

Sau khi tìm hiểu về lịch sử và thông tin cơ bản về dòng vi xử lý Xeon dành cho máy chủ, phần này chúng ta sẽ đi sâu vào phân tích chi tiết thiết kế bên trong của Intel Xeon 6900P, kiến trúc, hiệu năng và các nhận xét tổng quan.
Intel không chỉ khác AMD trong cách sử dụng chiplet, mà còn có một cách tiếp cận hoàn toàn khác với cấu trúc từng die. Trong khi CCD của AMD chỉ đơn giản là các nhân xử lý và bộ đệm, die compute của Intel còn tích hợp cả bộ điều khiển bộ nhớ (IMC). Hơn nữa, với số lượng nhân xử lý rất lớn (ít nhất là 16 nhân), Intel sắp xếp chúng theo dạng lưới (mesh) liên kết như ma trận. Tuy nhiên, công ty chưa công bố sơ đồ die compute nên chưa rõ cấu hình cụ thể (4x4, 8x2, 16x4 hay 8x8).
Điểm đặc biệt cần lưu ý là mỗi die compute sẽ nhận trực tiếp dữ liệu từ bộ nhớ RAM thông qua IMC có sẵn, thay vì thông qua die I/O như trên các vi xử lý của AMD. Điều này lý thuyết sẽ giúp Intel kiểm soát tốt hơn vấn đề bộ nhớ, trong khi tốc độ truy cập RAM của AMD lại bị phụ thuộc vào tốc độ Infinity Fabric. Hỗ trợ bộ nhớ MRDIMM với băng thông lên tới 8800 MT/s chính là kết quả của thiết kế này (trong khi AMD vẫn tối ưu với DDR5-6000). Die compute Granite Rapids được sản xuất trên tiến trình Intel 3, gần như là công nghệ mới nhất của Intel (Intel 18A đang được dùng để sản xuất Clearwater Forest, nhưng là sản phẩm của năm sau).
Die compute và die I/O
Intel không chỉ khác AMD trong cách sử dụng chiplet, mà còn có một cách tiếp cận hoàn toàn khác với cấu trúc từng die. Trong khi CCD của AMD chỉ đơn giản là các nhân xử lý và bộ đệm, die compute của Intel còn tích hợp cả bộ điều khiển bộ nhớ (IMC). Hơn nữa, với số lượng nhân xử lý rất lớn (ít nhất là 16 nhân), Intel sắp xếp chúng theo dạng lưới (mesh) liên kết như ma trận. Tuy nhiên, công ty chưa công bố sơ đồ die compute nên chưa rõ cấu hình cụ thể (4x4, 8x2, 16x4 hay 8x8).
