
Trí tuệ nhân tạo hiện đang học hỏi để tiến hóa như các hình thái sống trên Trái Đất

Bài viết này là một phần của đánh giá các bài báo nghiên cứu về trí tuệ nhân tạo, một loạt các bài viết khám phá các phát hiện mới nhất trong trí tuệ nhân tạo.
Trăm triệu năm tiến hóa đã ban tặng cho hành tinh của chúng ta một loạt các hình thái sống đa dạng, mỗi loài thông minh theo cách riêng của nó. Mỗi loài đã tiến hóa để phát triển những kỹ năng bẩm sinh, khả năng học tập và một hình thức vật lý đảm bảo sự tồn tại của nó trong môi trường của mình.
Nhưng mặc dù được truyền cảm hứng từ thiên nhiên và tiến hóa, lĩnh vực trí tuệ nhân tạo chủ yếu tập trung vào việc tạo ra các yếu tố của trí tuệ một cách riêng biệt và kết hợp chúng lại sau khi phát triển. Mặc dù phương pháp này đã mang lại kết quả tuyệt vời, nhưng cũng hạn chế tính linh hoạt của các tác nhân trí tuệ nhân tạo trong một số kỹ năng cơ bản được tìm thấy trong ngay cả các hình thái sống đơn giản nhất.
Trong một bài báo mới được công bố trên tạp chí khoa học Nature, các nhà nghiên cứu trí tuệ nhân tạo tại Đại học Stanford trình bày một kỹ thuật mới có thể giúp vượt qua một số hạn chế này. Với tựa đề “Học tăng cường tiến hóa sâu,” kỹ thuật mới sử dụng môi trường ảo phức tạp và học tăng cường để tạo ra các đại lý ảo có thể tiến hóa cả về cấu trúc vật lý và khả năng học tập của họ. Những phát hiện này có thể có tác động quan trọng đối với tương lai của nghiên cứu trí tuệ nhân tạo và robot.
Tiến hóa khó mô phỏng
 Credit: Ben Dickson / TechTalks
Credit: Ben Dickson / TechTalksTrong tự nhiên, cơ thể và não tiến hóa cùng nhau. Qua nhiều thế hệ, mọi loài động vật đã trải qua vô số chu kỳ đột biến để phát triển chi, cơ quan và hệ thống thần kinh để hỗ trợ các chức năng cần thiết trong môi trường của chúng. Muỗi có thị giác nhiệt để phát hiện nhiệt độ cơ thể. Dơi có cánh để bay và một bộ cơ quan echolocation để di chuyển trong nơi tối. Rùa biển có vây để bơi và một hệ thống phát hiện từ trường để đi rất xa. Con người có tư thế đứng thẳng giúp họ có thể thấy xa hơn, bàn tay và ngón tay linh hoạt có thể điều khiển các vật thể, và một bộ não khiến họ trở thành những sinh vật xã hội và giải quyết vấn đề tốt nhất trên hành tinh.
Thú vị thay, tất cả các loài này đều có nguồn gốc từ sinh vật đầu tiên xuất hiện trên Trái Đất vài tỉ năm trước. Dựa trên áp lực lựa chọn từ môi trường, con cháu của những sinh vật sống đầu tiên đó đã tiến hóa theo nhiều hướng khác nhau.
Nghiên cứu về sự tiến hóa của cuộc sống và trí tuệ là thú vị. Nhưng việc sao chép nó là vô cùng khó khăn. Một hệ thống trí tuệ nhân tạo muốn tái tạo lại cuộc sống thông minh theo cách mà tiến hóa đã làm sẽ phải tìm kiếm một không gian rất lớn của các hình thái có thể có, điều này rất tốn kém tính toán. Nó sẽ cần nhiều chu kỳ thử và sai song song và tuần tự.
Các nhà nghiên cứu trí tuệ nhân tạo sử dụng một số phím tắt và tính năng được thiết kế sẵn để vượt qua một số thách thức này. Ví dụ, họ cố định kiến trúc hoặc thiết kế vật lý của một hệ thống trí tuệ nhân tạo hoặc robot và tập trung vào tối ưu hóa các tham số có thể học được. Một phím tắt khác là việc sử dụng tiến hóa Lamarckian thay vì Darwinian, trong đó các tác nhân trí tuệ nhân tạo truyền các tham số học được của họ cho con cháu. Một cách tiếp cận khác là huấn luyện các phụ hệ trí tuệ nhân tạo khác nhau (thị giác, di chuyển, ngôn ngữ, v.v.) rồi gắn chúng lại với nhau trong một hệ thống trí tuệ nhân tạo hoặc robot cuối cùng. Mặc dù các phương pháp này tăng tốc quá trình và giảm chi phí huấn luyện và tiến hóa các tác nhân trí tuệ nhân tạo, nhưng cũng hạn chế tính linh hoạt và đa dạng của các kết quả có thể đạt được.
