
Deep Q-Learning là một thuật toán quan trọng khi tìm hiểu về trí tuệ nhân tạo (AI), đặc biệt trong các lĩnh vực như game, robot tự động, quản lý tài nguyên mạng và ứng dụng đa dạng khác. Hãy khám phá kiến thức cơ bản ngay dưới đây.
Học tăng cường (Reinforcement Learning) là gì?
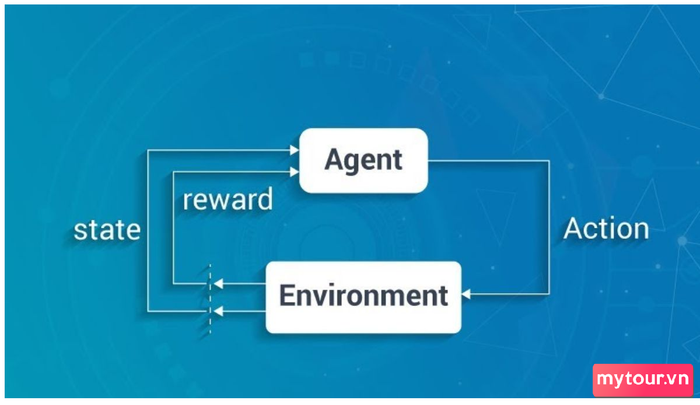
Reinforcement Learning hoạt động trong lĩnh vực trí tuệ nhân tạo, nơi máy tính được huấn luyện để thực hiện nhiệm vụ mà không cần dữ liệu chính xác từ trước. Agent tương tác với môi trường, tự học từ trải nghiệm để đưa ra quyết định và hành động mục tiêu.
Quy trình Reinforcement Learning thường bao gồm quan sát trạng thái, thực hiện hành động, chuyển trạng thái, nhận thưởng và cập nhật chiến lược. Các thuật toán RL khác nhau như Q-Learning, Deep Q Networks (DQN), Gradient Policy, đều đóng vai trò quan trọng.
Thuật toán Q-Learning là gì?
Q-Learning là thuật toán học tăng cường (Reinforcement Learning) trong lĩnh vực không giám sát, giúp máy tính tự học chiến lược tối ưu cho tác nhân trong môi trường không biết trước.
Thuật toán này sử dụng bảng số liệu (Q-table) để 'ghi nhớ' cách hành động ở mỗi tình huống và cập nhật dựa trên thưởng hoặc hình phạt nhận được. Giúp máy tính tự điều chỉnh để đạt được kết quả tốt nhất trong môi trường đang hoạt động.
Ví dụ: Trong việc dạy máy tính chơi trò chơi, mô hình Q giúp nó học cách chọn hành động tại mỗi tình huống để tối đa hóa tổng điểm thưởng.
Quy định quan trọng trong Q-Learning
Hiểu ý nghĩa và tác động của các tham số như Tỉ lệ Học (Learning Rate), Hệ số Chiết khấu (Discount Factor) giúp tối ưu hóa chúng cho từng bài toán cụ thể khi thực hiện thuật toán Q-Learning.
| Thuật ngữ | Mô tả | Ví dụ |
| Q-Value | Số liệu ước lượng cho hành động tại mỗi trạng thái. | Q (s,a) là giá trị dự đoán khi thực hiện hành động a tại trạng thái s. |
| Learning Rate (alpha) | Điều chỉnh mức độ cập nhật giá trị Q sau mỗi bước học. | Nếu alpha = 0.1, tác nhân chỉ học 10% từ thông tin mới mỗi bước. |
| Discount Factor (gamma) | Quyết định tầm quan trọng của thưởng trong tương lai. | Nếu gamma = 0.9, tác nhân ưu tiên thưởng tương lai với 90% trọng số. |
| Exploration-Exploitation | Quyết định giữa khám phá môi trường và khai thác kiến thức đã học. | Sử dụng Epsilon-Greedy Policy - nếu Epsilon nhỏ, ít khám phá và nhiều khai thác. |
| Reward | Số liệu môi trường cung cấp sau mỗi hành động. | Nếu r = 1, tác nhân nhận thưởng bằng 1 sau khi thực hiện hành động. |
| Policy | Cách tác nhân chọn hành động trong mỗi trạng thái. | Sử dụng Q (s, a) để chọn hành động tối ưu (a) cho trạng thái s. |
Khái niệm Phương trình Bellman là gì?
