

 Neural Engine là một phần mềm chuyên xử lý trí tuệ nhân tạo trên các con chip của Apple. Trên chip của Samsung, Huawei, họ gọi là Neural Processing Unit, Qualcomm lại đặt tên là Qualcomm AI Engine và nhân xử lý Hexagon... Ngày nay, nhân xử lý AI được sử dụng rộng rãi trên nhiều thiết bị di động và thậm chí cả chip máy tính để tối ưu hóa cho các tác vụ trí tuệ nhân tạo như nhận diện khuôn mặt, nhận diện chữ viết, phân loại hình ảnh, tách chủ thể ra khỏi nền... Chúng giúp tăng hiệu suất và tiết kiệm năng lượng trong việc sử dụng hàng ngày.
Neural Engine là một phần mềm chuyên xử lý trí tuệ nhân tạo trên các con chip của Apple. Trên chip của Samsung, Huawei, họ gọi là Neural Processing Unit, Qualcomm lại đặt tên là Qualcomm AI Engine và nhân xử lý Hexagon... Ngày nay, nhân xử lý AI được sử dụng rộng rãi trên nhiều thiết bị di động và thậm chí cả chip máy tính để tối ưu hóa cho các tác vụ trí tuệ nhân tạo như nhận diện khuôn mặt, nhận diện chữ viết, phân loại hình ảnh, tách chủ thể ra khỏi nền... Chúng giúp tăng hiệu suất và tiết kiệm năng lượng trong việc sử dụng hàng ngày.Mạng nơ-ron hoạt động như thế nào?
Trước khi ta bàn luận về những khía cạnh kỹ thuật, hãy tìm hiểu xem AI cần những tính toán như thế nào. AI là một lĩnh vực rất rộng lớn, trong phần này chúng ta sẽ tập trung vào lĩnh vực máy học và đặc biệt là các giải pháp sử dụng mạng nơ-ron nhân tạo.
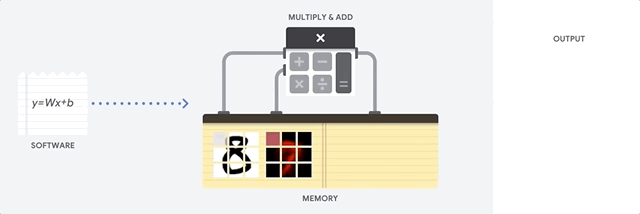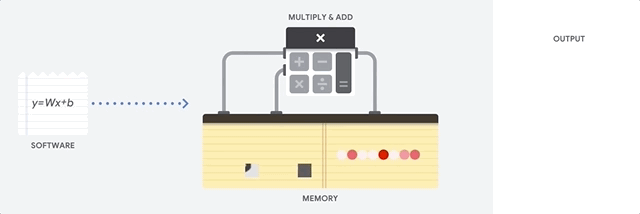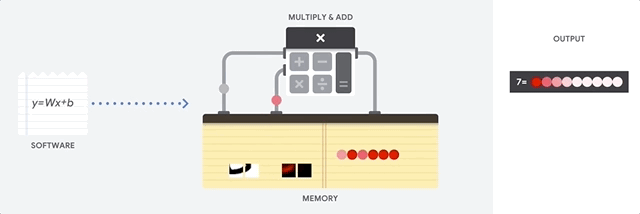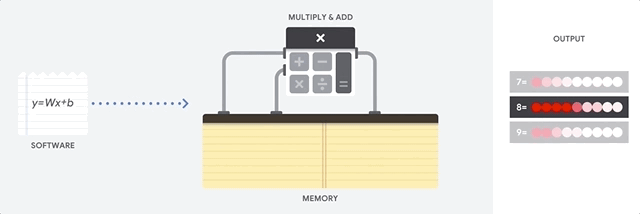 Nhìn vào video này, bạn sẽ thấy rằng hình ảnh của con số 8 được đưa vào một thuật toán nhận dạng, nó sẽ được so sánh với các mẫu của số 7, số 8, số 9 (và nhiều số khác) thông qua phép nhân và phép cộng vector. Kết quả cuối cùng cho thấy hình ảnh này phù hợp nhất với mẫu số 8, vì vậy máy dự đoán rằng nó là số 8.
