
Xây dựng ứng dụng với GPT-3? Đây là những điều mà nhà phát triển cần biết về chi phí và hiệu suất

Tuần trước, OpenAI đã loại bỏ danh sách chờ cho giao diện lập trình ứng dụng đối với GPT-3, mô hình ngôn ngữ mạnh mẽ của họ. Bây giờ, bất kỳ nhà phát triển nào đáp ứng các điều kiện sử dụng OpenAI API đều có thể đăng ký và bắt đầu tích hợp GPT-3 vào ứng dụng của họ.
Kể từ khi phát hành beta của GPT-3, các nhà phát triển đã xây dựng hàng trăm ứng dụng trên cơ sở của mô hình ngôn ngữ này. Nhưng xây dựng sản phẩm GPT-3 thành công mang lại những thách thức độc đáo. Bạn phải tìm cách tận dụng sức mạnh của các mô hình học sâu tiên tiến của OpenAI để cung cấp giá trị tốt nhất cho người dùng của bạn trong khi giữ cho hoạt động của bạn co giãn và hiệu quả chi phí.
May mắn thay, OpenAI cung cấp nhiều tùy chọn có thể giúp bạn tận dụng tốt nhất nguồn tiền của mình khi sử dụng GPT-3. Dưới đây là những gì những người đã phát triển ứng dụng với GPT-3 muốn chia sẻ về các thực hành tốt nhất.
Mô hình và mã thông báo
 OpenAI provides GPT-3 in different sizes, prices, and performance levels.
OpenAI provides GPT-3 in different sizes, prices, and performance levels.OpenAI cung cấp bốn phiên bản của GPT-3: Ada, Babbage, Curie và Davinci. Ada là mô hình nhanh nhất, rẻ nhất và hiệu suất thấp nhất. Davinci là mô hình chậm nhất, đắt nhất và hiệu suất cao nhất. Babbage và Curie nằm ở giữa hai đỉnh cực.
TNW Conference 2024 - Mời tất cả các Startup tham gia vào ngày 20-21 tháng 6
Trình bày Startup của bạn trước các nhà đầu tư, những người thay đổi và khách hàng tiềm năng với các gói Startup được tổ chức của chúng tôi.
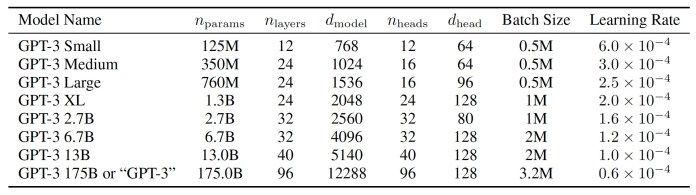
Trang web của OpenAI không cung cấp chi tiết kiến trúc về từng mô hình, nhưng bài báo GPT-3 gốc bao gồm một danh sách các phiên bản khác nhau của mô hình ngôn ngữ. Sự khác biệt chính giữa các mô hình là số lượng tham số và lớp, từ 12 lớp và 125 triệu tham số đến 96 lớp và 175 tỷ tham số. Thêm lớp và tham số cải thiện khả năng học của mô hình nhưng cũng tăng thời gian xử lý và chi phí.
OpenAI tính giá cho các mô hình của mình dựa trên tokens. Theo OpenAI, “một token thường tương đương với ~4 ký tự văn bản tiếng Anh thông thường. Điều này tương đương với khoảng ¾ từ (vì vậy 100 tokens ≈ 75 từ).”