Khái niệm Bellman là một yếu tố quan trọng trong lĩnh vực học tăng cường, đặc biệt khi sử dụng các phương pháp như Q-Learning hay thuật toán chính sách (Policy Iteration, Value Iteration). Cụ thể, có hai biến thể chính:
- Phương trình Bellman cho giá trị (Bellman Expectation Equation) mô tả một cách tổng quát giá trị của một trạng thái bằng cách tính kỳ vọng của tổng giá trị tương lai.
- Phương trình Bellman cho hàm giá trị hành động (Bellman Optimality Equation) mô tả giá trị của một hành động bằng cách tính kỳ vọng của tổng giá trị tương lai khi thực hiện hành động a tại trạng thái s.
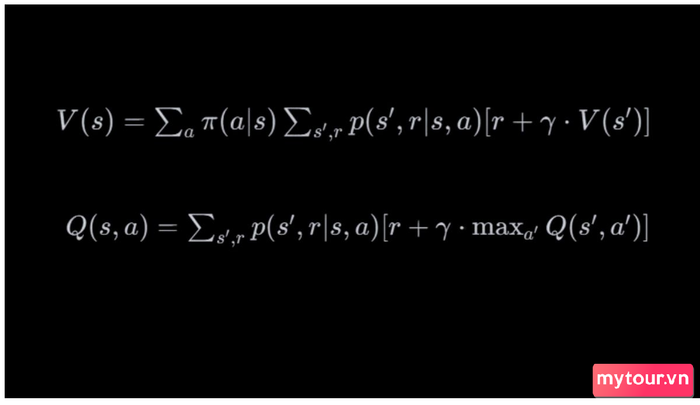 Khái niệm Bellman
Khái niệm Bellman
Khái niệm Bellman là công cụ quan trọng giúp hiểu rõ quy trình cập nhật giá trị trong quá trình học tăng cường và được ứng dụng rộng rãi trong nhiều thuật toán.
Mô hình Deep Q-Learning
Deep Q-Learning là mô hình học máy sử dụng mạng nơ-ron để ước lượng hàm giá trị hành động (Q-value) trong bài toán học tăng cường. Đây là một phần của lĩnh vực Reinforcement Learning (Học tăng cường) và được sử dụng rộng rãi trong việc huấn luyện các hệ thống tự động đưa ra quyết định trong môi trường động.
| Bước | Mô tả |
| Môi trường | Nơi agent thực hiện hành động và nhận phản hồi. |
| Hàm giá trị Q | Ước lượng giá trị của mỗi hành động trong mỗi trạng thái, thường sử dụng mạng nơ-ron. |
| Trải nghiệm | Agent lưu trữ cặp (trạng thái, hành động, phần thưởng, trạng thái tiếp theo) từ hành động của nó. |
| Bộ nhớ đệm | Lưu trữ và lấy mẫu ngẫu nhiên các trạng thái từ quá khứ để ổn định quá trình học. |
| Hàm mất mát | Sử dụng hàm mất mát như Mean Squared Error để đo lường chênh lệch giữa giá trị Q thực tế và dự đoán. |
| Quyết định hành động | Chọn hành động dựa trên chiến lược Epsilon-Greedy, thỉnh thoảng thực hiện hành động ngẫu nhiên để khám phá. |
| Huấn luyện mô hình | Dự đoán giá trị Q, cập nhật trọng số mô hình từ mẫu ngẫu nhiên để giảm thiểu mất mát. |
| Lặp lại quá trình | Tiếp tục quá trình này cho đến khi mô hình học được chiến lược tối ưu hoặc đạt được tiêu chí dừng. |
Một Ví dụ về Q-Learning sử dụng Python
Để có cái nhìn cụ thể về thuật toán Q-Learning trong thực tế, chúng ta sẽ thực hiện một ví dụ minh họa. Dưới đây là một bài toán đơn giản về tối ưu hóa đường đi trong môi trường lưới.
Giả sử có một lưới 3x3, và agent cần di chuyển từ góc trên bên trái đến góc dưới bên phải, tránh các ô có giá trị âm và chọn đường đi có giá trị cao nhất. Bạn có thể thực hiện các bước sau.