Điểm đặc biệt cần lưu ý là mỗi die compute sẽ nhận trực tiếp dữ liệu từ bộ nhớ RAM thông qua IMC có sẵn, thay vì thông qua die I/O như trên các vi xử lý của AMD. Điều này lý thuyết sẽ giúp Intel kiểm soát tốt hơn vấn đề bộ nhớ, trong khi tốc độ truy cập RAM của AMD lại bị phụ thuộc vào tốc độ Infinity Fabric. Hỗ trợ bộ nhớ MRDIMM với băng thông lên tới 8800 MT/s chính là kết quả của thiết kế này (trong khi AMD vẫn tối ưu với DDR5-6000). Die compute Granite Rapids được sản xuất trên tiến trình Intel 3, gần như là công nghệ mới nhất của Intel (Intel 18A đang được dùng để sản xuất Clearwater Forest, nhưng là sản phẩm của năm sau).
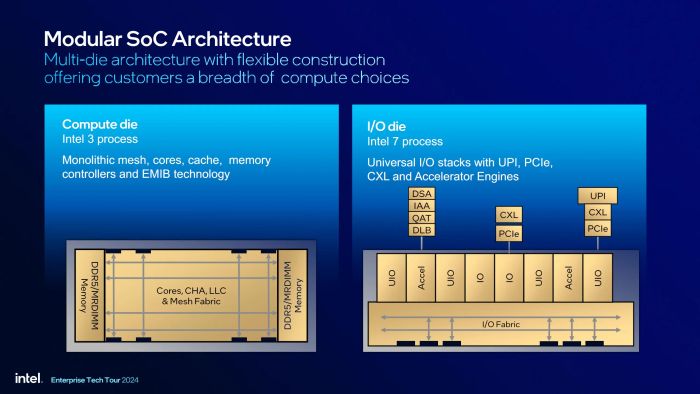
Cấu trúc của die compute và die I/O
Về die I/O, mặc dù không có IMC như AMD, nhưng các chức năng khác vẫn tương tự. Các kết nối ra ngoài CPU, chẳng hạn như UPI, PCIe, CXL... đều do 2 die I/O đảm nhiệm. Vì chức năng đơn giản hơn, die I/O được sản xuất trên tiến trình Intel 7 (hoặc 10 nm).
Điểm khác biệt cuối cùng giữa Intel và AMD (hay chính xác hơn là TSMC) là các liên kết giữa các die được thực hiện thông qua cầu EMIB do Intel tự phát triển, thay vì sử dụng interposer như TSMC. Mặc dù chưa rõ liệu Gaudi 3 có sử dụng công nghệ liên kết die nào, nhưng khả năng cao là vẫn dùng interposer vì hai thế hệ Gaudi trước cũng được sản xuất bởi TSMC. Chúng ta sẽ có một bài viết sâu hơn về các công nghệ đóng gói chip này trong những dịp sau.
MRDIMM, CXL 2.0 và cấu trúc bộ nhớ trên Xeon 6
Một trong những tính năng đặc biệt chưa từng có trên bất kỳ vi xử lý nào khác chính là MRDIMM trên Granite Rapids. Đây là một chuẩn bộ nhớ mới, và do đó tên gọi của nó vẫn chưa được thống nhất giữa các nhà sản xuất. Ta tạm gọi nó là DIMM Chồng Rank (Multiplexed Rank DIMM). Khác với DIMM truyền thống chỉ có một rank và sử dụng đường dữ liệu 64-bit, MRDIMM kết hợp hai rank lại với nhau, cho phép truyền tải dữ liệu lên đến 128-bit cùng lúc.
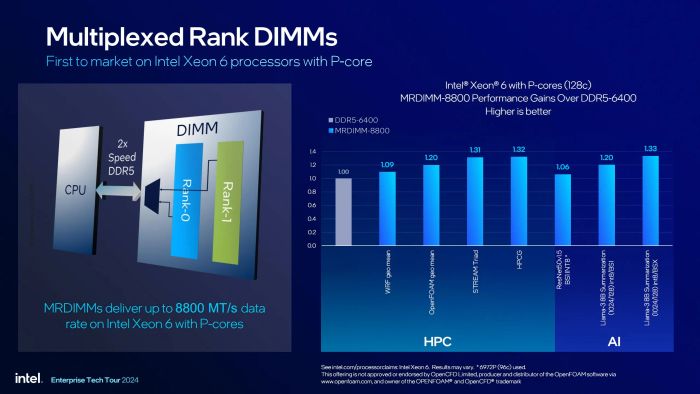

