

Machine Learning cơ bản là một lĩnh vực ngày càng phổ biến trong cuộc sống của chúng ta. Công nghệ này được con người áp dụng rộng rãi trong nghiên cứu và áp dụng vào nhiều lĩnh vực như công nghiệp, tài chính, ngân hàng, khoa học vũ trụ,… Vậy Machine Learning là gì? Và các thuật toán Machine Learning được phân loại như thế nào? Hãy đọc bài viết để tìm hiểu chi tiết nhé!
Machine Learning cơ bản là gì?
Machine Learning là một lĩnh vực của trí tuệ nhân tạo, gọi tắt là AI và khoa học máy tính. Đơn giản, Machine Learning liên quan đến việc nghiên cứu và xây dựng các kỹ thuật để hệ thống có thể tự động học từ dữ liệu và giải quyết các vấn đề cụ thể. Nó tập trung vào việc sử dụng dữ liệu và thuật toán để giải mã các vấn đề như con người.

Công nghệ Machine Learning cơ bản hoạt động trên nhiều thuật toán chủ yếu được chia thành hai dạng: phân loại và dự đoán. Thuật toán phân loại giúp nhận diện chữ viết, đồ vật, màu sắc,… Trong khi đó, thuật toán dự đoán dùng để dự đoán giá đất, giá xe, giá vàng,… Mặc dù chỉ là một phần của AI, Machine Learning đang ngày càng trở thành một yếu tố không thể thiếu.
Có bao nhiêu loại Machine Learning?
Vậy là bạn đã hiểu định nghĩa cơ bản nhất của Machine Learning rồi đấy. Tiếp theo, chúng ta sẽ cùng tìm hiểu các loại Machine Learning. Hiện nay, Machine Learning được chia thành ba loại chính như sau:
Supervised Machine Learning (Học máy dưới sự giám sát)
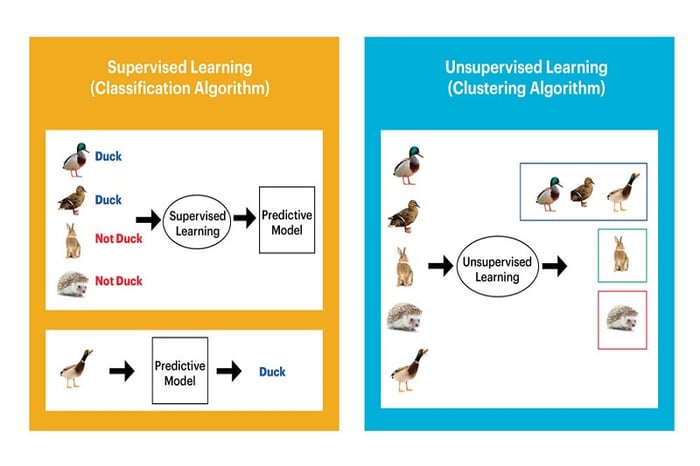
Phân loại Machine Learning là dạng học máy dưới sự giám sát, mô hình hoạt động dựa trên tập dữ liệu đầu vào/đầu ra đã được gán nhãn. Mục tiêu của Supervised Machine Learning là dự đoán đầu ra cho đầu vào như dự đoán giá nhà dựa trên số phòng, diện tích hoặc dự đoán nhiệt độ dựa trên đặc điểm khí hậu,… Ngoài ra, Supervised Machine Learning cũng có thể dự đoán giá cổ phiếu trong tương lai dựa trên giá trị trước đó.
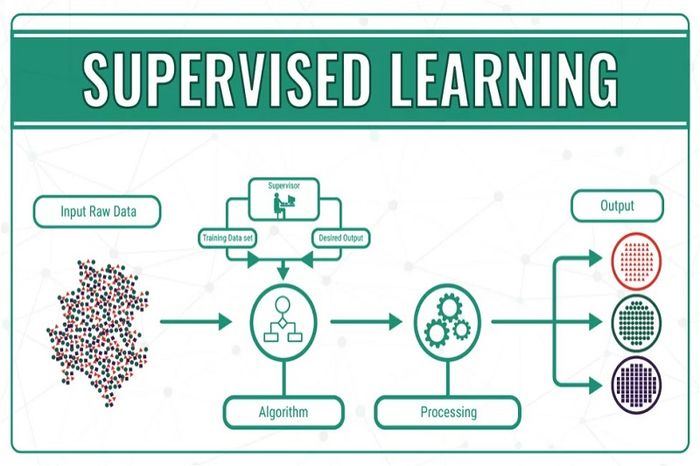
Một nhánh đặc biệt của phân loại Supervised Machine Learning cơ bản là phát hiện và phân loại mẫu dữ liệu. Ví dụ, phát hiện gian lận trong thẻ tín dụng, phát hiện và phân loại đối tượng trong hình ảnh,… Hơn nữa, Supervised Machine Learning còn có thể phân loại sản phẩm vào các danh mục khác nhau, phân loại tin tức vào nhiều chủ đề. Tóm lại, Supervised Machine Learning giúp các doanh nghiệp giải quyết các vấn đề nhanh chóng và có những dự đoán chính xác trong tương lai.