Dưới đây là một ví dụ từ công cụ Tokenizer của OpenAI:
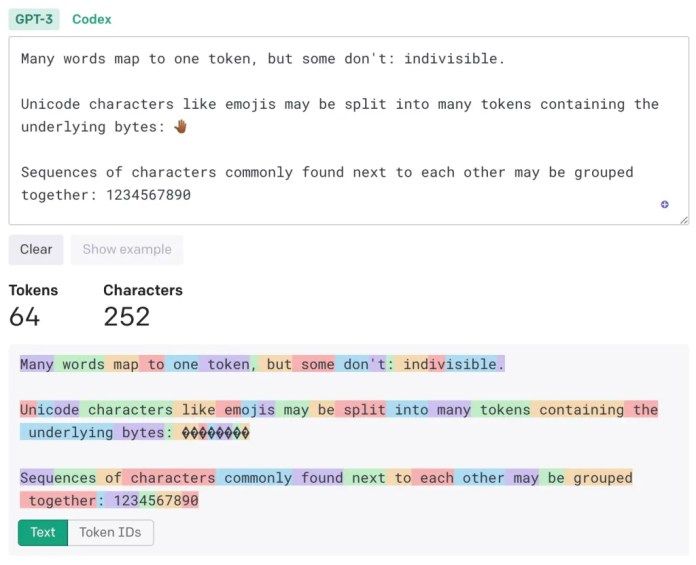 Example of tokenized text
Example of tokenized textNói chung, nếu bạn sử dụng tiếng Anh tốt (tránh ngôn ngữ chuyên môn, sử dụng từ đơn với ít âm tiết, v.v.), bạn sẽ có tỷ lệ token-to-word tốt hơn. Trong ví dụ dưới đây, ngoại trừ từ “GPT-3,” mọi từ khác đều tính là một token.
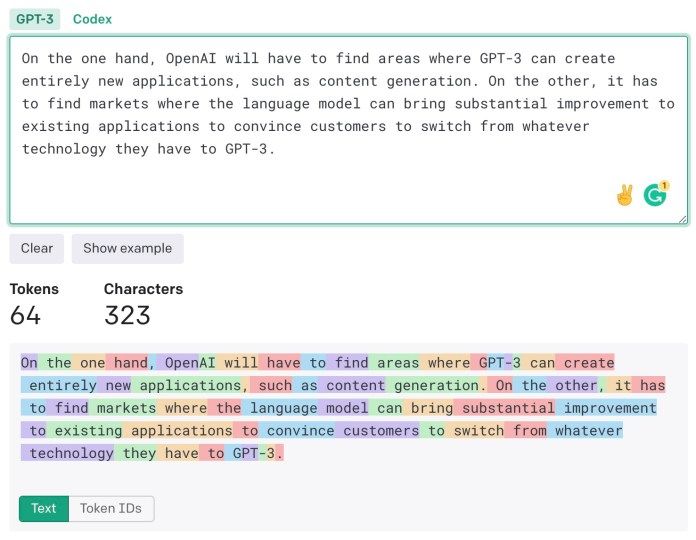
Một trong những lợi ích của GPT-3 là khả năng học few-shot. Nếu bạn không hài lòng với phản hồi của mô hình đối với một đầu vào, bạn có thể hướng dẫn nó bằng cách cung cấp một đầu vào dài hơn chứa các ví dụ chính xác. Những ví dụ này sẽ hoạt động như việc đào tạo thời gian thực và cải thiện kết quả của GPT-3 mà không cần điều chỉnh lại các tham số.
Lưu ý rằng OpenAI tính phí bạn dựa trên tổng số tokens trong đầu vào cũng như số tokens đầu ra mà GPT-3 trả về. Do đó, các đầu vào dài với ví dụ học few-shot sẽ tăng chi phí khi sử dụng GPT-3.
Mô hình nào bạn nên sử dụng?
Với sự chênh lệch chi phí 75 lần giữa mô hình GPT-3 rẻ nhất và đắt nhất, quan trọng là biết lựa chọn nào phù hợp nhất với ứng dụng của bạn.
Matt Shumer, người sáng lập và CEO của OthersideAI, đã sử dụng GPT-3 để phát triển các công cụ viết có trí tuệ nhân tạo. HyperWrite, sản phẩm chính của OthersideAI, sử dụng GPT-3 cho việc tạo văn bản, tự động hoàn thiện, và diễn đạt lại ý.
