

“Summarise the information by selecting and reporting the main features, and make comparisons where relevant. “ Đây có lẽ là một thông điệp đã quá đỗi quen thuộc với những thí sinh IELTS, nó xuất hiện ở trong khung trên một biểu đồ trong IELTS Writing Task 1, đưa ra gợi ý những nhiệm vụ mà thí sinh cần phải thực hiện trong bài viết của mình. Hiển nhiên, những dòng chữ này không cần phải được để ý nữa, bởi hầu như loại biểu đồ nào cũng mang thông điệp này và sau quá trình luyện tập, các thí sinh cũng đều biết mỗi dạng biểu đồ yêu cầu họ trình bày những thông tin gì.
Tuy thí sinh nào khi bước vào phòng thi cũng đều có những khái niệm nhất định về những điều cần viết xuống để tiếp cận từng dạng biểu đồ nhất định, từ những số liệu lớn nhất – nhỏ nhất đến những xu hướng tăng, giảm, dao động, v.v., nhưng đôi khi việc liệt kê hết những yếu tố trên vẫn chưa đảm bảo được một thang điểm cao cho tiêu chí Task Achievement trong IELTS Writing Task 1.
Vấn đề ở đây nằm trong việc có thể thí sinh tập trung vào việc liệt kê lại số liệu mà lại quên đi nửa vế sau trong thông điệp quen thuộc đầu bài, đó là “make comparisons where relevant”. Việc so sánh ở đây không phải được thực hiện đơn thuần bằng cách thêm vào những cụm “compared to”, “as opposed to” hoặc là dùng những từ nối “while” hay “whereas” trong lúc người viết liệt kê thông tin.
Vậy câu hỏi được đặt ra ở đây là việc so sánh giữa những số liệu nên được thực hiện như thế nào?
Mấu chốt ở đây nằm trong mối quan hệ giữa những số liệu.
Tối ưu hóa việc tổng hợp thông tin trong Bài Viết 1 của IELTS
Trong bài IELTS Writing Task 1, tên của đối tượng phân tích thông thường đã xuất hiện ở trong thông điệp của đề bài. Tuy nhiên, khi nhìn vào biểu đồ, người viết mới nhận ra rằng đối tượng đó sẽ được chia ra làm nhiều hạng mục (category – hay còn có thể hiểu là “loại hình” hoặc “nhóm”) khác nhau, với các số liệu và xu hướng thay đổi khác nhau ứng với từng hạng mục. Việc số lượng của các hạng mục càng nhiều đôi lúc cũng đồng nghĩa với độ khó của bài càng cao.
Cũng càng vì lí do này mà thí sinh cần phải hiểu rằng việc liệt kê hết các số liệu không phải lúc nào cũng là cách tối ưu để cung cấp thông tin trong bài viết IELTS Writing Task 1, và chính vì vậy, để tiếp cận được các biểu đồ này, thí sinh cần phải có một phương pháp “hệ thống hoá” để đưa các số liệu này về những tập hợp lớn, dựa trên những điểm tương đồng của các phần tử và những điểm tương phản giữa các tập hợp này.
Tập hợp và các nguyên lý cơ bản trong Bài Viết 1 của IELTS
Tuỳ thuộc vào loại biểu đồ số liệu (tức loại trừ dạng map và diagram/process) là time chart (line graph, bar charts) hay comparison chart (pie chart, bar chart, table) mà thông tin được thể hiện phù hợp.
Đối với IELTS Writing Task 1, dạng biểu đồ đường thẳng (line graph) và một vài loại biểu đồ cột (bar chart), thông thường trục dọc sẽ là trục thể hiện giá trị (con số đi kèm với đơn vị) và trục ngang thể hiện thời gian (các mốc thời gian) hoặc thể loại (các loại mục khác biệt thuộc cùng chung 1 phạm trù). Các yếu tố này sẽ được thể hiện theo những hình thức khác nhau ở các dạng biểu đồ hình tròn (pie chart) và dạng biểu đồ bảng (table), nhưng về bản chất chúng vẫn như vậy và vẫn thể hiện những loại thông tin như đã đề cập ở trên. Tuy nhiên, một trong hai yếu tố thể loại hoặc thời gian sẽ xuất hiện, và thí sinh có thể dựa vào chúng để phân chia và tập hợp hoá các thông tin.
Ngoài ra, khi các hạng mục hoặc/và các mốc thời gian có số lượng lớn hơn 02 (ví dụ có 4 hạng mục được thể hiện qua 10 mốc thời gian, như đề bài mẫu ở đây), sẽ luôn tồn tại những mối quan hệ tương đồng và tương phản giữa các số liệu.