Các nhiệm vụ AI liên quan đến xử lý ảnh, âm thanh, ngôn ngữ tự nhiên... thường đòi hỏi rất nhiều phép nhân và phép cộng như thế này. Thông thường, chúng ta tổ chức chúng thành các phép nhân ma trận (tích ma trận), có lẽ bạn đã nghe về nó khi học về giải tích trong các khóa học toán học cơ bản.
Nhìn vào video này, bạn sẽ thấy rằng hình ảnh của con số 8 được đưa vào một thuật toán nhận dạng, nó sẽ được so sánh với các mẫu của số 7, số 8, số 9 (và nhiều số khác) thông qua phép nhân và phép cộng vector. Kết quả cuối cùng cho thấy hình ảnh này phù hợp nhất với mẫu số 8, vì vậy máy dự đoán rằng nó là số 8.
Các nhiệm vụ AI liên quan đến xử lý ảnh, âm thanh, ngôn ngữ tự nhiên... thường đòi hỏi rất nhiều phép nhân và phép cộng như thế này. Thông thường, chúng ta tổ chức chúng thành các phép nhân ma trận (tích ma trận), có lẽ bạn đã nghe về nó khi học về giải tích trong các khóa học toán học cơ bản. Vấn đề cốt lõi với máy tính là làm sao thực hiện phép nhân ma trận lớn trong thời gian ngắn nhất mà vẫn tiết kiệm năng lượng (để tránh hết pin hoặc phải trả nhiều tiền điện cho máy chủ).
Vấn đề cốt lõi với máy tính là làm sao thực hiện phép nhân ma trận lớn trong thời gian ngắn nhất mà vẫn tiết kiệm năng lượng (để tránh hết pin hoặc phải trả nhiều tiền điện cho máy chủ).CPU làm việc như thế nào?
CPU là một bộ xử lý đa dụng, tổ chức theo kiến trúc như dưới đây (gọi là kiến trúc von Neumann, anh em học IT chắc đã nghe qua):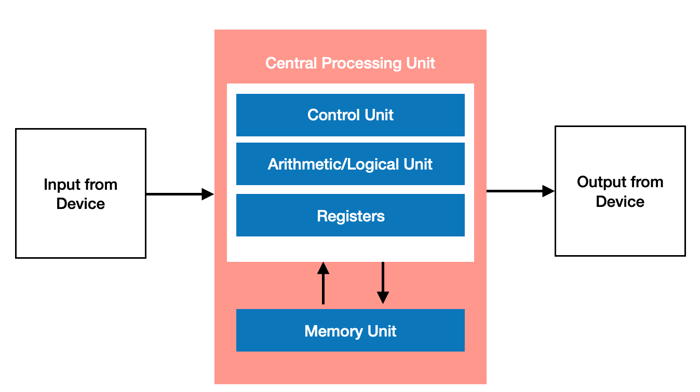 Điểm mạnh của CPU chính là tính linh hoạt cao của nó. Nhờ vào kiến trúc Von Neumann, bạn có thể chạy gần như mọi loại ứng dụng, mọi loại phần mềm, và thực hiện mọi loại tính toán trên một CPU thông thường. Bạn có thể sử dụng CPU để xử lý văn bản, kiểm soát động cơ, thực hiện giao dịch ngân hàng, và thậm chí là sử dụng mạng nơ-ron chạy trên CPU để phân loại hình ảnh.
Tuy nhiên, do tính linh hoạt quá cao, CPU không biết chính xác nó cần phải làm gì tiếp theo. Nó phải đọc lệnh từ phần mềm. Ngoài ra, CPU lưu kết quả tính toán trong những bộ nhớ nhỏ trong CPU (đăng ký hoặc cache) từng bước một. Khi có nhiều tính toán cần thực hiện trong thời gian ngắn, CPU gặp tình trạng 'nghẽn cổ chai' khi không đủ bộ nhớ để lưu trữ, nên phải lưu dữ liệu xuống bộ nhớ cache, và khi cache không đủ, phải lưu xuống RAM, làm chậm quá trình truy xuất dữ liệu.