Học tăng cường tiến hóa sâu
 Credit: Ben Dickson / TechTalks
Credit: Ben Dickson / TechTalksTrong công trình mới của họ, các nhà nghiên cứu tại Stanford nhằm đưa nghiên cứu trí tuệ nhân tạo gần hơn với quá trình tiến hóa thực sự trong khi vẫn giữ chi phí thấp nhất có thể. “Mục tiêu của chúng tôi là làm sáng tỏ một số nguyên tắc quản lý mối quan hệ giữa sự phức tạp của môi trường, cấu trúc tiến hóa và khả năng học của kiểm soát thông minh,” họ viết trong bài báo của mình.
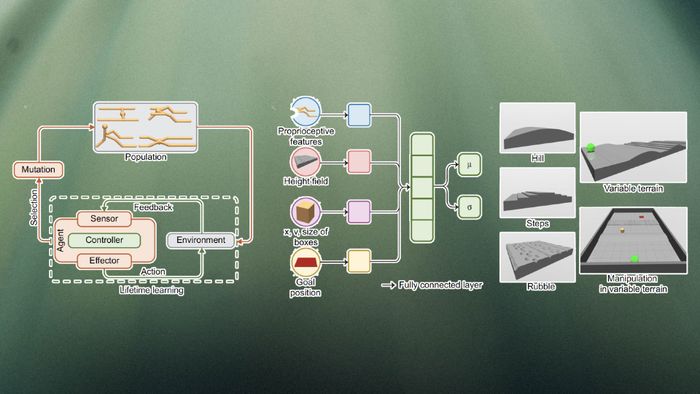
Khung việc của họ được gọi là Deep Evolutionary Reinforcement Learning. Trong DERL, mỗi đại lý sử dụng học tăng cường sâu để học các kỹ năng cần thiết để tối đa hóa mục tiêu của nó trong suốt cuộc đời của mình. DERL sử dụng tiến hóa Darwinian để tìm kiếm không gian hình thái học tối ưu, điều này có nghĩa là khi một thế hệ mới của các đại lý trí tuệ nhân tạo được tạo ra, họ chỉ thừa hưởng các đặc điểm vật lý và kiến trúc của cha mẹ (cùng với các đột biến nhỏ). Không có thông số học được nào được truyền qua các thế hệ.
“DERL mở ra cánh cửa để thực hiện các thí nghiệm in silico quy mô lớn để đem lại những hiểu biết khoa học về cách học và tiến hóa tạo ra mối quan hệ phức tạp giữa sự phức tạp của môi trường, thông minh hình thái và khả năng học nhiệm vụ kiểm soát,” các nhà nghiên cứu viết.
Mô phỏng tiến hóa
Đối với khung việc của họ, các nhà nghiên cứu đã sử dụng MuJoCo, môi trường ảo cung cấp mô phỏng vật lý rắn chính xác cao. Không gian thiết kế của họ được gọi là UNIversal aniMAL (UNIMAL), trong đó mục tiêu là tạo ra hình thái học học di chuyển và nhiệm vụ thao tác đối tượng trong nhiều loại địa hình khác nhau.
Mỗi đại lý trong môi trường bao gồm một gen mô tả chi và khớp của nó. Con cháu trực tiếp của mỗi đại lý kế thừa gen của cha mẹ và trải qua các đột biến có thể tạo ra các chi mới, loại bỏ các chi hiện có, hoặc tạo ra các sửa đổi nhỏ trong các đặc điểm như mức độ tự do hoặc kích thước của chi.
Mỗi đại lý được đào tạo với học tăng cường để tối đa hóa phần thưởng trong các môi trường khác nhau. Nhiệm vụ cơ bản nhất là di chuyển, trong đó đại lý được thưởng cho quãng đường di chuyển trong một tập. Các đại lý có cấu trúc vật lý phù hợp hơn để vượt qua địa hình học nhanh hơn để sử dụng chi để di chuyển xung quanh.
Để kiểm tra kết quả của hệ thống, các nhà nghiên cứu tạo ra các đại lý trên ba loại địa hình: bằng phẳng (FT), biến đổi (VT) và địa hình biến đổi với các đối tượng có thể sửa đổi (MVT). Địa hình bằng phẳng gây ít áp lực lựa chọn nhất lên cấu trúc hình thái của các đại lý. Ngược lại, địa hình biến đổi buộc các đại lý phát triển một cấu trúc vật lý linh hoạt hơn có thể leo dốc và di chuyển xung quanh các chướng ngại vật. Biến thể MVT có thêm thách thức yêu cầu các đại lý tác động vào các đối tượng để đạt được mục tiêu của họ.