Mối quan hệ tương tự
Đây là mối quan hệ giữa các hạng mục có số liệu ở một mức cao, thấp gần tương đồng với nhau về giá trị, hoặc/và theo những xu hướng chung khá giống nhau, hoặc có bản chất rơi vào một phạm trù chung – ví dụ như những ngày Monday, Tuesday,.. Friday có thể rơi vào một phạm trù chung là Weekdays, còn Saturday và Sunday sẽ rơi vào phạm trù Weekends.
Mối quan hệ tương phản
Đây là mối quan hệ giữa các hạng mục mà có số liệu mang tính trái ngược nhau, chẳng hạn như số liệu mang giá trị cao nhất tương phản với số liệu mang giá trị thấp nhất, và/hoặc thể hiện các xu hướng khác nhau hoặc hoàn toàn trái ngược nhau. Đối tượng của mối quan hệ này bao gồm cả những hạng mục rơi vào một phạm trù cụ thể mà trái ngược với một phạm trù khác bao trùm những loại mục còn lại – ví dụ như 3 hạng mục coal, gas, petrol/oil sẽ thuộc về tập hợp chung gọi là fossil-fuel energy trái ngược lại với tập hợp renewable energy gồm nuclear, wind, solar energy.
⇒ Người viết có thể dựa vào hai mối quan hệ trên giữa những số liệu để đưa chúng về những tập hợp lớn thuận lợi cho việc so sánh.
Tuy nhiên những tập hợp này không thể đứng riêng lẻ một cách không liên quan đến nhau được. Người viết cần phải biết cách sắp đặt những tập hợp này vào các vị trí phù hợp để làm nổi bật lên được những mối quan hệ giữa lẫn các tập hợp và các phần tử con của tập hợp.
Ta có thể ví những tập hợp như những hạt cườm nhỏ (beads) mang nhiều màu khác nhau, mà sẽ cùng nhau tạo thành một sợi dây chuyền số liệu. Khi ta đã có những hạt cần thiết, thứ mà ta cần tiếp theo, và có thể là quan trọng nhất, là một sợi dây (thread) mà sẽ nối các hạt lại thành một chuối hài hoà. Thú vị thay, thread ở đây còn có một nghĩa bóng là “mạch”, hoàn toàn phù hợp với trường hợp của thứ đang được ẩn dụ ở đây. Thật vậy, bài viết nào cũng sẽ cần một cái mạch để mà dựa vào đó người viết có thể sắp xếp các thông tin một cách hợp lí. Vậy một bài viết IELTS Writing Task 1 sẽ nên mang một mạch như thế nào?
Nói cách khác, thứ mà ta cần ở đây là tiêu chí mà dựa vào đó hai đoạn thân bài của bài viết sẽ được chia ra để phù hợp cho việc sắp xếp các tập hợp số liệu. Cho mục đích này, ta có thể ứng dụng hai yếu tố thể loại và thời gian, theo nguyên tắc sau.
Nguyên tắc “Ít là nhiều hơn”
Nguyên lý hoạt động
Tuỳ thuộc vào số lượng của hai yếu tố thể loại và thời gian, tức là có bao nhiêu loại mục và có bao nhiêu mốc thời gian, mà người viết có thể dựa vào để chia đoạn. Thông thường, số lượng của yếu tố nào ít hơn thì sẽ được dùng để làm tiêu chí chia đoạn cho bài văn.
Lí do cho sự hiệu quả của nguyên tắc này có thể được hiểu dựa trên mô hình mẫu dưới đây:
| 1 | 2 | 3 |
A | A1 | A2 | A3 |
B | B1 | B2 | B3 |
C | C1 | C2 | C3 |
D | D1 | D2 | D3 |
E | E1 | E2 | E3 |
F | F1 | F2 | F3 |
Xét nghiệm biểu đồ trên, ta có thể thấy những đặc điểm chính như sau:
Yếu tố [Chữ cái] gồm 6 hạng mục: A,B,C,D,E & F
Yếu tố [Con số] gồm 3 hạng mục: 1, 2 & 3
Đối tượng số liệu biểu đồ này phụ thuộc vào 2 yếu tố chính vừa kể. Vì vậy biểu đồ trên có tổng cộng 18 số liệu đang được xem xét: từ A1,A2,A3… đến F1, F2 và cuối cùng là F3
Đối với 18 số liệu này, ta sẽ cần phải tập hợp chúng lại vào những nhóm lớn để thuận lợi cho việc so sánh. Giữa việc chọn chia ra 3 nhóm hoặc chia ra 6 nhóm, thì một điều mà hầu như ai cũng có thể đồng ý là việc chia ra 3 nhóm sẽ tối ưu hơn, vì những lí do như sau:
Với một số lượng nhóm nhỏ nhưng mỗi nhóm lại bao trùm rất nhiều số liệu, mối quan hệ tương đồng, tương phản sẽ dễ xuất hiện giữa các phần tử hơn trong các nhóm này.
