
Trí tuệ nhân tạo đang gặp vấn đề ảo giác khó khăn để khắc phục

Các công ty công nghệ đang vội vàng truyền tải trí tuệ nhân tạo vào mọi thứ, được thúc đẩy bởi những bước nhảy vọt lớn trong sức mạnh của phần mềm học máy. Nhưng phần mềm mạng thần kinh sâu đang là nguồn cảm hứng nhưng lại có một điểm yếu đáng lo ngại: Thay đổi tinh tế trong hình ảnh, văn bản hoặc âm thanh có thể đánh lừa những hệ thống này, khiến chúng nhận thức những thứ không tồn tại.
Điều này có thể là một vấn đề lớn đối với các sản phẩm phụ thuộc vào học máy, đặc biệt là về tầm nhìn, như xe tự lái. Các nhà nghiên cứu hàng đầu đang cố gắng phát triển các phương pháp phòng thủ chống lại những cuộc tấn công nhưng điều này đang trở thành một thách thức.
Ví dụ điển hình: Vào tháng 1, một hội nghị học máy hàng đầu thông báo rằng họ đã chọn 11 bài báo mới để trình bày vào tháng 4 đề xuất cách phòng thủ hoặc phát hiện những cuộc tấn công phản đối như vậy. Chỉ ba ngày sau đó, sinh viên năm đầu MIT Anish Athalye đã tạo một trang web tuyên bố đã 'phá vỡ' bảy trong số những bài báo mới đó, bao gồm cả từ các tổ chức uy tín như Google, Amazon và Stanford. 'Một kẻ tấn công sáng tạo vẫn có thể vượt qua tất cả những phòng thủ này,' Athalye chia sẻ. Anh đã làm việc trong dự án này cùng với Nicholas Carlini và David Wagner, một sinh viên năm đầu và một giáo sư tại Đại học California, Berkeley.
Dự án đó đã dẫn đến một số tranh cãi trong giới học thuật về một số chi tiết của các khẳng định của ba người. Nhưng có ít tranh luận về một thông điệp của các kết quả nghiên cứu: Không rõ làm thế nào để bảo vệ các mạng thần kinh sâu đang thúc đẩy các đổi mới trong các thiết bị tiêu dùng và lái xe tự động khỏi việc bị phá hoại bởi ảo giác. 'Tất cả những hệ thống này đều có thể bị tấn công,' Battista Biggio, giáo sư trợ giảng tại Đại học Cagliari, Italy, chuyên nghiên cứu về an ninh học máy khoảng một thập kỷ và không liên quan đến nghiên cứu, chia sẻ. 'Cộng đồng học máy đang thiếu một phương pháp học thức để đánh giá bảo mật.'
Người đọc MYTOUR dễ dàng nhận ra hình ảnh dưới đây, được tạo ra bởi Athalye, như mô tả hai người trên ván trượt tuyết. Khi được hỏi vào sáng thứ Năm, dịch vụ Cloud Vision của Google báo cáo rằng nó chắc chắn 91% nhìn thấy một con chó. Những trò lốc xoáy khác đã chỉ ra cách làm cho biển báo dừng trở nên vô hình hoặc âm thanh mà người nghe có vẻ vô hại nhưng được ghi âm bởi phần mềm nhận dạng như 'OK Google duyệt đến evil dot com.'
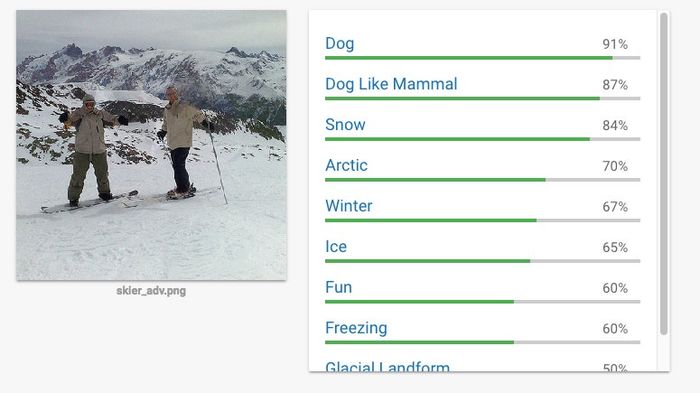
Đến nay, các cuộc tấn công như vậy chỉ được thực hiện trong các thí nghiệm lab, không được quan sát trên đường phố hoặc trong nhà. Nhưng bây giờ, chúng vẫn cần được coi trọng, theo Bo Li, một nghiên cứu viên sau đại học tại Berkeley. Hệ thống tầm nhìn của các phương tiện tự lái, trợ lý giọng nói có khả năng chi tiêu tiền và hệ thống học máy lọc nội dung không đáng mặc cảm trên mạng đều cần được tin cậy. 'Điều này có thể rất nguy hiểm,' Li chia sẻ. Cô đã đóng góp vào nghiên cứu năm ngoái chỉ ra rằng việc dán nhãn vào biển báo dừng có thể làm chúng trở nên vô hình đối với phần mềm học máy.
