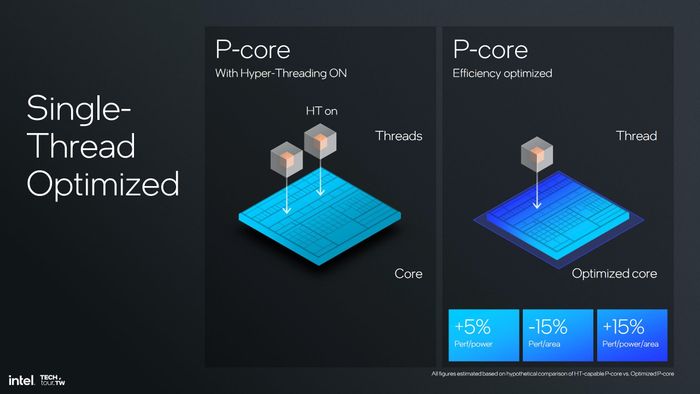
Với Lion Cove, Intel lần đầu tiên sau 23 năm từ bỏ hỗ trợ SMT trên sản phẩm của mình. Theo công ty, việc không hỗ trợ SMT giúp tiết kiệm 10% diện tích cho mỗi nhân xử lý tối ưu (1 luồng) mà vẫn đạt hiệu suất tương đương với nhân hỗ trợ SMT (chỉ xử lý 1 luồng). Nếu xét ở mức tiêu thụ điện tương đương, hiệu suất sẽ cao hơn 15%. Đối với nhân xử lý 2 luồng, nhân tối ưu (1 luồng) chỉ giảm 15% hiệu suất trên cùng diện tích, nhưng hiệu suất lại cao hơn 5% so với nhân hỗ trợ 2 luồng cùng mức tiêu thụ điện. Vì vậy, Intel (hoặc Pat Gelsinger) quyết định không cần hỗ trợ SMT trên Lion Cove.
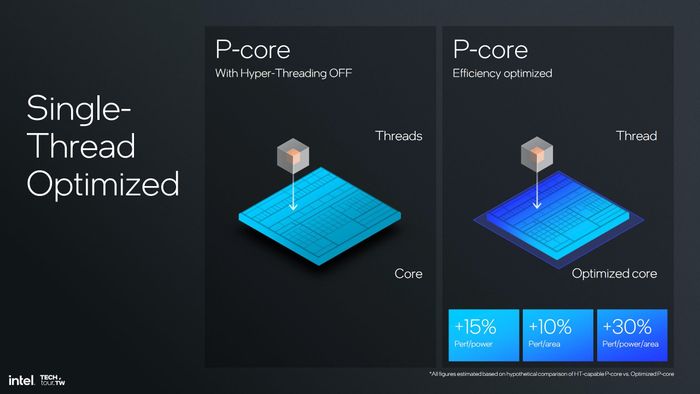
Một điều hài hước là vào thời điểm AMD (trước khi Lisa Su trở thành CEO) thiết kế chip Bulldozer, các kỹ sư của AMD cũng đưa ra lý do tương tự như Intel hiện tại - họ có thể hỗ trợ SMT nếu muốn, nhưng chỉ cần thêm 15% không gian silicon để tạo ra một nhân 'thực' thì tại sao phải sử dụng nhân 'ảo'? Vì vậy, Bulldozer và các sản phẩm dựa trên nó vẫn trung thành với triết lý CMP thay vì SMT. Chỉ khi Lisa Su trở về, AMD mới chuyển sang sử dụng SMT. Tôi sẽ có một bài phân tích sâu hơn về lợi ích của SMT sau này.
Theo quan điểm của tôi, việc Intel bỏ SMT trên Lion Cove có thể liên quan đến E-core Skymont, đặc biệt là ở cơ chế phân chia công việc mới của Thread Director (TDD).
E-Core Skymont - Có sức mạnh ngang ngửa Raptor Cove?
Trên thực tế, câu nói này có phần phóng đại, hay nói đúng hơn là còn thiếu điều kiện. Để E-core của LNL đạt hiệu suất ngang bằng với P-core của các thế hệ Core 13/14, yêu cầu là chúng phải được kết nối với L3 Cache (LLC) hoặc Ringbus. Tuy nhiên, LLC và Ringbus là những tính năng hiện chỉ được áp dụng cho P-core, và các cụm E-core (4 nhân) hiện tại không được trang bị những tính năng 'đắt đỏ' này (vì cache tiêu tốn nhiều không gian silicon). Skymont trên LNL hiện không có LLC.

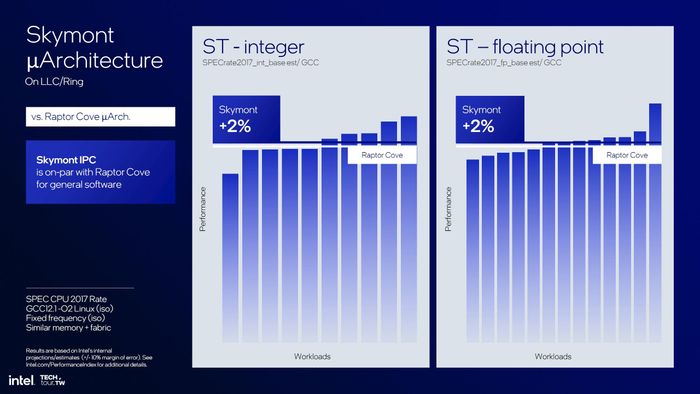
Thông tin này từ Intel khá thú vị. Theo ý kiến cá nhân, Intel có thể đưa Skymont vào các dòng chip server (series Forest) và trang bị LLC cho chúng. Còn đối với desktop, nếu E-core có thể chia sẻ LLC với P-core thì sẽ tạo ra nhiều điều hấp dẫn... Nhưng hiện tại, chúng ta hãy trở lại với LNL.
Front-end
Nếu bạn đã xem phân tích về E-core Crestmont của MTL, bạn sẽ thấy Skymont là phiên bản mở rộng của Crestmont! Trong khi Crestmont có 2 cụm decoder (2x 3-wide) thì Skymont có 3 cụm (3x 3-wide). Dung lượng bộ queue và fetch của Skymont cũng tăng 1.5 lần so với Crestmont (từ 64 lên 96 đơn vị).


