
Tất cả những điều bạn cần biết về học tăng cường không mô hình và có mô hình
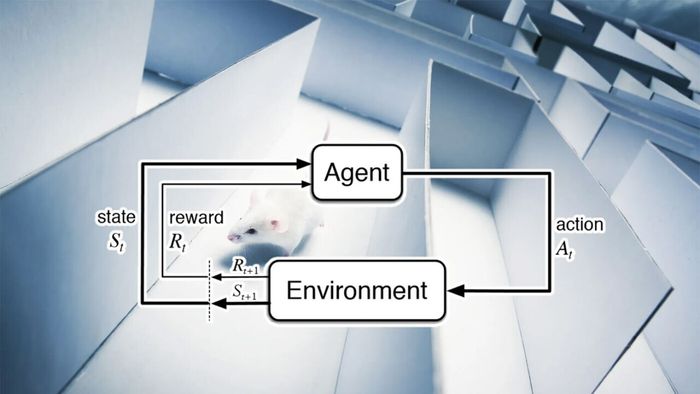
Học tăng cường là một trong những nhánh hứng thú của trí tuệ nhân tạo. Nó đóng một vai trò quan trọng trong các hệ thống trí tuệ nhân tạo chơi game, robot hiện đại, hệ thống thiết kế vi mạch, và các ứng dụng khác.
Có nhiều loại thuật toán học tăng cường khác nhau, nhưng hai danh mục chính là "có mô hình" và "không mô hình" RL. Cả hai đều được lấy cảm hứng từ sự hiểu biết của chúng ta về quá trình học trong người và động vật.
Hầu hết mọi cuốn sách về học tăng cường đều chứa một chương giải thích sự khác biệt giữa học tăng cường không mô hình và có mô hình. Nhưng hiếm khi có sự thảo luận về các tiền lệ sinh học và tiến hóa trong những cuốn sách về thuật toán học tăng cường cho máy tính.
Tôi đã tìm thấy một giải thích rất thú vị về học tăng cường không mô hình và có mô hình trong Sự Ra Đời của Trí Tuệ, một cuốn sách khám phá sự tiến hóa của trí tuệ. Trong một cuộc trò chuyện với TechTalks, Daeyeol Lee, nhà nghiên cứu Não và tác giả của Sự Ra Đời của Trí Tuệ, thảo luận về các chế độ khác nhau của học tăng cường ở con người và động vật, trí tuệ nhân tạo và tự nhiên, cũng như hướng nghiên cứu trong tương lai.
Nguồn gốc của học tăng cường không mô hình
Hội nghị TNW 2024 - Mời tất cả các Startup tham gia vào ngày 20-21 tháng 6
Trình bày Startup của bạn trước các nhà đầu tư, người làm thay đổi và khách hàng tiềm năng với các gói Startup được chọn lọc của chúng tôi.
Nhà tâm lý học người Mỹ Edward Thorndike đề xuất "luật tác động," trở thành cơ sở cho học tăng cường không mô hình

Vào cuối thế kỷ XIX, nhà tâm lý học Edward Thorndike đề xuất "luật tác động", nói rằng các hành động có hiệu ứng tích cực trong một tình huống cụ thể trở nên có khả năng xảy ra lại trong tình huống đó, và các phản ứng tạo ra hiệu ứng tiêu cực trở nên ít có khả năng xảy ra trong tương lai.
Thorndike khám phá luật tác động bằng một thử nghiệm trong đó ông đặt một con mèo trong một hộp puzzle và đo thời gian mèo mất để thoát khỏi đó. Để thoát khỏi, con mèo phải điều khiển một loạt các thiết bị như dây và cần cù. Thorndike quan sát rằng khi con mèo tương tác với hộp puzzle, nó học được những phản ứng hành vi có thể giúp nó thoát khỏi. Theo thời gian, con mèo trở nên nhanh chóng hơn trong việc thoát khỏi hộp. Thorndike kết luận rằng con mèo học từ những phần thưởng và trừng phạt mà hành động của nó tạo ra.
Luật tác động sau đó mở đường cho hành vi chủ nghĩa, một nhánh của tâm lý học cố gắng giải thích hành vi của con người và động vật dưới hình thức kích thích và phản ứng.