Các lợi ích của DERL
 Credit: Ben Dickson / TechTalks
Credit: Ben Dickson / TechTalksMột trong những kết quả thú vị của DERL là sự đa dạng của các kết quả. Các phương pháp tiến hóa trí tuệ nhân tạo khác thường hội tụ vào một giải pháp vì các đại lý mới thừa hưởng trực tiếp cơ thể và kiến thức của cha mẹ. Nhưng trong DERL, chỉ dữ liệu hình thái được truyền cho con cháu, hệ thống kết thúc việc tạo ra một tập hình thái thành công đa dạng, bao gồm loài hai chân, ba chân và bốn chân có và không có cánh tay.
Đồng thời, hệ thống cũng thể hiện những đặc điểm của hiệu ứng Baldwin, ngụ ý rằng các đại lý học nhanh hơn có khả năng sinh sản và truyền gen của họ cho thế hệ kế tiếp. DERL cho thấy rằng tiến hóa 'lựa chọn cho những người học nhanh hơn mà không có áp lực lựa chọn trực tiếp cho việc làm như vậy,' theo bài báo của Stanford.
“Thú vị thay, sự tồn tại của hiệu ứng hình thái Baldwin này có thể được tận dụng trong các nghiên cứu tương lai để tạo ra các đại lý có cơ thể với độ phức tạp mẫu thử thấp và khả năng tổng quát cao hơn,” các nhà nghiên cứu viết.
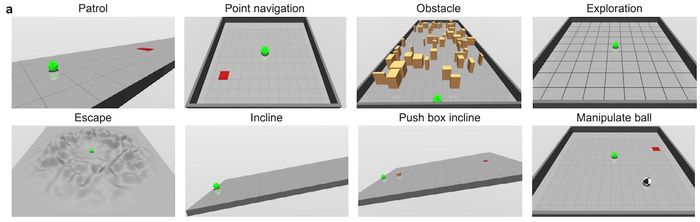 Agents trained in DERL are evaluated across a variety of tasks
Agents trained in DERL are evaluated across a variety of tasksCuối cùng, khung việc của DERL cũng xác nhận giả thuyết rằng môi trường phức tạp hơn sẽ tạo ra các đại lý thông minh hơn. Các nhà nghiên cứu đã kiểm tra các đại lý tiến hóa trên tám nhiệm vụ khác nhau, bao gồm tuần tra, thoát khỏi, thao tác vật thể và khám phá. Các kết quả của họ cho thấy rằng nói chung, các đại lý tiến hóa trong địa hình biến đổi học nhanh hơn và thực hiện tốt hơn so với các đại lý trí tuệ nhân tạo chỉ trải qua địa hình bằng phẳng.
Các kết quả của họ dường như đi theo một giả thuyết của các nhà nghiên cứu DeepMind khác rằng môi trường phức tạp, cấu trúc thưởng phù hợp và học tăng cường cuối cùng có thể dẫn đến sự xuất hiện của mọi loại hành vi thông minh.
Nghiên cứu trí tuệ nhân tạo và robot
Môi trường DERL chỉ có một phần nhỏ của sự phức tạp của thế giới thực. “Mặc dù DERL cho phép chúng ta tiến một bước quan trọng trong việc mở rộng sự phức tạp của môi trường tiến hóa, một hướng nghiên cứu quan trọng trong tương lai sẽ liên quan đến thiết kế các môi trường tiến hóa mở, thực tế về mặt vật lý và đa tác nhân hơn,” các nhà nghiên cứu viết.
Trong tương lai, các nhà nghiên cứu sẽ mở rộng phạm vi các nhiệm vụ đánh giá để đánh giá tốt hơn cách mà các đại lý có thể nâng cao khả năng học các hành vi liên quan đến con người.
Công việc này có thể có tác động quan trọng đối với tương lai của trí tuệ nhân tạo và robot và thúc đẩy các nhà nghiên cứu sử dụng các phương pháp khám phá tương tự tiến hóa tự nhiên hơn nhiều.
“Chúng tôi hy vọng công việc của mình sẽ khuyến khích các cuộc khám phá quy mô lớn khác về học tập và tiến hóa trong các ngữ cảnh khác để đem lại những hiểu biết khoa học mới về sự xuất hiện của các hành vi thông minh có thể học nhanh, cũng như những tiến bộ kỹ thuật mới trong khả năng thiết lập chúng trong các máy móc,” các nhà nghiên cứu viết.
This article was originally published by Ben Dickson on TechTalks, a publication that examines trends in technology, how they affect the way we live and do business, and the problems they solve. But we also discuss the evil side of technology, the darker implications of new tech, and what we need to look out for. You can read the original article here.