Khi lựa chọn giữa các mô hình GPT-3 khác nhau, Shumer bắt đầu bằng cách xem xét sự phức tạp của trường hợp sử dụng dự kiến, anh ta cho biết trên TechTalks.
“Nếu nó là điều gì đó đơn giản, như phân loại nhị phân, tôi có thể bắt đầu với Ada hoặc Babbage. Nếu nó là điều rất phức tạp, như tạo điều kiện nơi đầu ra chất lượng cao và đáng tin cậy là cần thiết, tôi bắt đầu với Davinci,” anh ta nói.
Khi không chắc về độ phức tạp, Shumer bắt đầu bằng cách thử mô hình lớn nhất, Davinci. Sau đó, anh ta làm việc theo hướng từ trên xuống về các mô hình nhỏ hơn.
“Khi tôi làm việc với Davinci, tôi thử điều chỉnh đầu vào để sử dụng Curie. Thông thường điều này có nghĩa là thêm nhiều ví dụ hơn, làm rõ cấu trúc, hoặc cả hai. Nếu nó hoạt động trên Curie, tôi chuyển sang Babbage, sau đó là Ada,” anh ta nói.
Đối với một số ứng dụng, anh ta sử dụng hệ thống đa bước bao gồm sự kết hợp của các mô hình khác nhau.
“Ví dụ, nếu đó là một nhiệm vụ tạo sinh đòi hỏi một số phân loại như một bước tiên điều, tôi có thể sử dụng Babbage cho phân loại, sau đó là Curie hoặc Davinci cho bước tạo sinh,” anh ta nói. “Sau một thời gian sử dụng, bạn có cảm giác về những gì có thể hữu ích cho các trường hợp sử dụng khác nhau.”
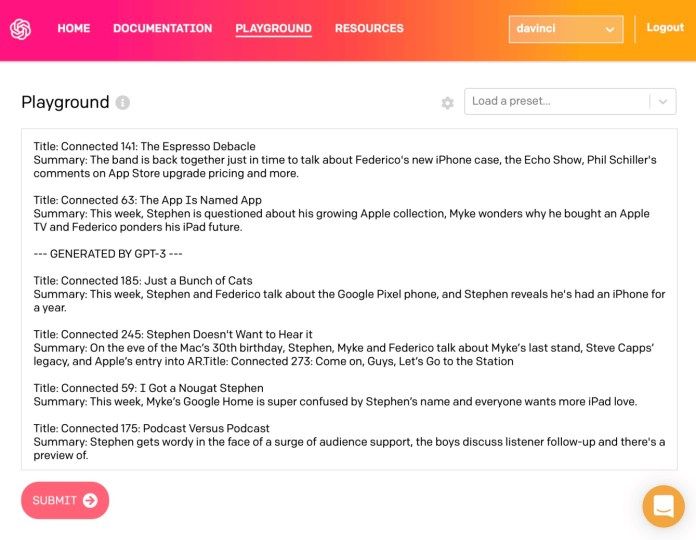 OpenAI’s Playground lets you directly try prompts on different GPT-3 models
OpenAI’s Playground lets you directly try prompts on different GPT-3 modelsPaul Bellow, tác giả và nhà phát triển của LitRPG Adventures, đã sử dụng Davinci cho trình tạo nội dung RPG của mình được động lực từ GPT-3.
“Tôi muốn tạo ra đầu ra chất lượng cao nhất có thể—để sau này điều chỉnh chi tiết,” Bellow nói với TechTalks. “Davinci là mô hình chậm nhất và đắt nhất, nhưng đối thoại là đầu ra chất lượng cao hơn, điều quan trọng với tôi ở giai đoạn này của quá trình phát triển. Tôi đã chi trả một giá cao, nhưng bây giờ tôi có hơn 10,000 thế hệ mà tôi có thể sử dụng cho việc điều chỉnh chi tiết trong tương lai. Bộ dữ liệu có giá trị.” (Thêm về điều chỉnh chi tiết sau.)