Luật tác động cũng là cơ sở cho học tăng cường không mô hình. Trong học tăng cường không mô hình, một đại lý cảm nhận thế giới, thực hiện một hành động và đo lường phần thưởng. Đại lý thường bắt đầu bằng cách thực hiện các hành động ngẫu nhiên và dần dần lặp lại những hành động liên quan đến nhiều phần thưởng hơn.
“Đơn giản là bạn nhìn vào trạng thái của thế giới, một bức tranh về cái thế giới trông như thế nào, và sau đó bạn thực hiện một hành động. Sau đó, bạn tăng hoặc giảm khả năng thực hiện cùng một hành động trong tình huống đã cho tùy thuộc vào kết quả của nó,” Lee nói. “Đó chính là những gì mà học tăng cường không mô hình là. Điều đơn giản nhất bạn có thể tưởng tượng được.”
Trong học tăng cường không mô hình, không có kiến thức trực tiếp hoặc mô hình về thế giới. Đại lý RL phải trực tiếp trải nghiệm mọi kết quả của mỗi hành động thông qua thử nghiệm và lỗi.
Học tăng cường có mô hình
Nhà tâm lý học người Mỹ Edward C. Tolman đề xuất ý tưởng của “học tập tiềm ẩn,” trở thành cơ sở cho học tăng cường có mô hình

Luật tác động của Thorndike phổ biến cho đến những năm 1930, khi Edward Tolman, một nhà tâm lý học khác, phát hiện ra một thông điệp quan trọng trong quá trình khám phá cách chúng chuột có thể học cách điều hướng qua các hành lang. Trong các thí nghiệm của mình, Tolman nhận ra rằng động vật có thể học được điều về môi trường của chúng mà không cần sự hỗ trợ.
Ví dụ, khi một con chuột được thả tự do trong một hành lang, nó sẽ tự do khám phá các đường hầm và dần dần học cấu trúc của môi trường. Nếu con chuột cùng một sau này được giới thiệu lại vào môi trường giống như vậy và được cung cấp một tín hiệu hỗ trợ, như tìm thức ăn hoặc tìm kiếm lối thoát, nó có thể đạt được mục tiêu của mình nhanh hơn so với những con vật không có cơ hội khám phá mê cung. Tolman gọi điều này là “học tập tiềm ẩn.”
Học tập tiềm ẩn cho phép động vật và con người phát triển một biểu diễn tâm lý về thế giới của họ và mô phỏng các tình huống giả tưởng trong tâm trí để dự đoán kết quả. Điều này cũng là cơ sở của học tăng cường có mô hình.
“Trong học tăng cường có mô hình, bạn phát triển một mô hình về thế giới. Trong ngôn ngữ máy tính, đó là xác suất chuyển đổi, cách thế giới chuyển từ trạng thái này sang trạng thái khác tùy thuộc vào loại hành động bạn thực hiện,” Lee nói. “Khi bạn ở trong một tình huống cụ thể mà bạn đã học trước đó về mô hình của môi trường, bạn sẽ thực hiện một mô phỏng tâm lý. Bạn basically tìm kiếm qua mô hình bạn đã học trong não bạn và cố gắng xem loại kết quả nào sẽ xảy ra nếu bạn thực hiện một loạt hành động cụ thể. Và khi bạn tìm ra con đường các hành động sẽ đưa bạn đến mục tiêu bạn muốn, bạn sẽ bắt đầu thực hiện những hành động đó vật lý.”
Lợi ích chính của học tăng cường có mô hình là nó loại bỏ nhu cầu của đại lý phải trải qua thử nghiệm và lỗi trong môi trường của nó. Ví dụ, nếu bạn nghe về một tai nạn đã làm tắc nghẽn con đường bạn thường đi làm, học tăng cường có mô hình sẽ cho phép bạn thực hiện một mô phỏng tâm lý của các tuyến đường thay thế và thay đổi con đường của bạn. Với học tăng cường không mô hình, thông tin mới sẽ không hữu ích với bạn. Bạn sẽ tiếp tục như thông thường cho đến khi bạn đến tận hiện trường tai nạn, và sau đó bạn sẽ bắt đầu cập nhật hàm giá trị của mình và thực hiện khám phá các hành động khác.
Học tăng cường có mô hình đặc biệt thành công trong việc phát triển hệ thống AI có thể thành thạo các trò chơi trên bàn cờ như cờ vua và cờ Go, nơi môi trường là xác định.
