
Mô hình ngôn ngữ mới của DeepMind với 280 tỷ tham số vượt xa GPT-3 về độ chính xác

Buông lỏng đi, GPT-3, có một đối thủ mới năng động tranh giành vương miện của mô hình ngôn ngữ xuất sắc nhất thế giới, và đến từ những người bạn cũ tại DeepMind.
Ngay từ đầu: Công ty con của Alphabet ở Anh, đã giải quyết câu hỏi liệu con người hay máy tính giỏi hơn ở cờ vua một cách dứt khoát - máy tính đã chiến thắng - và giờ đây họ đã nhắm mục tiêu vào thế giới của các mô hình ngôn ngữ lớn (LLM).
Để đạt được mục tiêu đó, họ vừa công bố "Gopher", một mô hình ngôn ngữ có khoảng 60% lớn hơn về tham số so với GPT-3 và khoảng một phần tư kích thước của LLM của Google với 1 nghìn tỷ tham số.
Theo thông cáo báo chí trên blog của DeepMind:
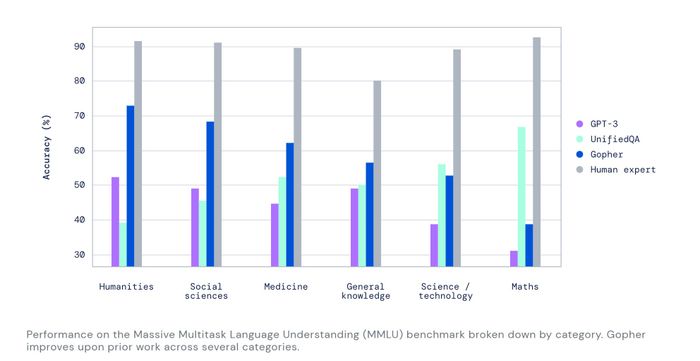
Trong nghiên cứu của chúng tôi, chúng tôi phát hiện ra rằng khả năng của Gopher vượt trội so với các mô hình ngôn ngữ hiện tại đối với nhiều nhiệm vụ quan trọng. Điều này bao gồm cả bài kiểm tra Massive Multitask Language Understanding (MMLU), trong đó Gopher chứng minh sự tiến bộ đáng kể đến hiệu suất của chuyên gia con người so với công việc trước đó.
Hội nghị TNW 2024 - Kêu gọi tất cả các Startups tham gia vào ngày 20-21 tháng 6
Trưng bày Startup của bạn trước nhà đầu tư, những người thay đổi và khách hàng tiềm năng với gói Startup được tạo ra đặc biệt của chúng tôi.
Nền tảng: DeepMind đạt được những cải tiến bằng cách tập trung vào những lĩnh vực nơi việc mở rộng kích thước của mô hình AI mang lại ý nghĩa.
Mức công suất bạn có thể đẩy vào một mô hình AI, ví dụ, cho việc hiểu đọc, càng nhiều càng tốt. Nhưng nhóm phát hiện rằng các lĩnh vực khác của kiến trúc LLM không hưởng lợi nhiều từ sức mạnh brute force.
Bằng cách ưu tiên cách hệ thống sử dụng và phân phối tài nguyên, nhóm đã có thể điều chỉnh thuật toán của họ để vượt qua các mô hình tiên tiến hiện đại trong 80% các bài kiểm tra được sử dụng.
 Credit: DeepMind
Credit: DeepMindNhóm DeepMind cũng đã công bố các bài nói về đạo đức và kiến trúc của LLM, bạn có thể đọc những bài nói đó tại đây và tại đây.
Ý kiến nhanh: Nói mượn từ nhà thơ vĩ đại Montell Jordan: đây là cách bạn thực hiện điều đó. Thay vì đưa lĩnh vực này vào bờ vực hủy hoại bằng cách tăng kích thước của mô hình một cách lũng đoạn cho đến khi GPT-5 hoặc GPT-6 lớn hơn cả vũ trụ đã biết, DeepMind đang cố gắng nén thêm sức mạnh từ những mô hình nhỏ hơn.
Đừng hiểu lầm, Gopher có đáng kể nhiều tham số hơn so với GPT-3. Nhưng, khi bạn cân nhắc rằng GPT-4 dự kiến sẽ có khoảng 100 nghìn tỷ tham số, có vẻ như DeepMind đang di chuyển theo hướng có vẻ khả thi hơn.