Bellow cho biết cách tốt nhất để xem xét xem mô hình khác có thể hoạt động cho một nhiệm vụ là chạy một số bài kiểm tra trên Playground, một công cụ bạn có thể sử dụng để trực tiếp thử các câu nhắc trên các mô hình GPT-3 khác nhau (lưu ý rằng OpenAI tính phí cho việc sử dụng Playground).
“Rất nhiều lúc, một câu nhắc được suy nghĩ cẩn thận có thể đưa ra nội dung tốt từ mô hình Curie. Mọi thứ chỉ phụ thuộc vào trường hợp sử dụng,” Bellow nói.
Cân bằng giữa chi phí và chất lượng
Khi chọn một mô hình cho ứng dụng của bạn, bạn sẽ phải cân nhắc giữa chi phí và giá trị. Việc chọn một mô hình có hiệu suất cao có thể cung cấp đầu ra chất lượng tốt hơn, nhưng kết quả cải thiện có thể không chứng minh đáng giá sự khác biệt về giá cả.
“Bạn phải xây dựng một mô hình kinh doanh xung quanh sản phẩm của bạn hỗ trợ các động cơ bạn đang sử dụng,” Shumer nói. “Nếu bạn muốn đầu ra chất lượng cao cho người dùng của mình, việc sử dụng Davinci sẽ đáng giá—bạn có thể chuyển gánh chi phí cho người dùng của mình. Nếu bạn muốn xây dựng một sản phẩm miễn phí quy mô lớn, và người dùng của bạn chấp nhận kết quả trung bình, bạn có thể sử dụng một động cơ nhỏ hơn. Tất cả phụ thuộc vào mục tiêu sản phẩm của bạn.”
OthersideAI đã phát triển một giải pháp sử dụng sự kết hợp của các mô hình GPT-3 khác nhau để hỗ trợ các trường hợp sử dụng khác nhau, Shumer cho biết. Người dùng trả phí tận hưởng sức mạnh của các mô hình GPT-3 lớn, trong khi người dùng bản miễn phí có quyền truy cập các mô hình nhỏ hơn.
Đối với LitRPG Adventures, chất lượng là ưu tiên hàng đầu, đó là lý do Bellow ban đầu duy trì mô hình Davinci. Anh ấy đã sử dụng mô hình Davinci cơ bản với các nhắc một hoặc hai lần, điều này làm tăng chi phí nhưng đảm bảo GPT-3 cung cấp đầu ra chất lượng.
“Mô hình Davinci của OpenAI API có chi phí hơi cao vào thời điểm này, nhưng tôi thấy chi phí sẽ giảm dần,” anh ấy nói. “Điều cung cấp tính linh hoạt ngay bây giờ là khả năng điều chỉnh lại các mô hình Curie và thấp hơn, hoặc Davinci với sự cho phép. Điều này sẽ giảm chi phí mỗi thế hệ của tôi một cách đáng kể trong khi hy vọng duy trì chất lượng cao.”
Anh ấy đã có thể phát triển một mô hình kinh doanh duy trì lợi nhuận khi sử dụng Davinci.
“Mặc dù không phải là một nguồn thu nhập lớn, dự án LitRPG Adventures đang tự trả chi phí và sắp sẵn sàng để mở rộng,” anh ấy nói.
Feinetuning GPT-3
Những nhà khoa học của OpenAI ban đầu giới thiệu GPT-3 như một mô hình ngôn ngữ không phụ thuộc vào nhiệm vụ. Theo các thử nghiệm ban đầu của họ, GPT-3 ngang tầm với các mô hình hiện đại trên các nhiệm vụ cụ thể mà không cần đào tạo thêm. Nhưng họ cũng đề cập đến việc điều chỉnh lại là một “hướng làm việc tương lai triển vọng.”
Trong những tháng tiếp theo sau phiên bản beta của GPT-3, OpenAI và Microsoft đã điều chỉnh mô hình cho nhiều nhiệm vụ khác nhau, bao gồm truy vấn cơ sở dữ liệu và tạo mã nguồn.