Điểm mạnh của CPU chính là tính linh hoạt cao của nó. Nhờ vào kiến trúc Von Neumann, bạn có thể chạy gần như mọi loại ứng dụng, mọi loại phần mềm, và thực hiện mọi loại tính toán trên một CPU thông thường. Bạn có thể sử dụng CPU để xử lý văn bản, kiểm soát động cơ, thực hiện giao dịch ngân hàng, và thậm chí là sử dụng mạng nơ-ron chạy trên CPU để phân loại hình ảnh.
Tuy nhiên, do tính linh hoạt quá cao, CPU không biết chính xác nó cần phải làm gì tiếp theo. Nó phải đọc lệnh từ phần mềm. Ngoài ra, CPU lưu kết quả tính toán trong những bộ nhớ nhỏ trong CPU (đăng ký hoặc cache) từng bước một. Khi có nhiều tính toán cần thực hiện trong thời gian ngắn, CPU gặp tình trạng 'nghẽn cổ chai' khi không đủ bộ nhớ để lưu trữ, nên phải lưu dữ liệu xuống bộ nhớ cache, và khi cache không đủ, phải lưu xuống RAM, làm chậm quá trình truy xuất dữ liệu.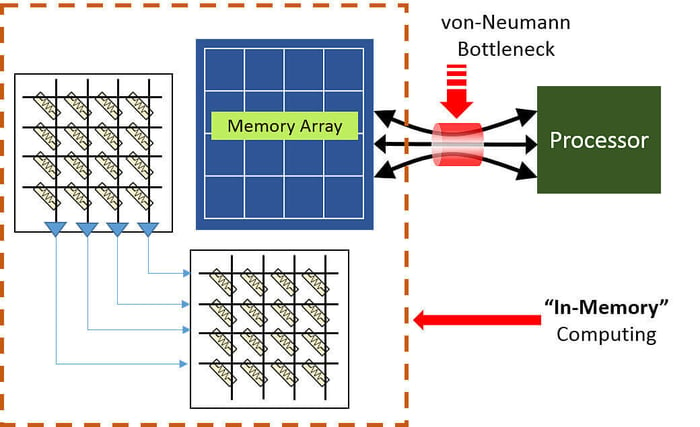 Hơn nữa, mặc dù ngày nay các tính toán neural network có thể dự đoán bước tiếp theo cần tính toán, nhưng mỗi đơn vị kiểm soát phép toán nhân và cộng (Arithmetic Logic Unit - ALU) trong CPU thực hiện từng phép toán một theo thứ tự. Mỗi khi hoàn thành một phép toán, CPU phải truy cập bộ nhớ, khiến cho quá trình xử lý các neural network trở nên chậm hơn và tốn nhiều năng lượng hơn.
Hơn nữa, mặc dù ngày nay các tính toán neural network có thể dự đoán bước tiếp theo cần tính toán, nhưng mỗi đơn vị kiểm soát phép toán nhân và cộng (Arithmetic Logic Unit - ALU) trong CPU thực hiện từng phép toán một theo thứ tự. Mỗi khi hoàn thành một phép toán, CPU phải truy cập bộ nhớ, khiến cho quá trình xử lý các neural network trở nên chậm hơn và tốn nhiều năng lượng hơn.Cách GPU hoạt động là gì?
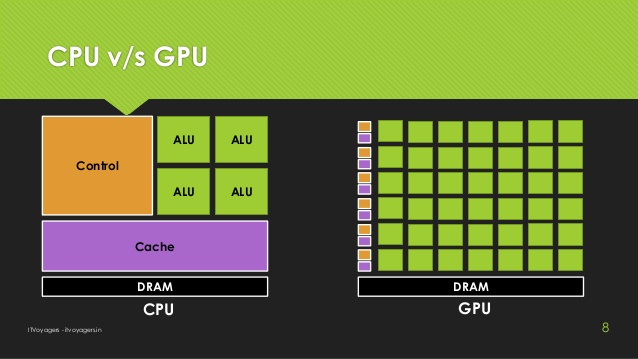 Kiến trúc như vậy giúp GPU trở thành sự lựa chọn phù hợp cho các ứng dụng cần tính toán song song mạnh mẽ, như phép nhân ma trận trong mạng nơ-ron. Đó cũng là lý do tại sao những nhà nghiên cứu AI thường chọn máy tính hoặc server có GPU riêng để làm việc nhanh chóng hơn. GPU cũng là công cụ được sử dụng phổ biến nhất cho việc xử lý học máy tính đến thời điểm hiện tại.