Khởi tạo Môi trường Lưới 3x3
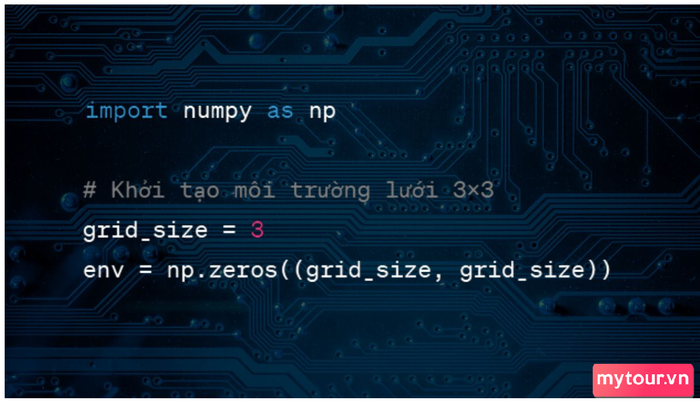 Mã khởi tạo môi trường lưới 3x3
Mã khởi tạo môi trường lưới 3x3
Giải thích: Tạo một môi trường lưới có kích thước 3x3 và khởi tạo một ma trận 0 để biểu diễn trạng thái ban đầu của môi trường.
Đặt Giá Trị Thưởng và Phạt Trong Môi Trường
| Code: |
| env[1, 1] = 1 # Điểm đích với giá trị phần thưởng env[0, 1] = -1 # Ô có giá trị âm, tránh vùng này |
Mô tả: Đặt giá trị 1 tại ô (1,1) để biểu diễn điểm đích với thưởng và giá trị -1 tại ô (0,1) để biểu diễn một vùng cấm.
Khởi Tạo Ma Trận Q-Learning với Giá Trị Ban Đầu
| Code: |
| Q = np.zeros((grid_size, grid_size)) |
Mô tả: Khởi tạo ma trận Q với giá trị 0. Ma trận Q này sẽ lưu trữ ước lượng giá trị của hàm Q cho từng trạng thái và hành động.
Tham Số Học
| Code: |
| learning_rate = 0.8 discount_factor = 0.95 num_episodes = 1000 |
Mô tả: Đặt các tham số học, bao gồm tỷ lệ học (learning_rate), hệ số giảm (discount_factor), và số lượng tập huấn luyện (num_episodes).
Chức Năng Lựa Chọn Hành Động
| Code: |
| def choose_action(state): possible_actions = np.where(env[state] != -1)[0] # Lấy tất cả các hành động có thể return np.random.choice(possible_actions) |
Chức năng này chọn một hành động ngẫu nhiên từ những hành động có thể thực hiện, tránh các ô cấm.
Đào Tạo Mô Hình Q-Learning
| Code: |
| for episode in range(num_episodes): current_state = (0, 0) # Bắt đầu từ góc trên bên trái while current_state != (grid_size - 1, grid_size - 1): # Cho đến khi đến đích action = choose_action(current_state) next_state = (current_state[0] + action // grid_size, current_state[1] + action % grid_size) # Cập nhật Q-value Q[current_state] = (1 - learning_rate) * Q[current_state] + learning_rate * (env[next_state] + discount_factor * np.max(Q[next_state])) current_state = next_state |
Mô tả: Vòng lặp bên ngoài là vòng lặp qua các tập huấn luyện. Trong mỗi tập, agent bắt đầu từ trạng thái ban đầu và thực hiện các hành động cho đến khi đạt đến đích. Trong quá trình này, Q-value được cập nhật dựa trên phần thưởng và giá trị Q của trạng thái tiếp theo.
In Ra Ma Trận Q-Learning Sau Khi Đào Tạo
| Code: |
| print("Q-value matrix:") print(Q) |
Mô tả: In ra ma trận Q sau khi đào tạo để xem giá trị Q đã được cập nhật.
Mọi người đều có thể thực hiện những bước lập trình như trên nếu dành đủ thời gian để rèn luyện. Để bắt đầu, không thể thiếu chiếc laptop với cấu hình phù hợp như một người bạn đồng hành quan trọng trong suốt quá trình này.
Kiến thức cơ bản về thuật toán Deep Q-Learning có thể giúp bạn có cái nhìn tổng quan về lĩnh vực này. Mặc dù chỉ là mức tiếp cận, nhưng bạn có thể sử dụng chúng để xây dựng lộ trình của riêng mình.
- Khám Phá Thêm: Thuật Ngữ Công Nghệ, AI