Học tăng cường có mô hình so với học tăng cường không mô hình

Trong một số trường hợp, việc tạo ra một mô hình hợp lý về môi trường không khả thi hoặc quá khó khăn. Và học tăng cường có mô hình có thể tiêu tốn rất nhiều thời gian, điều này có thể làm rủi ro hoặc thậm chí gây chết người trong các tình huống cần phản ứng nhanh chóng.
“Tính toán, học tăng cường có mô hình phức tạp hơn nhiều. Bạn phải học được mô hình, thực hiện mô phỏng tâm lý và bạn phải tìm đường đi trong quá trình thần kinh của bạn và sau đó thực hiện hành động,” Lee nói.
Tuy nhiên, Lee bổ sung rằng học tăng cường có mô hình không nhất thiết phải phức tạp hơn học tăng cường không mô hình.
“Điều quyết định độ phức tạp của học tăng cường không mô hình là tất cả các kết hợp có thể của bộ kích thích và bộ hành động,” ông nói. “Khi bạn có nhiều trạng thái của thế giới hoặc biểu diễn cảm biến, các cặp mà bạn sẽ phải học giữa các trạng thái và hành động sẽ tăng lên. Do đó, mặc dù ý tưởng là đơn giản, nếu có nhiều trạng thái và những trạng thái đó được ánh xạ với các hành động khác nhau, bạn sẽ cần nhiều bộ nhớ.”
Ngược lại, trong học tăng cường có mô hình, độ phức tạp sẽ phụ thuộc vào mô hình bạn xây dựng. Nếu môi trường thực sự phức tạp nhưng có thể được mô hình hóa bằng một mô hình tương đối đơn giản có thể được học nhanh chóng, thì mô phỏng sẽ đơn giản và hiệu quả chi phí.
“Và nếu môi trường thường xuyên thay đổi, thay vì cố gắng học lại các cặp kích thích-hành động mỗi khi thế giới thay đổi, bạn có thể có một kết quả hiệu quả hơn nếu bạn sử dụng học tăng cường có mô hình,” Lee nói.
Nhiều chế độ học tập
 Daeyeol Lee, professor of neuroscience at Johns Hopkins School of Medicine
Daeyeol Lee, professor of neuroscience at Johns Hopkins School of MedicineVề cơ bản, cả học tăng cường có mô hình lẫn học tăng cường không mô hình đều không phải là một giải pháp hoàn hảo. Và mỗi khi bạn thấy một hệ thống học tăng cường đối mặt với một vấn đề phức tạp, có khả năng cao là nó đang sử dụng cả học tăng cường có mô hình và học tăng cường không mô hình—và có thể là nhiều hình thức học khác nữa.
Nghiên cứu trong lĩnh vực thần kinh cho thấy người và động vật có nhiều hình thức học, và não liên tục chuyển đổi giữa các chế độ này tùy thuộc vào sự chắc chắn mà nó có về chúng tại bất kỳ thời điểm nào.
“Nếu học tăng cường không mô hình đang hoạt động rất tốt và nó dự đoán chính xác thưởng mọi lúc, điều đó có nghĩa là có ít sự không chắc chắn với học tăng cường không mô hình và bạn sẽ sử dụng nó nhiều hơn,” Lee nói. “Ngược lại, nếu bạn có một mô hình thế giới thực sự chính xác và bạn có thể thực hiện mô phỏng tâm lý về điều gì sẽ xảy ra ở mọi thời điểm, thì bạn có khả năng sử dụng học tăng cường có mô hình.”
Trong những năm gần đây, đã có sự quan tâm ngày càng tăng về việc tạo ra hệ thống AI kết hợp nhiều chế độ học tăng cường. Nghiên cứu gần đây của các nhà khoa học tại Đại học California, San Diego cho thấy việc kết hợp học tăng cường có mô hình và không mô hình đạt được hiệu suất xuất sắc trong các nhiệm vụ kiểm soát.
“Nếu bạn nhìn vào một thuật toán phức tạp như AlphaGo, nó có các yếu tố của cả học tăng cường không mô hình và có mô hình,” Lee nói. “Nó học các giá trị trạng thái dựa trên cấu hình bảng cờ, và đó chủ yếu là học tăng cường không mô hình, vì bạn đang thử giá trị tùy thuộc vào nơi mà tất cả các đá đặt. Nhưng nó cũng thực hiện tìm kiếm tiến, đó là học tăng cường có mô hình.”