Nhưng do chỉ là E-core, các thành phần dự đoán rẽ nhánh và lên tập lệnh của Skymont vẫn khá đơn giản. Chúng chỉ lớn hơn Crestmont vì có nhiều decoder hơn.
Out-of-order (OoO) engine
Bạn có thể nghĩ rằng với decoder 9-wide thì OoO cũng phải 9-wide cho tương xứng? Không phải vậy. Nếu là P-core thì đúng, nhưng đây không phải là P-core. Intel chỉ mở rộng khu vực này từ 6-wide lên 8-wide và chỉ có hai chức năng Allocate/Rename, không đầy đủ như Lion Cove.


Một 'nét truyền thống' của E-core là không có thanh ghi Scheduler. Thay vào đó, các vi lệnh sau khi được decode sẽ đẩy thẳng xuống các cổng để vào các ống lệnh INT hay FPU. OoO của Skymont chỉ cải thiện ở chỗ tăng số lượng cửa sổ tập lệnh từ 256 lên 416, cùng với việc mở rộng kích thước cho các thanh ghi khác.
Execution
Dù cấu trúc đơn giản, nhưng với số lượng decoder tăng lên, khu vực xử lý của Skymont cũng phải mở rộng hơn Crestmont. Giống như các thế hệ E-core trước, Skymont có nhiều cổng để nhận yêu cầu xử lý từ front-end/OoO. Khu vực INT/MEM có tới 26 cổng, trong khi FPU có 6 cổng. Dù số cổng nhiều, nhưng số ống lệnh lại ít. Khu vực INT có 4 ống, MEM có 2 ống, JMP và STD mỗi bên có 1 ống. FPU có 5 ống lệnh.
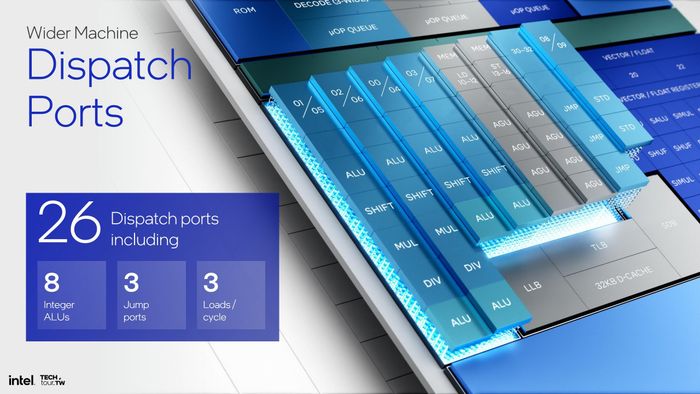

Do số lượng ống lệnh tăng lên, các đơn vị tính toán của Skymont cũng được tăng cường. So với Crestmont, số lượng ALU INT tăng gấp đôi từ 4 lên 8. Bên FPU, Skymont có khả năng xử lý các vector kích thước 4x 128-bit, cải thiện khả năng AI. Các đơn vị FMUL, FADD, FMA cũng giảm độ trễ, giúp tính toán nhanh hơn.
Back-end
Khi Front-end và Execution được mở rộng, Back-end cũng phải mở rộng theo. Skymont có tới 7 AGU, thay vì 4 như thế hệ trước, cho phép thực hiện 3 lượt Load 128-bit và 4 lượt Store cùng lúc. L2 TLB tăng 33%, từ 3096 lên 4192 entry.


Tuy nhiên, dung lượng cache vẫn giữ nguyên như Crestmont, cho thấy E-core vẫn chưa được ưu tiên cao. Có thể hình dung như một nhà máy có nhiều công nhân hơn để vận chuyển hàng hóa, nhưng diện tích kho chứa pallet hàng thì vẫn không đổi.
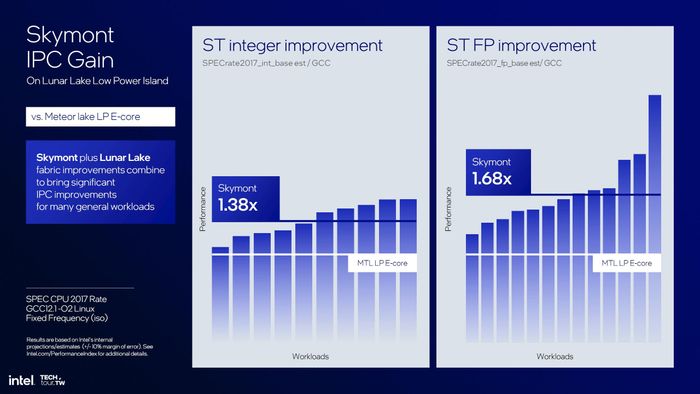
Tóm lại, Intel cho biết Skymont có hệ số IPC INT cao hơn Crestmont 38%, còn FPU là 68%! Rất ấn tượng! Nếu được trang bị LLC, IPC Skymont sẽ ngang ngửa với Raptor Cove. Tuy nhiên, điều này chưa áp dụng cho LNL, nên chúng ta chỉ xem con số so sánh với Crestmont như Intel đã quảng cáo...
Phân tích kiến trúc vi xử lý Intel Lunar Lake - Phần 3: Thread Director mới và NPU4