Cũng vì vậy, việc so sánh xảy ra một cách thuận tiện và có sự liên quan, hợp lí hơn vì nó xảy ra trong một phạm trù nhất định. Điều này sẽ tránh được sư lan man, rối mạch. Ví dụ: giả sử một thí sinh đem so sánh A2 với E1 và rồi đem chúng so với B3 (có thể vì chúng có số liệu gần như nhau), sau đó tương phản lại với C1, D3 và F3 – việc này nhìn chung rất mất trật tự và sẽ gây rối cho giám khảo.
Ngoài ra, trong mỗi nhóm lớn, người viết có thể giản lược bớt những số liệu không đáng chú ý và quy chung chúng về một khoảng (range) nhất định (ví dụ: “với số liệu A1, C1, D1 nằm trong khoảng 18-21%”)
Phân tích và tiếp cận dựa trên nguyên tắc
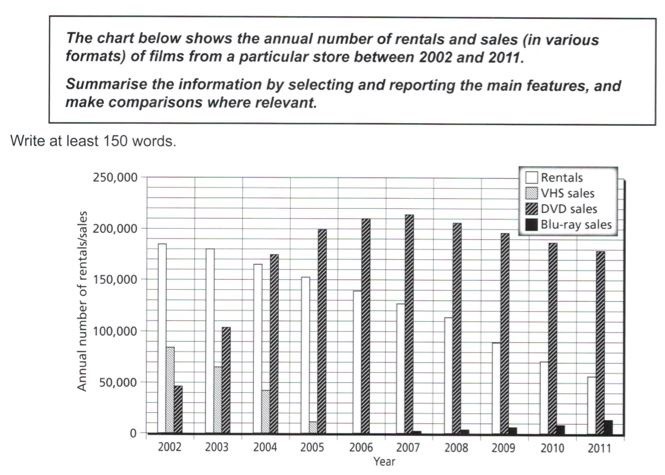
Example 1: Chẳng hạn như biểu đồ mẫu ở đây, khi nhìn vào hình ta sẽ thấy có đầy đủ yếu tố thể loại và yếu tố thời gian. Cụ thể như sau:
Yếu tố thời gian: 3 mốc thời gian 1950 – 1970 – 1990
Yếu tố thể loại: 4 hạng mục Bus, Car, Bike và Foot với các mối quan hệ như sau, dựa trên xu hướng số liệu của chúng:
Mối quan hệ tương đương:
[Bike & Foot] từ 1950 đến 1990
[Bus & Car] từ 1950 đến 1970Mối quan hệ tương phản:
[Bike & Foot] >< [Car] từ 1950 đến 1990
⇒ Có thể làm nổi bật được việc rằng đầu giai đoạn [Foot] là số liệu cao nhất trong khi [Car] lại ngược lại; tuy nhiên cho đến cuối giai đoạn thì [Car] lại là số liệu cao nhất.
[Bus] >< [Car] từ 1970 đến 1990
Thân bài triển khai chi tiết có thể được chia ra hai đoạn như sau:
Body 1: Từ 1950 đến 1990, với dàn ý như sau:
Tương đương: 1950 – [Foot] là số liệu cao nhất, theo sau là [Bike] đứng thứ 2
Tương phản: 1950 – trái lại với 2 loại mục trên, [Car] là số liệu thấp nhất
Tương phản: 1970 – xu hướng [Bike & Foot] trái lại với xu hướng [Car]
Tương đương: 1970 – xu hướng [Bus] giống với xu hướng [Car]
Body 2: Từ 1970 đến 1990, với dàn ý như sau:
Tương phản: 1990 – xu hướng [Bus] trái lại với xu hướng [Car]
