
mô hình Emote Portrait Live đại diện cho một bước tiến quan trọng trong việc chuyển đổi hình ảnh tĩnh thành động.
Các kỹ sư Trung Quốc tại Viện Điện toán Thông minh (IIC) của Alibaba vừa phát triển một ứng dụng AI có tên Emote Portrait Live, có khả năng 'biến đổi' một bức ảnh tĩnh thành hình ảnh có thể nói và hát.
Công nghệ đằng sau mô hình Emote Portrait Live dựa trên khả năng tổng hợp của các mô hình phân tán. Mô hình phân tán là một mô hình toán học được sử dụng để mô tả cách mọi thứ lan truyền hoặc phân tán theo thời gian. Trong trường hợp này, mô hình phân tán được sử dụng để mô tả cách các chuyển động trên khuôn mặt lan truyền từ một điểm xuất phát đến các phần khác của khuôn mặt.
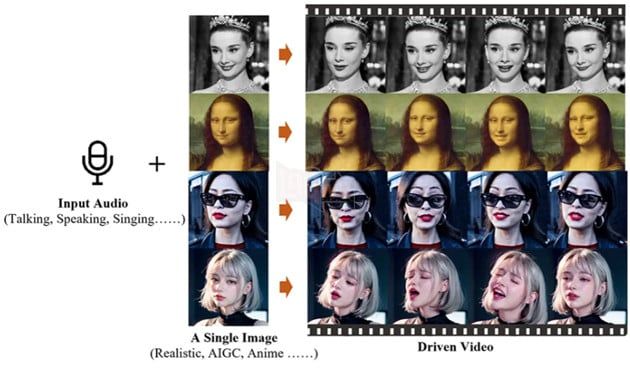
Mô hình Emote Portrait Live sử dụng mô hình phân tán để tổng hợp trực tiếp video đầu nhân vật từ hình ảnh được cung cấp và bất kỳ clip âm thanh nào. Quá trình này loại bỏ nhu cầu xử lý trước phức tạp hoặc biểu diễn trung gian, từ đó giản đơn hóa việc tạo ra video đầu người biết nói.
Mục tiêu của nhóm nghiên cứu là phát triển một khung đầu biết nói có thể nhận diện được nhiều biểu cảm thực tế trên khuôn mặt, bao gồm cả những biểu cảm tinh tế và cho phép chuyển động đầu tự nhiên. Để đạt được điều đó, các nhà nghiên cứu đã tích hợp các cơ chế điều khiển ổn định vào mô hình của họ, bao gồm cả bộ điều khiển tốc độ và bộ điều khiển vùng mặt, nhằm cải thiện độ ổn định trong quá trình tạo ra.

So với các Trí Tuệ Nhân Tạo trước đây chỉ có thể biến đổi miệng và một phần của khuôn mặt, Emote có khả năng tạo ra nét mặt, tư thế, nhíu mày hoặc lắc đầu. Đặc biệt, phần miệng được Trí Tuệ Nhân Tạo tạo ra trông rất tự nhiên.
Trong một số video được công bố bởi Alibaba, hình ảnh sẽ được biến đổi thành video và hát các bài được nhập vào nhanh chóng như bức hoạ Mona Lisa kể lại đoạn độc thoại của Rosalind trong As You Like It, Màn 3, Cảnh 2 của Shakespeare.