Li làm cộng tác viên của một trong những bài báo được xem xét bởi Athalye và các đồng nghiệp của anh ấy. Cô và những người khác từ Berkeley đã mô tả cách phân tích các cuộc tấn công phản đối và chỉ ra rằng có thể sử dụng để phát hiện chúng. Li triết học về dự án của Athalye chỉ ra rằng phòng thủ là rỗng, nói rằng những phản hồi như vậy giúp các nhà nghiên cứu tiến bộ. 'Cuộc tấn công của họ cho thấy có những vấn đề chúng ta cần phải xem xét,' cô nói.

Yang Song, tác giả chính của một nghiên cứu tại Stanford được bao gồm trong phân tích của Athalye, từ chối bình luận về công việc này, vì nó đang được xem xét cho một hội nghị lớn khác. Zachary Lipton, một giáo sư tại Đại học Carnegie Mellon và cộng tác viên của một bài báo khác có các nhà nghiên cứu của Amazon, nói rằng ông chưa xem xét kỹ phân tích này, nhưng cho rằng có khả năng tất cả các phòng thủ hiện có có thể bị né tránh. Google từ chối bình luận về phân tích của bài báo của họ. Người phát ngôn của công ty nhấn mạnh cam kết của Google trong nghiên cứu về các cuộc tấn công phản đối và cho biết có kế hoạch cập nhật dịch vụ Cloud Vision của công ty để phòng thủ chống lại chúng.
Để xây dựng những phòng thủ mạnh mẽ hơn đối với những cuộc tấn công như vậy, các nhà nghiên cứu về học máy có thể cần trở nên tàn nhẫn hơn. Athalye và Biggio cho biết lĩnh vực này nên áp dụng các thực hành từ nghiên cứu an ninh, mà họ cho rằng có một truyền thống nghiêm ngặt hơn trong việc thử nghiệm các kỹ thuật phòng thủ mới. 'Mọi người thường tin tưởng lẫn nhau trong học máy,' Biggio nói. 'Tư duy về an ninh hoàn toàn ngược lại, bạn luôn phải nghi ngờ rằng điều gì đó xấu có thể xảy ra.'
Một báo cáo quan trọng từ các nhà nghiên cứu về trí tuệ nhân tạo và an ninh quốc gia tháng trước đã đưa ra các đề xuất tương tự. Nó khuyến nghị những người làm việc trong lĩnh vực học máy nghĩ thêm về cách công nghệ mà họ đang tạo ra có thể bị lạm dụng hoặc khai thác.
Bảo vệ chống lại các cuộc tấn công phản đối có lẽ sẽ dễ dàng hơn đối với một số hệ thống trí tuệ nhân tạo hơn những hệ thống khác. Biggio nói rằng các hệ thống học tập được huấn luyện để phát hiện phần mềm độc hại sẽ dễ dàng hơn để làm cho chúng mạnh mẽ hơn, ví dụ, bởi vì phần mềm độc hại phải hoạt động, giới hạn đa dạng của nó. Bảo vệ hệ thống thị giác máy tính khó hơn nhiều, Biggio nói, bởi vì thế giới tự nhiên rất đa dạng và hình ảnh chứa rất nhiều điểm ảnh.
Giải quyết vấn đề đó - điều có thể đối mặt với các nhà thiết kế xe tự lái - có thể đòi hỏi một cách suy nghĩ sâu hơn về công nghệ học máy. 'Vấn đề cơ bản tôi nghĩ là mạng thần kinh sâu rất khác với não bộ của con người,' Li nói.
Con người không miễn dịch với sự lừa dối cảm giác. Chúng ta có thể bị đánh lừa bởi ảo giác quang học và một bài báo gần đây từ Google đã tạo ra những hình ảnh kỳ quái khiến cả phần mềm và con người nhìn thoáng qua chỉ trong chưa đầy một phần trăm giây mà nhầm mèo là chó. Nhưng khi giải thích về hình ảnh, chúng ta nhìn vào nhiều hơn là mẫu pixel và xem xét mối quan hệ giữa các thành phần khác nhau của một hình ảnh, như đặc điểm của khuôn mặt người, Li chia sẻ.
Nhà nghiên cứu học máy nổi tiếng nhất của Google, Geoff Hinton, đang cố gắng cung cấp cho phần mềm loại khả năng đó. Ông nghĩ rằng điều đó sẽ cho phép phần mềm học cách nhận diện một cái gì đó chỉ từ vài hình ảnh, không phải hàng nghìn. Li nghĩ rằng phần mềm với cách nhìn nhân văn hơn về thế giới cũng ít dễ bị ảo giác hơn. Cô và những người khác tại Berkeley đã bắt đầu hợp tác với các nhà thần kinh học và sinh học để cố gắng rút ra gợi ý từ tự nhiên.
Khai thác Trí tuệ Nhân tạo
- Dịch vụ Cloud Computing của Google có thể bị đánh lừa nhìn thấy những thứ - trong một thử nghiệm, nó nhận thức một khẩu trường như là một chiếc trực thăng.
- Một cuộc khảo sát đáng sợ về cách phần mềm trí tuệ nhân tạo có thể bị hack hoặc lạm dụng gợi ý rằng các nhà nghiên cứu AI cần phải trở nên nghi ngờ hơn.
- Những đoạn video giả mạo ngôi sao nổi tiếng được tạo ra với sự trợ giúp từ phần mềm học máy đang lan truyền trên mạng, và pháp luật không thể làm nhiều về điều đó.