Unsupervised Machine Learning (Học máy không giám sát)
Unsupervised Machine Learning là một phương pháp học tập không giám sát, mô hình xử lý vấn đề trên dữ liệu không được gắn nhãn. Mục tiêu của phân loại Machine Learning cơ bản là tìm ra cấu trúc ẩn trong dữ liệu. Unsupervised Machine Learning có thể phân tách dữ liệu thành các nhóm dựa trên sự tương đồng của các mẫu và xây dựng cây phân cụm để biểu diễn mối quan hệ giữa các mẫu.
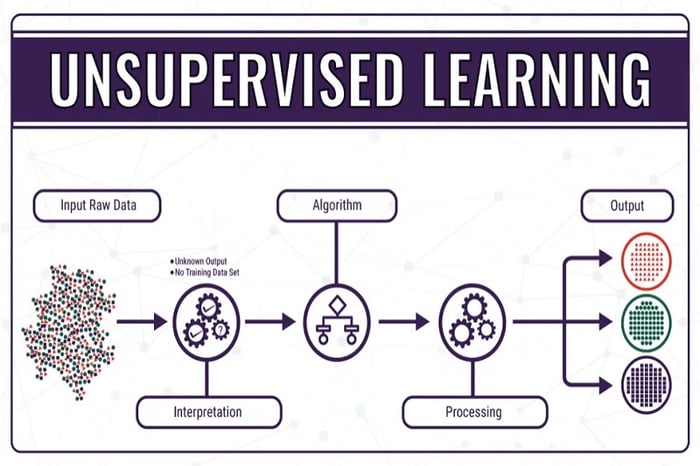
Đối với phân loại phát hiện ngoại lệ, mục tiêu là xác định các điểm dữ liệu khác biệt so với phần còn lại của tập dữ liệu. Unsupervised Machine Learning được áp dụng để phát hiện lỗi trong quá trình sản xuất hoặc phát triển gian lận trong thẻ tín dụng. Tóm lại, Unsupervised Learning thường được sử dụng để khám phá cấu trúc ẩn trong dữ liệu, giúp hiểu rõ hơn về dữ liệu mà không cần can thiệp của con người trong việc gán nhãn.
Semi-supervised Learning (Học máy được giám sát bán phần)
Phân loại Semi-supervised Learning là mô hình được huấn luyện trên một tập dữ liệu kết hợp giữa hai phương pháp: dữ liệu có nhãn và dữ liệu mất nhãn. Ban đầu, mô hình được huấn luyện trên tập dữ liệu có nhãn, sau đó dự đoán các mẫu không có nhãn. Các dự đoán này sau đó được thêm vào tập dữ liệu có nhãn và quá trình này lặp lại. Mục đích của Semi-supervised Learning là tạo ra mô hình có hiệu suất tốt hơn trong nhiều tình huống thực tế.
Những thuật toán Machine Learning cơ bản
Machine Learning sử dụng nhiều thuật toán khác nhau để đưa ra dự đoán chính xác nhất tùy thuộc vào từng tình huống cụ thể.
Thuật toán Linear Regression
Linear Regression là một trong những thuật toán quan trọng trong Machine Learning, đặc biệt trong phân loại Supervised Learning. Thuật toán này dự đoán giá trị liên tục dựa trên dữ liệu đầu vào. Linear Regression tìm mối quan hệ tuyến tính giữa biến đầu vào (X) và biến đầu ra (Y) bằng cách tìm một đường thẳng có dạng Y=mx+b trong đó:
- m là hệ số góc của đường thẳng, còn được gọi là trọng số.
- b là hệ số chặn trục y.