Tuy nhiên, GPU về cơ bản vẫn là một loại bộ xử lý đa dụng, phải hỗ trợ cho nhiều loại phần mềm khác nhau và cũng gặp vấn đề nghẽn cổ chai. Mỗi phép tính của hàng nghìn ALU, GPU vẫn phải truy cập bộ nhớ để đọc dữ liệu đầu vào và lưu kết quả tính toán. Với hàng nghìn ALU, điều này dẫn đến tình trạng tiêu tốn năng lượng cao hơn.
Kiến trúc như vậy giúp GPU trở thành sự lựa chọn phù hợp cho các ứng dụng cần tính toán song song mạnh mẽ, như phép nhân ma trận trong mạng nơ-ron. Đó cũng là lý do tại sao những nhà nghiên cứu AI thường chọn máy tính hoặc server có GPU riêng để làm việc nhanh chóng hơn. GPU cũng là công cụ được sử dụng phổ biến nhất cho việc xử lý học máy tính đến thời điểm hiện tại.
Tuy nhiên, GPU về cơ bản vẫn là một loại bộ xử lý đa dụng, phải hỗ trợ cho nhiều loại phần mềm khác nhau và cũng gặp vấn đề nghẽn cổ chai. Mỗi phép tính của hàng nghìn ALU, GPU vẫn phải truy cập bộ nhớ để đọc dữ liệu đầu vào và lưu kết quả tính toán. Với hàng nghìn ALU, điều này dẫn đến tình trạng tiêu tốn năng lượng cao hơn.Làm thế nào bộ xử lý trí tuệ nhân tạo hoạt động?
Bộ xử lý AI được tạo ra chỉ để thực hiện các công việc liên quan đến trí tuệ nhân tạo. Khác với GPU sử dụng cho đồ họa, hoặc CPU dùng cho nhiều mục đích khác nhau, bộ xử lý AI tập trung vào một nhiệm vụ duy nhất: tính toán ma trận một cách hiệu quả, nhanh chóng và tiết kiệm năng lượng. Điều quan trọng là các bộ xử lý AI như Apple Neural Engine, Qualcomm AI Engine và Samsung Neural Processing Unit (NPU) đã giải quyết vấn đề nghẽn cổ chai von Neumann Bottleneck một cách đáng kể. Với thiết kế tập trung vào tính toán ma trận, phần cứng của các chip này biết chính xác những phép tính cần thiết. Chúng có thể thực hiện hàng nghìn phép nhân và phép cộng và kết nối chúng trực tiếp từ phần cứng. Kiến trúc này được gọi là systolic array. Xem hình dưới đây để hiểu cách tổ chức khi cần nhân 2 ma trận với nhau. Quá trình tính toán của các bộ xử lý trí tuệ nhân tạo diễn ra như sau: chúng lấy dữ liệu từ RAM, đưa vào ma trận ALU để thực hiện phép nhân và cộng. Kết quả được truyền cho phép nhân tiếp theo và bắt đầu cộng kết quả lại. Kết quả cuối cùng là tổng của tất cả phép nhân giữa dữ liệu cần dự đoán và dữ liệu tham chiếu.
Cả quá trình này diễn ra rất nhanh mà không cần lưu dữ liệu lên bộ nhớ sau mỗi lần tính toán. Việc này giúp tăng tốc độ tính toán đồng thời giảm tiêu thụ năng lượng.
Apple không tiết lộ chi tiết về kiến trúc ma trận của Neural Engine, vậy nên hãy tham khảo chip AI của Google, được gọi là TPU. Mỗi Cloud TPU thế hệ thứ 2 của Google sử dụng 2 systolic array có kích thước 128 x 128, tổng cộng có 32.768 nhân ALU để thực hiện các phép tính.