Tương phản:
1990 – xu hướng [Car] trái lại với xu hướng [Foot & Bike]
1990- số liệu [Car] ngược lại với số liệu [Bike], so sánh thêm với [Food]
Example 2:
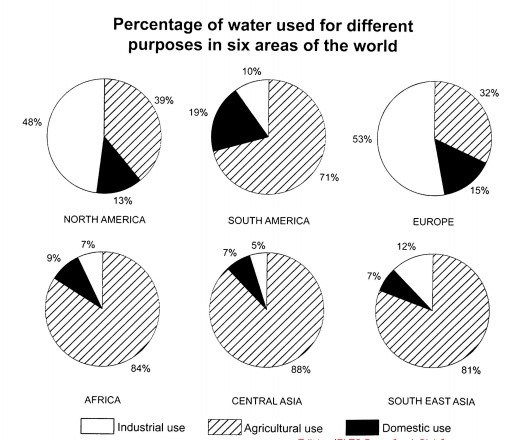
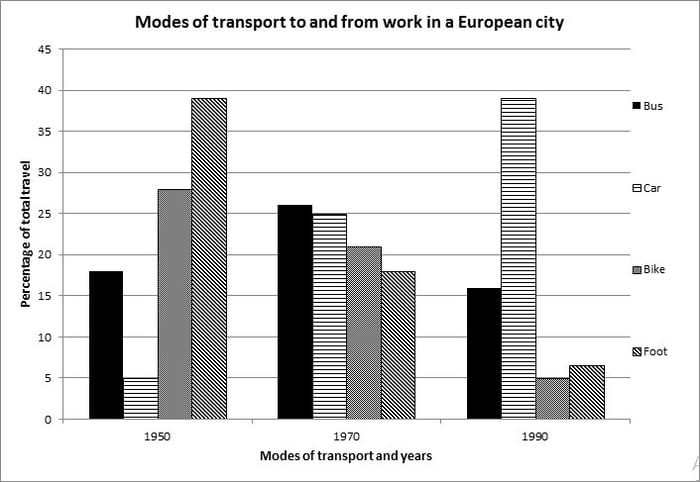
Đối với dạng bài biểu đồ so sánh trên, khi để ý ta sẽ thấy không hề xuất hiện yếu tố thời gian. Yếu tố thể loại ở đây được chia ra làm 2 thể loại phụ:
Thể loại country: 6 loại mục – North America, South America, Europe, Africa, Central Asia và South East Asia
Thể loại use: 3 loại mục – Industrial use, Agricultural use và Domestic use
Thân bài nên được chia ra dựa trên các loại mục use. Đây là dàn bài gợi ý:
Body 1:
Tương đồng: Agricultural Use – [Central Asia], [Africa] và [Southeast Asia]
Tương phản: Industrial Use – [North America, Europe] >< 3 hạng mục country trên
Body 2:
Tương phản: Domestic use – [North America, South America, Europe] >< [Africa, Central Asia & South East Asia]
Có thể làm nổi bật số liệu [North America & Europe] gần như gấp đôi 2 nước Asia. Tình huống tương tự cũng có thể thấy giữa [South America] và [Africa]
Tuỳ thuộc vào số lượng của hai yếu tố thể loại và thời gian, tức là có bao nhiêu hạng mục và có bao nhiêu mốc thời gian, mà người viết có thể dựa vào để chia đoạn. Thông thường, số lượng của yếu tố nào ít hơn thì sẽ được dùng để làm tiêu chí chia đoạn cho bài văn.
Lưu ý 1: Nguyên tắc này chỉ có thể được áp dụng với điều kiện số lượng … của yếu tố thể loại lớn hơn 2. Điều này là đơn giản bởi vì nếu chỉ có 2 … của đối tượng và ta dùng nó để chia ra làm 2 đoạn thân bài, mỗi đoạn thân bài ứng với một đối tượng thì việc so sánh tương quan ở đây rất khó để có thể thực hiện.
Ví dụ: Ở hình bar chart bên cạnh, ta không nên chia một đoạn body dành cho male và đoạn còn lại cho female.
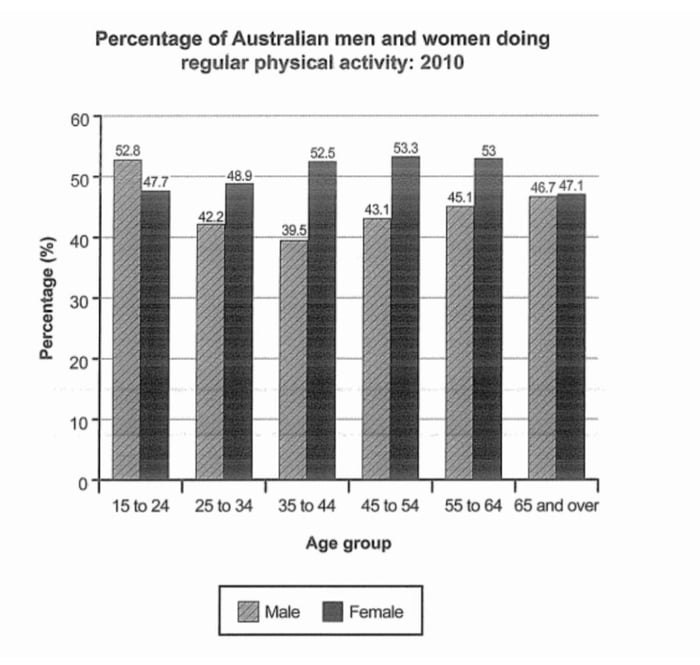
Lưu ý 2: Nguyên tắc này không phải là tuyệt đối.