MRDIMM không chỉ mang lại băng thông cao mà còn giúp tăng dung lượng cho từng DIMM
Theo tiêu chuẩn của JEDEC, MRDIMM có ba phiên bản: Gen 1, Gen 2 và Gen 3 với băng thông lần lượt là 8800, 12800 và 17600 MT/s. Loại MRDIMM được hỗ trợ trên Granite Rapids là Gen 1. Bên cạnh việc nâng cao băng thông, MRDIMM còn cho phép tích hợp nhiều chip nhớ hơn trên cùng một khe DIMM. Thực tế, MRDIMM tương tự như việc kết hợp hai thanh DDR5 vào một khe DIMM. Giải pháp này lý tưởng cho các ứng dụng trong cụm server cần bộ nhớ RAM dung lượng lớn, cùng với các ứng dụng yêu cầu bộ nhớ cao khác.

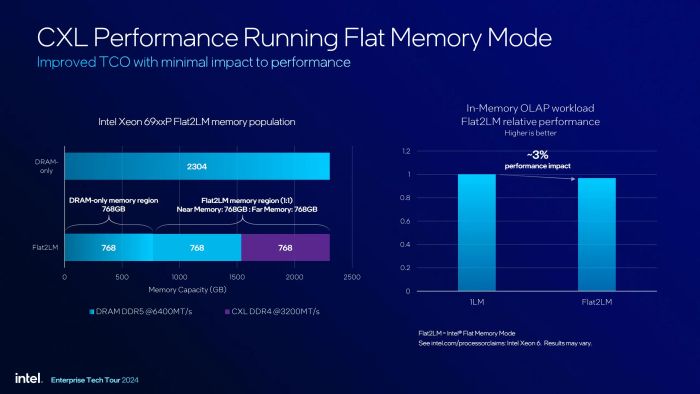
Nguyên lý hoạt động của CXL


Những sản phẩm nâng cấp bộ nhớ RAM dựa trên chuẩn CXL
Khi nói đến MRDIMM, không thể không nhắc đến CXL (Compute Express Link). Đây là một giải pháp giúp tăng cường khả năng mở rộng bộ nhớ cho server thông qua giao tiếp PCIe, với trọng tâm là RAM. Mặc dù với người dùng PC, việc có nhiều RAM không phải lúc nào cũng là yếu tố quyết định, nhưng đối với server, chi phí RAM có thể cao gấp nhiều lần so với chi phí CPU! Với CXL, người dùng hoàn toàn có thể trang bị thêm card PCIe hoặc thậm chí là một rack riêng biệt chỉ để mở rộng bộ nhớ RAM. Điều tuyệt vời nhất là các loại RAM mà những card hay rack này sử dụng không cần phải cùng chuẩn hỗ trợ với CPU. Bạn có thể dùng DDR5 trên DIMM và DDR4 trên card CXL cùng một lúc, miễn là dung lượng RAM là điều quan trọng, không cần quan tâm đến tốc độ.
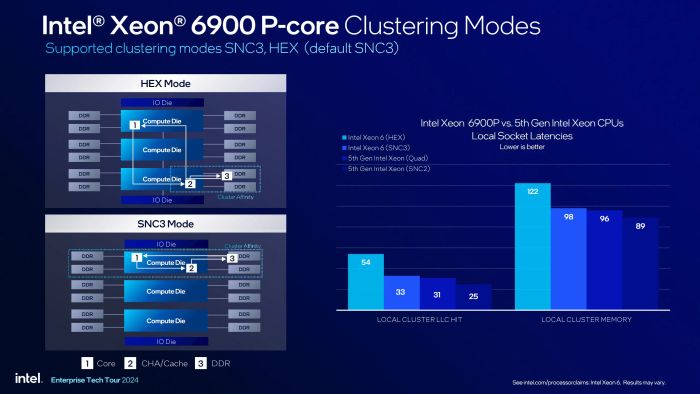
Xeon 6900P hoạt động hiệu quả nhất khi sử dụng chế độ Cluster
Tuy nhiên, khi một nhân x86 trên die A cần dữ liệu từ cache hoặc RAM trên die B hoặc C, thời gian truy xuất sẽ lâu hơn so với việc lấy trực tiếp từ die A. Để tối ưu hóa tốc độ truyền tải dữ liệu, Intel cung cấp hai mô hình truy cập bộ nhớ là HEX và SNC3 (mặc định). Trong mô hình HEX, ba die compute được xem như một khối đồng nhất, không phân biệt nguồn dữ liệu đến từ đâu. Ngược lại, với mô hình SNC3 (được kích hoạt trong BIOS), vi xử lý sẽ được chia thành ba cụm xử lý độc lập và mỗi cụm ưu tiên truy xuất dữ liệu từ die của chính nó trước khi tìm đến các die khác.
Kiến trúc và hiệu suất
Khi Granite Rapids ra mắt và chỉ sau vài tuần đã bị Turin đánh bại, nhiều người đã chỉ trích Intel. Tuy nhiên, theo quan điểm của tôi, thất bại này hoàn toàn có thể dự đoán trước được. Nếu Granite Rapids không thua Turin thì đó mới thực sự là vấn đề đáng lo ngại đối với AMD. Tại sao lại như vậy?

