
 Ngay sau khi Meta giới thiệu mô hình Llama 3, gần như ngay lập tức Intel cũng công bố về những con chip của hãng đã thể hiện ra sao với mô hình AI mới này của Meta, đồng thời cung cấp chi tiết về các điểm chuẩn của các dòng chip khi được kiểm thử với Llama 3.Với mục tiêu “AI Everywhere”, Intel không thể chậm trễ trong việc tối ưu hóa các dòng chip hiện có của mình với các mô hình AI mới nhất. Các dòng vi xử lý từ Gaudi 2 và Gaudi 3, Xeon Scalable Granite Rapids cho đến các dòng Intel Core Ultra cho người dùng thông thường và dòng GPU Arc đều đã sẵn sàng cho Llama 3.
Ngay sau khi Meta giới thiệu mô hình Llama 3, gần như ngay lập tức Intel cũng công bố về những con chip của hãng đã thể hiện ra sao với mô hình AI mới này của Meta, đồng thời cung cấp chi tiết về các điểm chuẩn của các dòng chip khi được kiểm thử với Llama 3.Với mục tiêu “AI Everywhere”, Intel không thể chậm trễ trong việc tối ưu hóa các dòng chip hiện có của mình với các mô hình AI mới nhất. Các dòng vi xử lý từ Gaudi 2 và Gaudi 3, Xeon Scalable Granite Rapids cho đến các dòng Intel Core Ultra cho người dùng thông thường và dòng GPU Arc đều đã sẵn sàng cho Llama 3.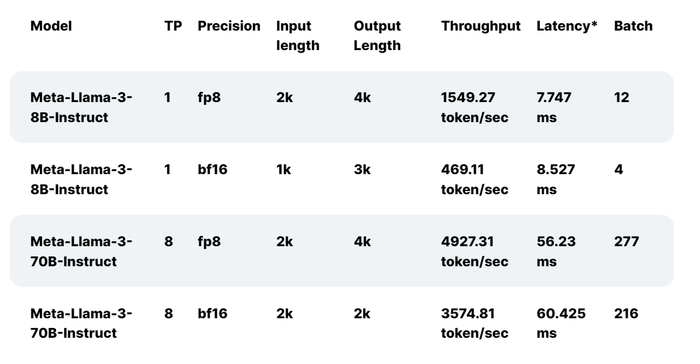
 Các dòng chip Gaudi 2 trước đây đã được thử nghiệm với Llama 2 từ 7 tỷ, 13 tỷ và 70 tỷ tham số. Bây giờ, Gaudi 2 tiếp tục được tối ưu hóa với Llama 3. Kết quả thể hiện ở bảng benchmark trên, giữa hai phiên bản inference và phiên bản đã được điều chỉnh của Llama 3, mỗi phiên bản sẽ có 2 tham số khác nhau.
Các dòng chip Gaudi 2 trước đây đã được thử nghiệm với Llama 2 từ 7 tỷ, 13 tỷ và 70 tỷ tham số. Bây giờ, Gaudi 2 tiếp tục được tối ưu hóa với Llama 3. Kết quả thể hiện ở bảng benchmark trên, giữa hai phiên bản inference và phiên bản đã được điều chỉnh của Llama 3, mỗi phiên bản sẽ có 2 tham số khác nhau.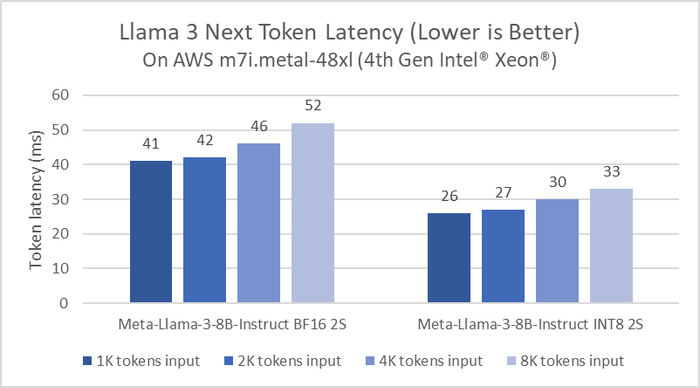 Hiệu suất suy luận của Meta Llama 3 8B trên phiên bản AWS m7i.metal-48x dựa trên Intel Xeon Scalable Shappire Rapids.