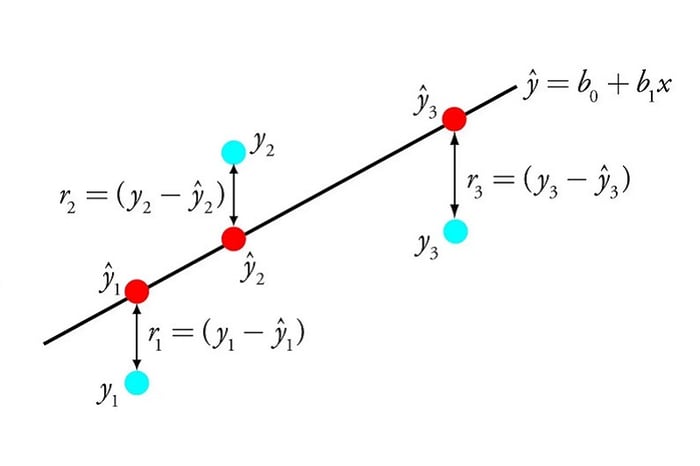
Mục tiêu của thuật toán là điều chỉnh các trọng số m và b sao cho khoảng cách giữa các điểm dữ liệu và đường thẳng là nhỏ nhất, thường được đo bằng cách tính tổng bình phương sai số. Thuật toán Linear Regression được sử dụng để dự đoán doanh số bán hàng dựa trên chi phí quảng cáo, dự đoán giá nhà dựa trên vị trí/ diện tích,…
Thuật toán Logistic Regression
Một trong các thuật toán quan trọng tiếp theo trong Machine Learning cơ bản là Logistic Regression. Thuật toán này được sử dụng để phân loại các mẫu theo cách rời rạc. Logistic Regression bắt đầu bằng việc khởi tạo ngẫu nhiên các giá trị cho b và w, sau đó sử dụng hàm logistic để dự đoán xác suất cho mỗi mẫu. Tiếp theo, thuật toán sử dụng hàm Cross-Entropy Loss để đánh giá sự khác biệt giữa xác suất dự đoán và nhãn thực tế. Để điều chỉnh trọng số b và w, Logistic Regression thường sử dụng gradient descent hoặc các phương pháp tối ưu khác.

Logistic Regression thường được đánh giá bằng các phương pháp như: Accuracy (tỷ lệ dự đoán đúng trên tổng số mẫu), Precision và Recall (giúp ích trong vấn đề có các lớp không cân bằng), F1-score, ROC Curve và AUC. Thuật toán Logistic Regression được áp dụng để dự đoán khả năng khách hàng mua sản phẩm hay không? Dự đoán email là spam hay không spam? Dự đoán bệnh nhân mắc bệnh gì dựa trên dấu hiệu ban đầu.
Thuật toán Decision Tree
Thuật toán cây quyết định của Machine Learning cơ bản được sử dụng rộng rãi nhất. Decision Tree bắt đầu bằng cách chọn thuộc tính tốt nhất để chia dữ liệu thành các nhóm con. Cách chọn nhóm con sẽ dựa trên các tiêu chí, quá trình chia dữ liệu được lặp lại trên mỗi nhóm con tạo thành nhánh mới trên cây. Quá trình chia dữ liệu sẽ dừng lại khi thoả mãn một trong những điều kiện sau: Tất cả các mẫu thuộc về cùng một lớp, không còn thuộc tính nào để chia dữ liệu hay đạt tới một điều kiện dừng trước đó được xác định.
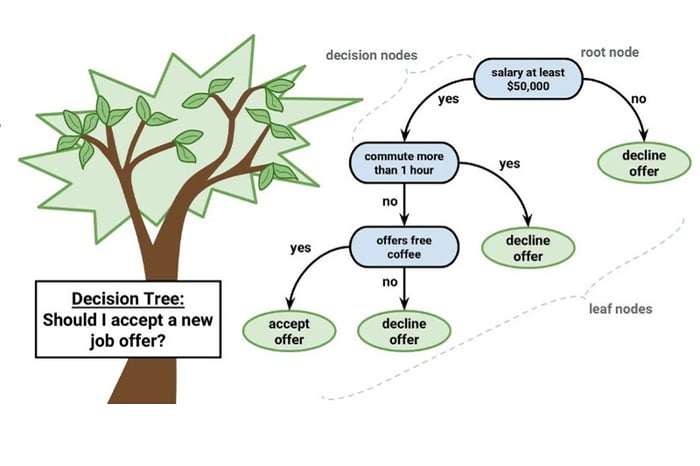
Mỗi nút lá được gán nhãn là lớp phổ biến nhất trong tập dữ liệu con tương ứng. Sau khi xây dựng, cây quyết định có thể được sử dụng để phân loại dữ liệu mới bằng cách áp dụng các quy tắc từ gốc đến lá. Ứng dụng của thuật toán Decision Tree là phân loại, dự đoán trong các vấn đề học máy và khai phá dữ liệu.