Ngoại lệ: Trong nhiều trường hợp nhất định, điển hình là trong time chart với nhiều mốc thời gian, ta có thể giản lược và gộp các mốc thời gian, theo trình tự thời gian, thành hai (hoặc 3) giai đoạn nhỏ trong khung thời gian được đưa ra bởi đề.
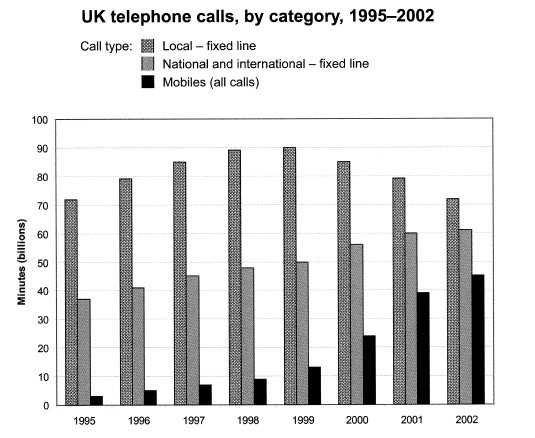
Ví dụ như với biểu đồ bar chart này, ta nhận thấy có 8 mốc thời gian. Tuy nhiên, ta vẫn có thể quy 8 mốc này thành 2 giai đoạn chính như sau:
Giai đoạn 1: Từ 1995 đến 1999
Giai đoạn 2: Từ 1999 đến 2002
Lí do cho việc quy các mốc thời gian thành hai giai đoạn như trên là để có thể áp dụng được nguyên tắc “Less is more” ở trên, đồng thời cũng nhằm làm nổi bật các xu hướng chính của các số liệu. Cụ thể trong biểu đồ mẫu này, ta sẽ để ý thấy những đặc điểm sau:
Giai đoạn 1 (Từ 1995 đến 1999): 3 hạng mục [Local], [National & International] và [Mobiles] đều theo xu hướng tăng (-> mối quan hê tương đồng)
Giai đoạn 2 (Từ 1999 đến 2000): Trong khi cả 2 hạng mục [National & International] và [Mobiles] đều tiếp tục xu hướng tăng của mình, thì [Local] lại bắt đầu giảm (-> mối quan hệ tương phản)
ÁP DỤNG
Bài mẫu 1 – Line graph
Nhận thấy ở trong biểu đồ đường thẳng trên thật sự chỉ có 2 hạng mục – hay là 2 loại đối tượng mà phù hợp cho sự so sánh: Visitors staying on cruise ships và Visitors staying on island.Ta sẽ không so sánh một trong hai loại đối tượng trên với total visitors, đơn giản là vì nó là tổng số của 2 loại này, và một lẽ là số liệu của nó sẽ luôn luôn vượt trội hơn số liệu của hai hạng mục còn lại.
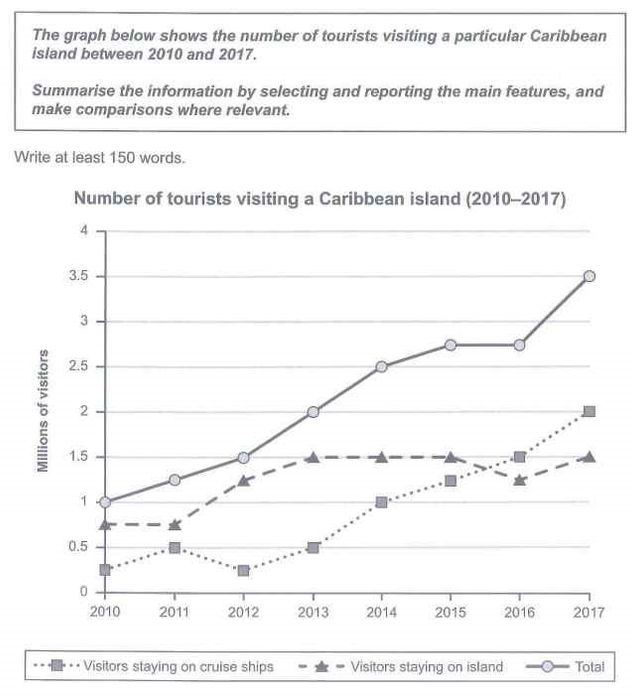
Cách chia thân bài: Một thân bài đầu dành cho total visitors và một thân bài còn lại sẽ dành cho sự so sánh 2 loại Visitors staying on cruise ships và visitors staying on island. Vì số lượng loại mục cho việc so sánh chỉ dừng lại ở 2, ta sẽ chọn yếu tố thời gian làm tiêu chí chia đoạn
Cho đoạn thân bài thứ hai, nhằm mục đích tối ưu hoá sự so sánh, làm nổi bật được mối quan hệ tương phản giữa 2 loại visitor vừa kể, ta sẽ chia việc so sánh (gồm việc mô tả các số liệu và xu hướng) dựa trên mốc thời gian. Cụ thể hơn là phần so sánh sẽ được chia theo hai giai đoạn:
Giai đoạn 1, từ năm 2010 đến năm 2013, với đặc điểm như sau: [Visitors on island] nhìn chung thể hiện xu hướng tăng, trong khi [Visitors on cruise ships] lại dao động đều quanh khoảng 0.25 – 0.5 (-> tương phản)
Ta sẽ mô tả số liệu của [Visitors on island] bắt đầu và cố định ở mức 0.75 (1) và sau đó thể hiện xu hướng tăng (2), trong khi [Visitors on cruise ships] vẫn dao động đều quanh một khoảng(3).
