

Trước đây, Llama chủ yếu là mô hình xử lý ngôn ngữ (text). Để mở rộng khả năng xử lý hình ảnh, Meta đã điều chỉnh cấu trúc mô hình và thêm các thành phần mới:
- Thêm bộ mã hóa hình ảnh: Một bộ mã hóa hình ảnh được tích hợp để chuyển đổi hình ảnh thành định dạng mà mô hình ngôn ngữ có thể hiểu.
- Thêm bộ điều hợp (adapter): Bộ điều hợp được thiết lập để kết nối bộ mã hóa hình ảnh với mô hình ngôn ngữ hiện có. Nó sử dụng các lớp chú ý chéo (cross-attention) để kết hợp thông tin từ hình ảnh và văn bản.
- Huấn luyện bộ điều hợp: Bộ điều hợp được huấn luyện trên các cặp dữ liệu (hình ảnh, văn bản) để học cách liên kết chính xác thông tin giữa hai loại dữ liệu.
- Huấn luyện bổ sung: Mô hình được huấn luyện thêm trên nhiều tập dữ liệu, bao gồm cả dữ liệu nhiễu và dữ liệu chất lượng cao, nhằm cải thiện khả năng hiểu và suy luận về hình ảnh.
- Tối ưu hóa sau huấn luyện: Sau quá trình huấn luyện, mô hình được tối ưu hóa qua nhiều kỹ thuật khác nhau, bao gồm việc sử dụng dữ liệu tổng hợp và mô hình phần thưởng để nâng cao chất lượng mô hình.
So sánh hiệu năng của Llama 3.2 với các mô hình AI khác
Meta đã công bố bảng benchmark thể hiện hiệu suất và khả năng suy luận của Llama 3.2 khi so sánh với các mô hình AI khác từ Anthropic, OpenAI, Google và Microsoft.
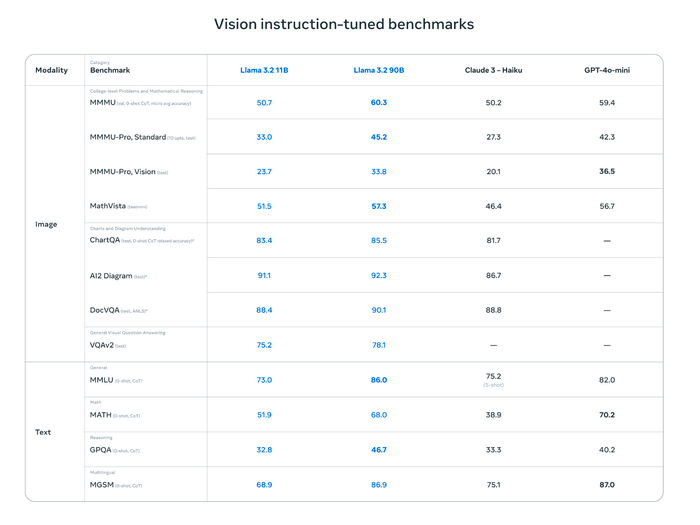
Llama 3.2 11B và 90B đặc biệt nổi bật trong các bài kiểm tra về khả năng hiểu biểu đồ và sơ đồ (ChartQA, AI2 Diagram, DocVQA) khi so với Claude 3-Haiku và GPT--mini. Llama 3.2 90B cũng đạt kết quả tốt trong các tác vụ văn bản. Nhìn chung, Llama 3.2 đánh dấu một bước tiến lớn của Meta trong khả năng xử lý hình ảnh và văn bản, đặc biệt là khi so với GPT--mini.
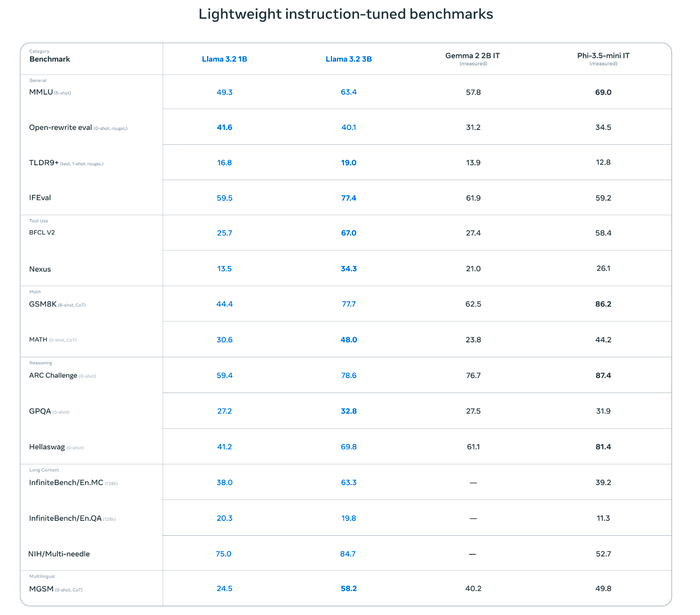
Đối với Llama 3.2 1B và 3B, mẫu 3B thể hiện hiệu suất ấn tượng trong hầu hết các tác vụ, đặc biệt là các tác vụ phức tạp như MMLU, IFEval, GSM8K và Hellaswag khi so với Gemma 2B IT của Google. Mặc dù Llama 3.2 1B có kích thước nhỏ, nhưng điểm số của nó cũng khá khả quan, hứa hẹn sẽ hoạt động hiệu quả trên các thiết bị có tài nguyên hạn chế. Tóm lại, Llama 3.2 3B là một mô hình nhỏ gọn nhưng tiềm năng lớn, có khả năng thực hiện tốt trong nhiều tác vụ xử lý ngôn ngữ khác nhau.