Granite Rapids sử dụng kiến trúc Redwood Cove, tương tự Meteor Lake
Granite Rapids không được trang bị kiến trúc P-core mới nhất của Intel, mà thay vào đó là phiên bản cũ hơn mang tên Redwood Cove. Đây chính là kiến trúc được sử dụng trên chip Meteor Lake, ra mắt vào cuối năm ngoái. Các dòng sản phẩm gần đây như Lunar Lake và Arrow Lake đã chuyển sang sử dụng kiến trúc mới hơn, Lion Cove. Dù giữa Redwood Cove và Lion Cove có một số điểm khác biệt, nhưng điểm nổi bật nhất là Redwood Cove chỉ có bộ giải mã 6-wide, trong khi Lion Cove sử dụng 8-wide decoder. Kiến trúc Zen 5/5c mới ra mắt của AMD cũng sử dụng 8-wide decoder, vì vậy có thể nói Lion Cove mới tương đương với Zen 5, trong khi Redwood Cove có thể được xem là thấp hơn một bậc.
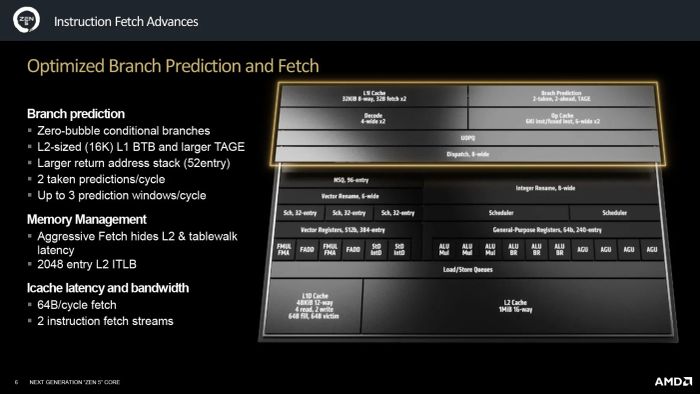
Kiến trúc Zen 5 trên Turin vượt trội hơn Redwood Cove rất nhiều
Do đó, việc Granite Rapids bị Turin đánh bại là điều không thể tránh khỏi. Nếu Granite Rapids không thất bại, thì có lẽ AMD mới là bên phải lo sợ! Nhìn chung, mặc dù không công khai nói ra, cả Lisa Su và Pat Gelsinger đều hiểu rõ tình thế hiện tại. Để có thể đối đầu với Turin, ít nhất dòng Granite Rapids tiếp theo phải được trang bị kiến trúc Lion Cove. Tuy nhiên, cả AMD và Intel vẫn rất kín đáo về các dòng vi xử lý server tiếp theo. Điều duy nhất có thể chắc chắn là Intel đã phát triển chip Panther Lake với nhân P-core Cougar Cove. Nhưng cụ thể sẽ ra sao thì vẫn còn là một ẩn số.
Trở lại Granite Rapids, mặc dù không thể so sánh hiệu năng với Turin, nhưng nó vẫn có thể vượt qua Genoa (EPYC 9004) – đó là điều quan trọng. Với kiến trúc 6-wide decoder, Intel thực sự không kỳ vọng Granite Rapids sẽ cạnh tranh trực tiếp với Turin. Tuy nhiên, vấn đề then chốt là Intel cần khẳng định lại vị thế của mình trên thị trường server, nơi mà công ty đã từng “lật đổ” các tên tuổi lớn như Sun hay IBM. Granite Rapids có thể được nhìn nhận như một bước chuyển tiếp, tương tự như Meteor Lake trước đó, dù không vượt trội so với đối thủ nhưng lại là bước ngoặt quan trọng để Intel tìm lại chính mình.
Nhận xét
Những năm gần đây có thể coi là giai đoạn “sau đỉnh cao” trong hành trình của Intel. Liệu năm 2024 này có phải là thời điểm công ty này “chạm đáy” hay không, chúng ta vẫn chưa thể kết luận. Tuy nhiên, không thể phủ nhận rằng dưới sự lãnh đạo của Pat Gelsinger, Intel đang nỗ lực thay đổi và tìm lại hướng đi của mình.

Sapphire Rapids và Ponte Vecchio là hai yếu tố khiến Intel tụt lại phía sau
Vào giai đoạn 2022, khi Intel vẫn còn dựa vào công nghệ 14 nm, công ty gần như không có sản phẩm đáng chú ý nào. Sapphire Rapids, dưới sự phát triển của Raja Koduri, thực sự là một thất bại khi được công bố vào năm 2019 nhưng phải đến tận 2023 mới ra mắt. Emerald Rapids sau đó xuất hiện như một nỗ lực để sửa chữa những sai lầm mà Sapphire Rapids để lại. Có thể so sánh Sapphire Rapids với Bulldozer của AMD, khi đối thủ này đã phải vật lộn với các thế hệ như Piledriver, Steamroller, và Excavator trước khi tìm được sự hồi sinh với kiến trúc Zen.
Và rồi Granite Rapids xuất hiện. Mặc dù bị Turin đánh bại nhanh chóng, nhưng gọi Granite Rapids là một thất bại thì không chính xác. Điểm yếu lớn nhất của Granite Rapids hiện nay chính là giá thành. Intel cần phải có một chiến lược giá hợp lý để có thể cạnh tranh với các đối thủ. Sự thật là khách hàng không quan tâm đến giá sản xuất chip, mà chỉ quan tâm đến số tiền họ phải bỏ ra. Chẳng hạn như với AmpereOne. Và so với các yếu tố khác (kiến trúc, hiệu năng, lỗi), giá thành là yếu tố dễ dàng điều chỉnh nhất.

Điểm yếu lớn nhất của Granite Rapids là chi phí quá cao
Đây chính là lý do căn bản tại sao sự cạnh tranh giữa các nhà sản xuất lại quan trọng. Bởi vì khi một trong hai, Intel hoặc AMD, không còn tồn tại, người thiệt thòi nhất chính là người tiêu dùng. Chúng ta đã từng chứng kiến điều này khi AMD gần như phá sản, và những bộ vi xử lý desktop tốt nhất lúc đó chỉ có 4 nhân, kéo dài suốt nhiều năm cho đến khi Ryzen ra đời. Ở một mảng khác, NVIDIA gần như chiếm lĩnh thị trường GPU cao cấp khi AMD không còn chú trọng sản xuất GPU cho game thủ. Ai là người chịu thiệt thòi nhất? Hãy nhìn vào túi tiền của chính mình.