In 2010, roughly 0.75 million visitors chose to stay on island, three times as high as the figure for those staying on cruise ships. Having stabilized until 2011 (1), the number of visitors on island experienced a substantial increase to 1.5 million people in 2013 (2). On the contrary, in the same time span, the figure for holidaymakers on cruise ships fluctuated from 0.25 million to 0.5 million(3).
Giai đoạn 2, từ năm 2013 đến năm 2017, với đặc điểm như sau:
2013 – 2015: Xu hướng tăng của [Visitors on island] đã dừng lại trong 2013 và số liệu của hạng mục này cố định trong những năm tới. Ngược lại, số liệu của [Visitors on cruise ships] lại bắt đầu tăng vào năm 2013. (->tương phản)
2015 – 2017: Nhìn chung, số liệu của [Visitors on island] vẫn cố định ở mức đó, ngoài một lần giảm năm 2016. [Visitors on cruise ships] vẫn tiếp tục xu hướng tăng của nó và vượt qua số liệu của [Visitors on island] giữa năm 2015, sau đó nó vẫn còn tăng cho tới cuối giai đoạn. (->tương phản)
Kết hợp những đặc điểm trên, ta có thể viết rằng [Visitors on island] phần lớn không thay đổi mấy, trừ một sự sụt giảm không đáng kể năm 2016 (4), trong khi đó thì [Visitors on cruise ships] lại bắt đầu xu hướng tăng (5). Sau khi vượt qua [Visitors on island], nó vẫn tiếp tục sự tăng trưởng của cho đến hết giai đoạn (6).
After 2013, however, apart from a marginal drop by 0.25 million in 2016, the number of tourists on island levelled off until the end of the period (4), whereas the figure for holdidaymakers on cruise ships climbed significantly and surpassed its counterpart in mid-2015 (5), whereupon it continued its rise up into 2017 and finished at 2 million people (6).
Bài mẫu 2 – Line graph
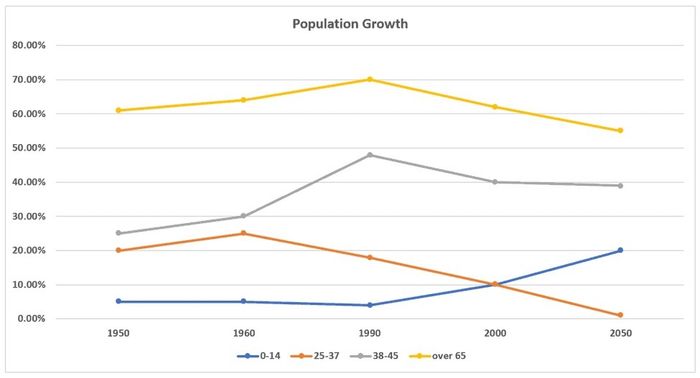
Ta có thể quy 5 mốc thời gian trong biểu đồ trên về 2 giai đoạn và chia đoạn theo tiêu chí thời gian, cụ thể như sau:
Giai đoạn 1, từ năm 1950 đến năm 1990, với những đặc điểm như sau:
1950 – 1960: Số liệu các nhóm [25-37], [38-45] & [over 65] thể hiện xu hướng tăng (-> tương đồng)
1960 – 1990: Số liệu các nhóm [over 65] & [38-45] tiếp tục tăng trong khi nhóm [25-37] lại giảm (-> tương phản).
1950 – 1990: Khác lại với những nhóm trên, nhóm [0-14] xuyên suốt giai đoạn 1 gần như không thay đổi, và là số liệu thấp nhất cho đến giờ (-> tương phản)
In 1950, the vast majority of the New Zealand population were aged over 65, with 60% of the New Zealanders falling into this category, which was significantly higher than the figures for the 38-45, 25-37 age group, at around 25% and 20% respectively. Interestingly, all three previously mentioned categories witnessed a slight increase over the next 10 years (1). However, in 1990, whereas the proportion of people aged between 25 and 37 witnessed a drop to 18%, the figures for the 38-45 and over-65 age group continued their increase, to 48% and 70% respectively (2). Meanwhile, the percentage of people under 14 stabilized at 5% still, remaining the lowest figure hitherto (3).