Quá trình tính toán của các bộ xử lý trí tuệ nhân tạo diễn ra như sau: chúng lấy dữ liệu từ RAM, đưa vào ma trận ALU để thực hiện phép nhân và cộng. Kết quả được truyền cho phép nhân tiếp theo và bắt đầu cộng kết quả lại. Kết quả cuối cùng là tổng của tất cả phép nhân giữa dữ liệu cần dự đoán và dữ liệu tham chiếu.
Cả quá trình này diễn ra rất nhanh mà không cần lưu dữ liệu lên bộ nhớ sau mỗi lần tính toán. Việc này giúp tăng tốc độ tính toán đồng thời giảm tiêu thụ năng lượng.
Apple không tiết lộ chi tiết về kiến trúc ma trận của Neural Engine, vậy nên hãy tham khảo chip AI của Google, được gọi là TPU. Mỗi Cloud TPU thế hệ thứ 2 của Google sử dụng 2 systolic array có kích thước 128 x 128, tổng cộng có 32.768 nhân ALU để thực hiện các phép tính.Đóng góp của trí tuệ nhân tạo vào cuộc sống hàng ngày của chúng ta là gì?
Ngày nay, AI đóng vai trò quan trọng trong rất nhiều tính năng của điện thoại và ứng dụng, đặc biệt là trong việc thực hiện phép nhân ma trận. Ví dụ:- Chức năng nhận dạng khuôn mặt Face ID trên iPhone
- Chức năng phân loại khuôn mặt trong thư viện ảnh của điện thoại Android
- Chức năng nhận dạng cảnh để tối ưu hóa hình ảnh
- Loại bỏ phông nền để tạo hiệu ứng chụp ảnh ấn tượng
- Tự động chỉnh sửa từng pixel để cải thiện độ sáng, độ tương phản hoặc độ nét (như Deep Fusion)
- Áp dụng tự động Smart HDR cho các bức ảnh ngoại cảnh, cảnh thiên nhiên
- ….
 Do đó, các nhà sản xuất chip đang tích hợp nhân AI vào bộ xử lý của điện thoại. Bên cạnh đó, một số CPU mới của Intel và chip Apple M1 cũng có tích hợp Neural Engine để sử dụng trên các thiết bị như MacBook, Mac Mini…
Nhờ sự xuất hiện của nhân AI riêng, các tính năng trên sẽ hoạt động nhanh hơn, tiết kiệm điện hơn (tức là thời lượng pin sử dụng kéo dài), và ít phát ra nhiệt hơn.
Để ứng dụng của bên thứ ba có thể tận dụng hoàn toàn sức mạnh của nhân AI, Apple đã cung cấp CoreML, một bộ khung lập trình cho các ứng dụng iOS, trong khi Android có ML Kit để hỗ trợ cho các giải pháp tương tự. Khi được lập trình bằng các công cụ này, hệ điều hành sẽ tự động chuyển sang sử dụng nhân AI khi cần thiết.
Do đó, các nhà sản xuất chip đang tích hợp nhân AI vào bộ xử lý của điện thoại. Bên cạnh đó, một số CPU mới của Intel và chip Apple M1 cũng có tích hợp Neural Engine để sử dụng trên các thiết bị như MacBook, Mac Mini…
Nhờ sự xuất hiện của nhân AI riêng, các tính năng trên sẽ hoạt động nhanh hơn, tiết kiệm điện hơn (tức là thời lượng pin sử dụng kéo dài), và ít phát ra nhiệt hơn.
Để ứng dụng của bên thứ ba có thể tận dụng hoàn toàn sức mạnh của nhân AI, Apple đã cung cấp CoreML, một bộ khung lập trình cho các ứng dụng iOS, trong khi Android có ML Kit để hỗ trợ cho các giải pháp tương tự. Khi được lập trình bằng các công cụ này, hệ điều hành sẽ tự động chuyển sang sử dụng nhân AI khi cần thiết.