Giống như các kiến trúc học sâu khác, việc điều chỉnh lại mang lại nhiều lợi ích cho GPT-3. OpenAI API cho phép khách hàng tạo các phiên bản được điều chỉnh lại của GPT-3 với một chi phí cao cấp. Bạn có thể tạo bộ dữ liệu đào tạo riêng của mình, tải lên máy chủ của OpenAI và sử dụng nó để tạo mô hình được điều chỉnh lại của GPT-3. OpenAI sẽ lưu trữ mô hình của bạn và làm cho nó có sẵn cho bạn thông qua API của mình.
Việc điều chỉnh lại sẽ giúp bạn giải quyết các vấn đề mà các mô hình cơ bản không thể giải quyết được.
“Các mô hình vanilla rất có khả năng và có thể sử dụng cho nhiều nhiệm vụ. Tuy nhiên, một số nhiệm vụ (ví dụ: tạo ra đa bước) quá phức tạp đối với một mô hình vanilla, thậm chí là Davinci, để hoàn thành với độ chính xác cao,” Shumer nói. “Trong những trường hợp như vậy, bạn có hai lựa chọn: 1) tạo một chuỗi nhắc lệnh cung cấp đầu ra từ một nhắc lệnh vào một nhắc lệnh khác, hoặc 2) điều chỉnh lại một mô hình. Thông thường, tôi thử trước để tạo một chuỗi nhắc lệnh, và nếu điều đó không thành công, tôi sau đó chuyển sang việc điều chỉnh lại.”
Nếu thực hiện đúng cách, việc điều chỉnh lại cũng có thể giảm chi phí sử dụng GPT-3. Nếu bạn sẽ sử dụng GPT-3 cho một ứng dụng cụ thể, một mô hình nhỏ được điều chỉnh lại có thể tạo ra kết quả tốt như mô hình vanilla lớn. Các mô hình được điều chỉnh lại cũng giảm kích thước của nhắc lệnh, giảm sử dụng token của bạn thêm nữa.
“Một trường hợp khác nơi tôi thường xuyên điều chỉnh lại là khi tôi có thể có một cái gì đó hoạt động với một mô hình vanilla, nhưng nhắc lệnh kết thúc dài quá mức có chi phí để cung cấp cho người dùng. Trong những trường hợp như thế này, tôi điều chỉnh lại, vì thực tế nó có thể giảm tổng chi phí phục vụ,” Shumer nói.
Nhưng việc điều chỉnh lại không phải là không thách thức. Nếu không có một bộ dữ liệu đào tạo chất lượng, việc điều chỉnh lại có thể gây ra tác động tiêu cực.
“Làm sạch bộ dữ liệu của bạn càng nhiều càng tốt. Rác vào, rác ra là một trong những nguyên tắc quan trọng của tôi khi nói đến kỹ thuật nhắc lệnh,” Bellow nói.
Nếu bạn thành công trong việc thu thập một bộ dữ liệu lớn với những ví dụ chất lượng, việc điều chỉnh lại có thể tạo ra kỳ diệu. Sau khi bắt đầu LitRPG với mô hình Davinci, Bellow đã thu thập và làm sạch một bộ dữ liệu khoảng 4,000 mẫu trong một tệp JSON có dung lượng 7 megabyte. Mặc dù anh ấy vẫn đang thử nghiệm, kết quả ban đầu cho thấy anh ấy có thể chuyển từ Davinci sang Curie mà không có sự thay đổi đáng kể về chất lượng, giảm chi phí truy vấn GPT-3 đi 90%.
Một điều cần xem xét khác là thời gian để điều chỉnh lại GPT-3, thời gian này tăng lên theo kích thước của mô hình và bộ dữ liệu đào tạo.