Nhưng mặc dù có những thành tựu đáng chú ý, tiến triển trong học tăng cường vẫn chậm chạp. Ngay khi các mô hình học tăng cường đối mặt với môi trường phức tạp và không dự đoán được, hiệu suất của chúng bắt đầu giảm sút. Ví dụ, việc tạo ra một hệ thống học tăng cường chơi Dota 2 tại cấp độ chuyên nghiệp yêu cầu hàng ngàn giờ đào tạo, một kỳ tích mà về mặt vật lý là không thể đối với con người. Những nhiệm vụ khác như thao tác tay robot cũng đòi hỏi lượng đào tạo và thử nghiệm lớn.
Một phần của lý do mà học tăng cường vẫn gặp khó khăn với hiệu suất là khoảng trống còn lại trong kiến thức của chúng ta về việc học ở con người và động vật. Và chúng ta có nhiều hơn chỉ là học tăng cường không mô hình và có mô hình, theo quan điểm của Lee.
“Tôi nghĩ rằng não bộ của chúng ta là một hỗn loạn của các thuật toán học tăng cường đã tiến hóa để xử lý nhiều tình huống khác nhau,” ông nói.
Ngoài việc liên tục chuyển đổi giữa các chế độ học tập này, não bộ còn quản lý để duy trì và cập nhật chúng liên tục, ngay cả khi chúng không tham gia tích cực vào quyết định.
“Khi bạn có nhiều thuật toán học tập, chúng trở nên vô dụng nếu bạn tắt một số trong số chúng. Ngay cả khi bạn phụ thuộc vào một thuật toán—chẳng hạn như học tăng cường không mô hình—các thuật toán khác phải tiếp tục chạy. Tôi vẫn phải cập nhật mô hình thế giới của mình thay vì giữ nó đóng băng vì nếu tôi không làm như vậy, vài giờ sau, khi tôi nhận ra rằng tôi cần chuyển sang học tăng cường có mô hình, nó sẽ lỗi thời,” Lee nói.
Một số công việc thú vị trong nghiên cứu AI cho thấy cách điều này có thể hoạt động. Một kỹ thuật gần đây lấy cảm hứng từ tư duy System 1 và System 2 của nhà tâm lý học Daniel Kahneman cho thấy việc duy trì các mô-đun học khác nhau và cập nhật chúng song song giúp cải thiện hiệu suất và độ chính xác của các hệ thống AI.
Một điều khác mà chúng ta vẫn phải tìm hiểu là cách áp dụng những đặc tính xuất hiện đúng trong các hệ thống AI của chúng ta để đảm bảo rằng chúng học những điều đúng một cách hiệu quả về chi phí. Hàng tỷ năm tiến hóa đã cung cấp cho con người và động vật những đặc tính xuất hiện cần thiết để học một cách hiệu quả và với ít dữ liệu nhất có thể.
“Thông tin mà chúng ta nhận được từ môi trường rất thưa thớt. Và sử dụng thông tin đó, chúng ta phải tổng quát hóa. Lý do là não bộ có những đặc tính xuất hiện và có những đặc tính có thể tổng quát hóa từ một tập hợp nhỏ ví dụ. Đó là sản phẩm của tiến hóa, và nhiều nhà thần kinh học đang quan tâm hơn vào điều này,” Lee nói.
Tuy nhiên, trong khi đặc tính xuất hiện có thể dễ hiểu đối với một nhiệm vụ nhận diện đối tượng, chúng trở nên phức tạp hơn nhiều đối với các vấn đề trừu tượng như xây dựng mối quan hệ xã hội.
“Ý tưởng về đặc tính xuất hiện khá phổ quát và áp dụng không chỉ cho nhận thức và nhận diện đối tượng mà còn cho mọi loại vấn đề mà một sinh linh thông minh phải đối mặt,” Lee nói. “Và tôi nghĩ rằng điều đó một cách nào đó là vuông góc so với sự phân biệt giữa học tăng cường có mô hình và không có mô hình vì nó liên quan đến cách xây dựng một mô hình hiệu quả của cấu trúc phức tạp dựa trên một số quan sát ít ỏi. Còn rất nhiều điều chúng ta cần hiểu.”