Thuật toán Naive Bayes
Naive Bayes là một thuật toán đơn giản trong Machine Learning cơ bản dự đoán chính xác bằng cách giả định sự hiện diện của một đối tượng cụ thể trong một lớp mà không liên quan đến các đối tượng khác. Thuật toán này tính toán các xác suất tiên nghiệm và xác suất điều kiện từ dữ liệu đầu vào. Naive Bayes được sử dụng rộng rãi để phân loại văn bản, phát hiện spam,…
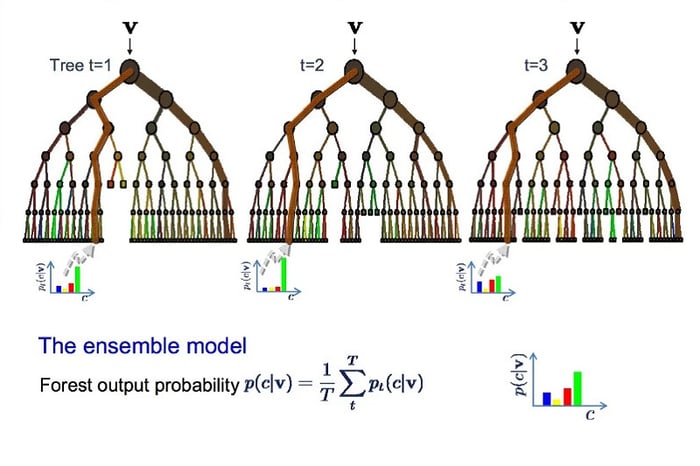
Thuật toán Random Forest
Random Forest là một phương pháp kết hợp xây dựng nhiều cây quyết định để tạo ra một mô hình Machine Learning cơ bản ổn định và mạnh mẽ hơn. Mỗi cây quyết định trong Random Forest được huấn luyện trên một tập con ngẫu nhiên của dữ liệu. Sau đó, mỗi cây quyết định dự đoán cho một mẫu và tổng hợp kết quả dự đoán từ tất cả các cây con. Khi có dữ liệu mới cần dự đoán, Random Forest sẽ đưa ra kết quả bằng cách kết hợp dự đoán từ tất cả các cây con. Cuối cùng, thuật toán sẽ chọn kết quả được bỏ phiếu nhiều nhất để đưa ra kết luận về vấn đề hoặc tình huống cụ thể.
Thuật toán Giảm Chiều Dữ Liệu
Hiện nay, các tổ chức, công ty và chính phủ đối mặt với lượng dữ liệu lớn cần phân tích và nghiên cứu. Dữ liệu thô chứa nhiều thông tin quan trọng, nhưng một thách thức lớn là phải xác định các mẫu và biến quan trọng trong đó. Thuật toán Giảm Chiều Dữ Liệu hỗ trợ chuyển đổi dữ liệu từ không gian chiều cao xuống chiều thấp, giữ lại các thuộc tính có ý nghĩa trong dữ liệu ban đầu. Sử dụng thuật toán này giúp dễ dàng tìm thấy các chi tiết liên quan.
Ứng dụng của Machine Learning trong thực tế như thế nào?
Hiện nay, Machine Learning cơ bản đang được áp dụng rộng rãi trong nhiều lĩnh vực của cuộc sống như Công nghệ thông tin, Chẩn đoán y tế, Dự báo tài chính – Kinh doanh,… Một ví dụ điển hình về ứng dụng của Machine Learning trong đời sống là Dự báo thời tiết: Các mô hình đã được huấn luyện dựa trên dữ liệu thời tiết trong quá khứ để dự đoán thời tiết trong tương lai bao gồm nhiệt độ, độ ẩm, áp suất không khí, gió, mây mù,…
Các mô hình giám sát được sử dụng để dự đoán các yếu tố cụ thể của thời tiết như nhiệt độ, độ ẩm hoặc lượng mưa. Trong khi đó, các kỹ thuật không giám sát có thể được áp dụng để phát hiện các mẫu và cấu trúc tự nhiên trong dữ liệu thời tiết mà không cần nhãn.
Dữ liệu thời tiết thường không đồng đều và có thể bị thiếu sót. Machine Learning có thể được dùng để xử lý dữ liệu này, bao gồm điền giá trị thiếu, loại bỏ nhiễu và điều chỉnh dữ liệu không đồng nhất để tạo ra dự báo chính xác hơn. Những yếu tố này giúp cải thiện khả năng dự báo thời tiết, hỗ trợ người dùng và các tổ chức chuẩn bị tốt hơn cho điều kiện thời tiết sắp tới.
Kết Luận
Vậy là chúng tôi đã giới thiệu những mô hình Machine Learning cơ bản cho các bạn tham khảo. Machine Learning có ứng dụng rộng rãi trong các lĩnh vực của cuộc sống như nghiên cứu thị trường, y tế, tài chính kinh doanh,… Biết cách sử dụng Machine Learning, bạn có thể đạt được các mục tiêu quan trọng trong lĩnh vực mình đang theo đuổi. Hãy theo dõi fanpage Mytour và Mytour để cập nhật những thông tin thú vị từ chúng tôi nhé!