Hiệu suất suy luận của Meta Llama 3 8B trên phiên bản AWS m7i.metal-48x dựa trên Intel Xeon Scalable Shappire Rapids.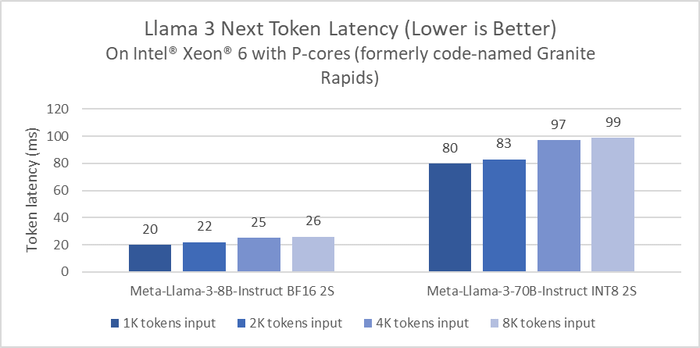 Khi Intel thử nghiệm benchmark Llama 3 trên thế hệ mới nhất của Intel Xeon, Granite Rapids, độ trễ suy luận của Llama 3 8B cải thiện gấp 2 lần so với các dòng chip Intel Xeon thế hệ 4. Với các model lớn hơn như Llama 3 70B, độ trễ đều dưới 100ms cho mỗi token, trong 1 server với 2 socket. Lưu ý là tại sự kiện Intel Vision 2024, Intel đã thay đổi tên gọi của dòng chip Intel Xeon Scalable thành Intel Xeon. Granite Rapids là dòng chip Intel Xeon 6 với các nhân P sẽ ra mắt vào nửa cuối năm nay, còn dòng chip Intel Xeon 6 với các nhân E (Sierra Forest) sẽ ra mắt trong quý 2 này.
Khi Intel thử nghiệm benchmark Llama 3 trên thế hệ mới nhất của Intel Xeon, Granite Rapids, độ trễ suy luận của Llama 3 8B cải thiện gấp 2 lần so với các dòng chip Intel Xeon thế hệ 4. Với các model lớn hơn như Llama 3 70B, độ trễ đều dưới 100ms cho mỗi token, trong 1 server với 2 socket. Lưu ý là tại sự kiện Intel Vision 2024, Intel đã thay đổi tên gọi của dòng chip Intel Xeon Scalable thành Intel Xeon. Granite Rapids là dòng chip Intel Xeon 6 với các nhân P sẽ ra mắt vào nửa cuối năm nay, còn dòng chip Intel Xeon 6 với các nhân E (Sierra Forest) sẽ ra mắt trong quý 2 này.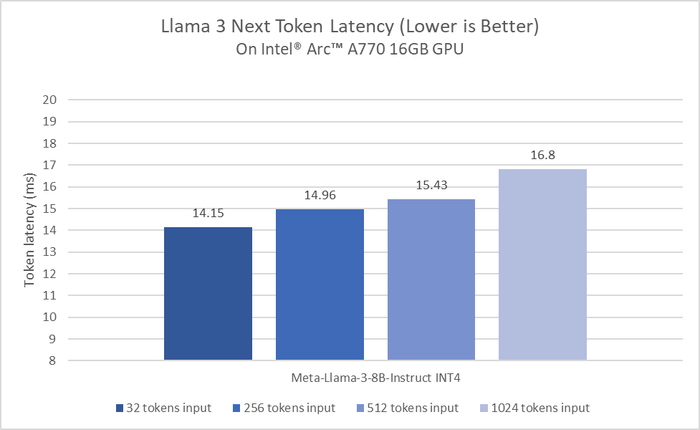 Với các dòng vi xử lý dành cho người dùng cuối như Intel Core Ultra và GPU Intel Arc, Intel đã thể hiện hiệu suất của iGPU trong Core Ultra H series và dGPU Intel Arc A770 khi thử nghiệm với model Llama 3 8B Instruct INT4, độ trễ chung là dưới 20ms.
Với các dòng vi xử lý dành cho người dùng cuối như Intel Core Ultra và GPU Intel Arc, Intel đã thể hiện hiệu suất của iGPU trong Core Ultra H series và dGPU Intel Arc A770 khi thử nghiệm với model Llama 3 8B Instruct INT4, độ trễ chung là dưới 20ms. Đối với iGPU 8 nhân Xe trong Intel Core Ultra, tốc độ đáp ứng nhanh hơn tốc độ đọc bình thường của con người, nhờ vào bộ tăng tốc AI DP4a và băng thông bộ nhớ lên đến 120GB/s. Intel cam kết sẽ tiếp tục tối ưu hiệu suất và hiệu quả năng lượng với Llama 3 trên các thế hệ vi xử lý tiếp theo.
Đối với iGPU 8 nhân Xe trong Intel Core Ultra, tốc độ đáp ứng nhanh hơn tốc độ đọc bình thường của con người, nhờ vào bộ tăng tốc AI DP4a và băng thông bộ nhớ lên đến 120GB/s. Intel cam kết sẽ tiếp tục tối ưu hiệu suất và hiệu quả năng lượng với Llama 3 trên các thế hệ vi xử lý tiếp theo.