Giai đoạn 2, từ năm 1990 đến năm 2050, với những đặc điểm như sau:
1990 – 2000 : Số liệu của nhóm [0-14] bắt đầu thể hiện xu hướng tăng, trong khi 3 nhóm còn lại đi theo chiều hướng ngược lại.(-> tương phản)
2000 – 2050: Những xu hướng trên được dự đoán sẽ vẫn tiếp tục trong tương lại. Vẫn là mối quan hệ tương phản giữa [o-14] và 3 nhóm còn lại như trên.
From 1990 onwards, however, the 0-14 age group began to show an upward trend, whereas the remaining categories were subject to the reverse (4). This pattern is expected to continue up into 2050, by which point, the proportion of New Zealanders in the over-65, 38-45 and 25-37 will have dropped to 55%, 40% and 1% respectively. By contrast, the figure for the 0-14 group will rise substantially to finish at 20% (5).
Bài mẫu 3 – Bar chart
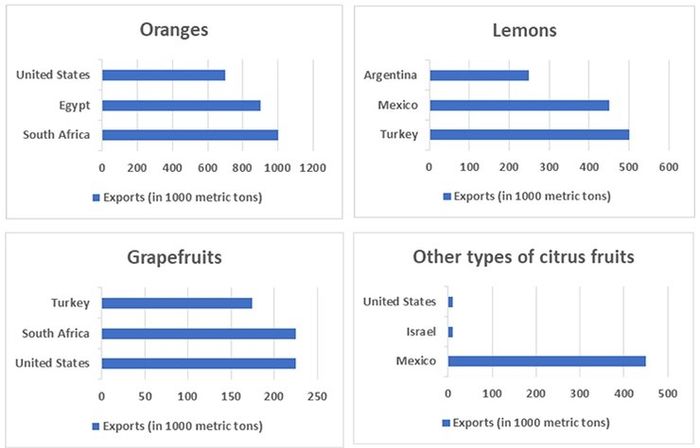
Nhìn vào biểu đồ trên, ta nhận thấy nó là biểu đồ so sánh và không xuất hiện yếu tố thời gian. Tuy nhiên có hai yếu tố thể loại – thể loại trái cây và thể loại đất nước, cụ thể là 4 loại [fruit] so với 8 loại [country].
Dựa theo nguyên tắc “Less is more”, ta sẽ dùng thể loại [fruit] để phân chia và tập hợp hoá các số liệu. Trong thân bài 1, ta sẽ xem xét số liệu dựa trên hai thể loại fruit là {Orange} và {Grape fruits}, dựa trên những đặc điểm như sau:
Đối với {Orange} – loại fruit có số liệu cao nhất, [South Africa] xuất khẩu nhiều nhất trong khi [United States] lại đứng chót trong khoảng này (-> tương phản)
Đối với {Grapefruit} – loại fruit có số liệu thấp, [South Africa] và [United States] xuất khẩu một lượng như nhau. Việc này trái lại với tình huống ở {Orange} như trên (-> tương phản)
Vẫn đang nói về {Grapefruit}, ta có thể mô tả thêm [Turkey] là thấp nhất trong khoảng này để thuận lợi cho việc liên kết với đoạn thân bài sau mà đề cập đến 2 loại fruit còn lại.
Oranges exports were by far the highest, with South Africa exporting 1 million metric tonnes, followed by Egypt and the United States, at 900.000 and 700.000 tonnes respectively (1). However, when it comes to grapefruits, the US exported just as much as South Africa did, sharing a figure of 200.000 metric tons of grapefruit exports (2). In this respect, Turkey trails behind, with only about 175.000 tons (3).
Trong thân bài 2, ta sẽ xem xét số liệu dựa trên hai thể loại fruit còn lại là {Lemons} và {Other types}, dựa trên những đặc điểm như sau:
Đối với {Lemons}, Turkey lại mang số liệu cao nhất, trái ngược lại so với tình huống {Grapefruit} vừa đề cập trước đó (-> tương phản)
Vẫn đang nói về {Grapefruit}, mô tả số liệu của 2 nước còn lại. Tách riêng [Mexico] ra vì nó đặc biệt.
