
Trong di truyền học, một trình tự axit nucleic, trình tự ADN hay trình tự di truyền là chuỗi các ký tự liên tiếp để diễn tả cấu trúc chính của một đoạn hoặc phân tử ADN thực hoặc tổng hợp, có khả năng chứa thông tin về gen và di truyền.
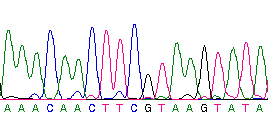
Để phân biệt bốn loại nucleotide, người ta sử dụng 4 ký tự: A, X (ở Việt Nam, chữ C thường thấy trong tài liệu tiếng Anh), G, và T tương ứng với các gốc Adenin, Xitosin (Cytosine), Guanin, Timin liên kết với mạch chính phosphor. Thông thường, các chuỗi được ghi liền không có khoảng trống (gap), ví dụ chuỗi AAAGTXTGAX từ đầu 5' đến 3' tính từ trái sang phải. Nếu có khoảng trống, ký hiệu gạch ngang (-) được sử dụng, ví dụ ATX-G--X. Bất kỳ chuỗi nucleotide dài hơn 4 ký tự đều có thể gọi là trình tự ADN. Tùy thuộc vào chức năng sinh học và ngữ cảnh, một trình tự có thể mang mã hoặc không (noncoding DNA). Các trình tự ADN cũng có thể chứa 'DNA rác' (junk DNA).
Việc xác định trình tự DNA là cốt lõi của dự án bản đồ gen người. Các trình tự/chuỗi này có thể được trích xuất từ dữ liệu thô trong sinh học thông qua quá trình gọi là Phương pháp sắp xếp chuỗi DNA (DNA sequencing).
Trong một số trường hợp, chuỗi có thể chứa các ký tự khác ngoài A, T, X, và G. Những ký tự này đại diện cho sự không xác định rõ ràng, có nghĩa là tại vị trí đó có thể xuất hiện nhiều loại nucleotide khác nhau. Đây là quy ước của Hiệp hội Hóa học Thuần túy và Hóa học Ứng dụng Quốc tế (IUPAC - International Union of Pure and Applied Chemistry):
A = adenin
C = cytosin
G = guanin
T = timin
R = G A (purine)
Y = T C (pyrimidine)
K = G T (keto)
M = A C (amino)
S = G C (liên kết mạnh)
W = A T (liên kết yếu)
B = G T C (tất cả trừ A)
D = G A T (tất cả trừ C)
H = A C T (tất cả trừ G)
V = G C A (tất cả trừ T)
N = A G C T (bất kỳ)- Di truyền học
- DNA
- DNA motif
- Đa hình nucleotide đơn (SNP)
^ http://seqcore.brcf.med.umich.edu/doc/educ/dnapr/sequencing.html Lưu trữ 2008-01-07 tại Wayback Machine