“Nó có thể mất chỉ vài phút để điều chỉnh lại một mô hình nhỏ trên vài trăm ví dụ,” Shumer nói. “Tôi cũng đã thấy các trường hợp mất nhiều hơn năm giờ để đào tạo một mô hình lớn trên hàng nghìn ví dụ.”
Cũng có một mối tương quan nghịch giữa kích thước của mô hình và lượng dữ liệu bạn cần để điều chỉnh lại GPT-3, theo các thử nghiệm của Shumer. Các mô hình lớn yêu cầu ít dữ liệu hơn cho việc điều chỉnh lại.
“Đối với nhiều nhiệm vụ, bạn có thể nghĩ đến việc tăng kích thước của mô hình cơ bản như một cách để giảm lượng dữ liệu bạn cần để điều chỉnh lại một mô hình chất lượng,” Shumer nói. “Một Curie được điều chỉnh lại với 100 ví dụ có thể có kết quả tương tự như một Babbage được điều chỉnh lại với 2,000 ví dụ. Các mô hình lớn có thể thực hiện những điều đáng kinh ngạc với rất ít dữ liệu.”
Các lựa chọn thay thế cho GPT-3
OpenAI đã nhận được nhiều ý kiến phản đối về quyết định không phát hành GPT-3 dưới dạng mô hình mã nguồn mở. Sau đó, các nhà phát triển khác đã phát hành các lựa chọn thay thế cho GPT-3 và làm chúng có sẵn cho công chúng. Một dự án rất phổ biến là GPT-J của EleutherAI. Giống như các dự án mã nguồn mở khác, GPT-J đòi hỏi nỗ lực kỹ thuật từ phía các nhà phát triển ứng dụng để thiết lập và chạy. Nó cũng không có lợi ích từ sự thuận tiện sử dụng và khả năng mở rộng mà đi kèm khi lưu trữ và điều chỉnh mô hình của bạn trên đám mây Azure của Microsoft.
Tuy nhiên, các mô hình mã nguồn mở vẫn hữu ích và đáng xem xét nếu bạn có đội ngũ nhân sự có kỹ năng để thiết lập chúng và chúng đáp ứng yêu cầu của ứng dụng của bạn.
“GPT-J không giống như GPT-3 toàn diện—nhưng nó hữu ích nếu bạn biết cách làm việc với nó. Việc đặt một nhắc lệnh phức tạp vào GPT-J khó hơn rất nhiều so với Davinci, nhưng có thể thực hiện được đối với hầu hết các trường hợp sử dụng,” Shumer nói. “Bạn sẽ không nhận được cùng một chất lượng siêu cao, nhưng bạn có thể đạt được một cái gì đó chấp nhận được với một thời gian và công sức. Ngoài ra, những mô hình này có thể rẻ hơn để vận hành, đó là một điểm cộng lớn, xét đến chi phí của Davinci. Chúng tôi đã thành công sử dụng các mô hình như thế này tại Otherside.”
“Theo trải nghiệm của tôi, chúng hoạt động ở mức độ của mô hình Curie từ OpenAI,” Bellow nói. “Tôi cũng đã tìm hiểu về Cohere AI, nhưng họ không cung cấp chi tiết về kích thước của mô hình của họ, nên tôi tưởng tượng nó sẽ xấp xỉ GPT-J, vv. Tôi nghĩ (hy vọng) sẽ có thêm nhiều lựa chọn từ các đối thủ khác trong tương lai. Sự cạnh tranh giữa nhà cung cấp là điều tốt đẹp cho người tiêu dùng như tôi.”
Bài viết này ban đầu được xuất bản bởi Ben Dickson trên TechTalks, một xu hướng kiểm tra công nghệ, cách chúng ảnh hưởng đến cách chúng ta sống và kinh doanh, cũng như những vấn đề chúng giải quyết. Nhưng chúng tôi cũng thảo luận về mặt tối của công nghệ, những hậu quả tối tăm của công nghệ mới và điều chúng ta cần phải đề phòng. Bạn có thể đọc bài viết gốc tại đây.