Chuyển sang {Other types}, trong mảng này, Mexico có số liệu cao nhất và số liệu này bằng với số liệu của nó trong mảng {Grapefruit} vừa bàn. (-> tương đồng)
Meanwhile, in terms of lemons export, Turkey was actually the main exporter, shipping half a million metric tons of this fruit overseas, nearly double the exports by Argentina (1). Mexico also contributed a fair amount of lemons exports, at about 450.000 metric tons, which was interestingly the same figure for the export of other citrus fruits from this country (2) & (3). In the latter case, Mexico held the lion’s share of export, which renders the contribution by US and Israel minuscule in comparison.
Bài mẫu 4 – Bar chart
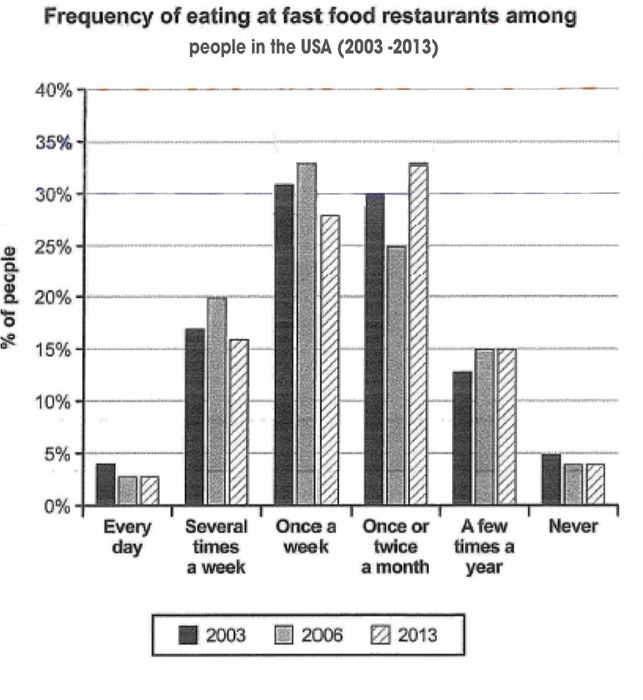
Nhìn vào biểu đồ trên, ta nhận thấy xuất hiện yếu tố thời gian và yếu tố thể loại.
Yếu tố thời gian: 3 mốc thời gian
Yếu tố thể loại: 6 loại frequency
Dựa theo nguyên tắc “Less is more”, ta sẽ dùng yếu tố thời gian để phân chia và tập hợp hoá các số liệu. Dựa trên 3 mốc thời gian được cho, thân bài sẽ được chia thành 2 giai đoạn.
Trước khi chia chi tiết cụ thể cho thân bài, ta sẽ để ý những đặc điểm cụ thể như sau:
Xu hướng của [Once a week] & [Several times a week] (tăng -> giảm) trái ngược lại với [Once or twice a year] (giảm -> tăng).
Xu hướng của [Everyday] & [Never] (giảm -> cố định) ngược lại với xu hướng của [A few times a year] (tăng -> cố định)
⇒ Dựa vào những đặc điểm trên, ta bắt đầu chia thân bài.
Đoạn thân bài 1, từ năm 2003 đến 2006, với các đặc điểm cụ thể như sau:
2003 – [Once a week] & [Once or twice a month] có số liệu đầu giai đoạn cao nhất và gần ngang nhau (->tương đồng).
Sau đó, mô tả thêm [Several times a week] để thuận tiện cho việc so sánh xu hướng sau đó.
2006 – số liệu [Once a week] & [ Severtal times a week] tăng trong khi [Once or twice a month] giảm.
In 2003, the majority of American citizens dined at a fast food restaurant either once a week or from once to twice a month, at 31% and 30% respectively (1). Less common were those eating out with the frequency of several times per week, at 17% (2). Over the next 3 years, weekly diners saw an upward trend, with figures for those eating several times and only once per week rising to 20% and 33% respectively. By contrast, the proportion of US citizens who ate once or twice a month dropped by 5% in the same time span (3).
Đoạn thân bài 2, từ năm 2006 đến 2013, với các đặc điểm cụ thể như sau:
2013 – Tình huống năm 2006 của 3 loại [Once a week], [Several times a week] và [Once or twice a month] đảo ngược lại. [Once a week] & [Several times a week] đi xuống, trong khi [Once or twice a month] đi lên. (-> tương phản)
2013 – Xu hướng [Everyday] & [Never] tương phản với [A few times a year] (-> tương phản). Những nhóm này không đặc sắc nên ta có thể bỏ qua nửa đầu giai đoạn của chúng.
This situation was soon to be reversed in the following 7 years, when the proportion of citizens eating out once or twice a month rose to a high of 33%, which stood in sharp contrast to a decline of 5% seen in both the several-times-a-week diners and once-a-week diners (4). Aside from that, the figures for Americans who never ate out and those who did it on a daily basis also dropped to below 5%, whereas the percentage of those earting out a few times a year increased from 13% to 15% in 2013 (5).