
DeepSeek có thể duy trì hoạt động và phát triển mô hình AI của mình với chi phí thấp hơn rất nhiều so với các đối thủ lớn khác trong ngành.
Chỉ sau vài giờ, cái tên DeepSeek, một startup AI từ Trung Quốc, đã trở thành tâm điểm tại Mỹ, giống như cách mà của OpenAI đã làm trước đó hai năm. Tuy nhiên, lần này, DeepSeek đã khiến các cổ phiếu công nghệ tại Mỹ chịu tổn thất nặng nề.
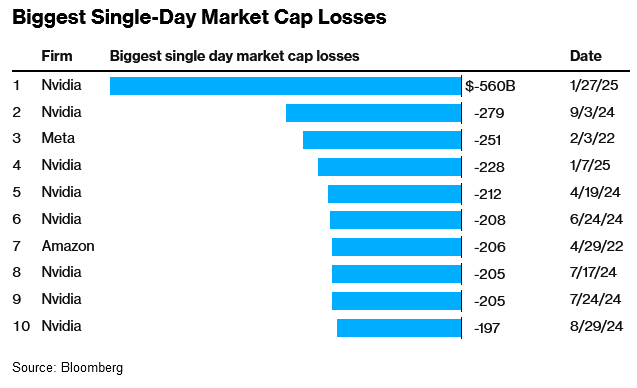
Ngay sau khi thị trường mở cửa phiên giao dịch đầu tuần, vốn hóa của NVIDIA – ông vua chip AI – đã giảm hơn 500 tỷ USD, một mức sụt giảm chưa từng có trong lịch sử chứng khoán Mỹ. Chỉ số Nasdaq 100 của Mỹ cũng mất hơn 3%, tương đương hơn 1.000 tỷ USD vốn hóa toàn thị trường.
Mô hình AI mã nguồn mở DeepSeek từ Trung Quốc, với hiệu suất tương đương , nhưng chi phí phát triển chỉ bằng 1-2% và chi phí kết nối API chỉ bằng 1/10 so với , đã gây ra đợt sụt giảm mạnh này.
DeepSeek cho biết họ chỉ cần 2.000 GPU hiệu năng thấp của NVIDIA để xây dựng mô hình AI của mình, trong khi OpenAI phải sử dụng hàng trăm nghìn GPU hiệu năng cao của NVIDIA để phát triển . Điều này thực sự là một cú sốc đối với mô hình kinh doanh của NVIDIA, khi họ chủ yếu phụ thuộc vào việc cung cấp GPU đắt đỏ cho các công ty AI.
Vì DeepSeek là một mô hình mã nguồn mở, ai cũng có thể tải về và phát triển AI của riêng mình với chi phí thấp, mà không cần đến những GPU đắt đỏ của NVIDIA. Chính điều này đã tạo ra một làn sóng bán tháo, khiến cổ phiếu NVIDIA lao dốc thảm hại.
Vì sao DeepSeek lại có thể làm sụp đổ thị trường như vậy?
Mô hình MoE (Mixture-of-Experts) độc đáo là trái tim của DeepSeek. Thay vì sử dụng toàn bộ 671 tỷ tham số, MoE chỉ kích hoạt 37 tỷ tham số cần thiết cho mỗi tác vụ. Các ‘chuyên gia’ trong MoE được huấn luyện riêng cho từng nhiệm vụ, giúp tối ưu hóa chi phí tính toán mà không làm tăng chi phí. Khi cần, DeepSeek chỉ huy động những ‘chuyên gia’ phù hợp, giống như một đội ngũ tinh nhuệ chỉ tập trung vào nhân tài thật sự cần thiết.

DeepSeek sử dụng nhiều phương pháp khác nhau để giữ chi phí phát triển ở mức thấp nhất.
Không chỉ dừng lại ở MoE, DeepSeek còn sử dụng phương pháp học tăng cường thuần túy (pure reinforcement learning) để huấn luyện các chuyên gia của mình. Thay vì học từ dữ liệu có nhãn như các đối thủ, DeepSeek học qua thử và sai, tự tích lũy kinh nghiệm từ dữ liệu không nhãn mà không cần sự can thiệp của con người.
Giống như một đứa trẻ tự học bơi qua việc liên tục thực hành, DeepSeek tự hoàn thiện mình qua hàng nghìn thất bại, cho đến khi tìm ra cách tối ưu nhất. Phương pháp này đã giúp DeepSeek tiết kiệm được chi phí và công sức dán nhãn dữ liệu, điều mà ngành AI gặp phải rất nhiều khó khăn.
DeepSeek còn áp dụng kỹ thuật Quantization để giảm độ chính xác tham số từ 32-bit xuống 8-bit. Điều này giúp giảm tới 75% lượng bộ nhớ cần thiết, tăng tốc độ xử lý mà không làm giảm hiệu quả của mô hình. Hơn nữa, thiết kế và huấn luyện kỹ lưỡng đã giúp DeepSeek duy trì độ tin cậy cao, khiến các mô hình có thể hoạt động mượt mà trên các thiết bị phần cứng giá rẻ như GPU gaming, thay vì những GPU máy chủ đắt tiền.

Hiệu năng xử lý của DeepSeek không hề thua kém và các đối thủ lớn trong ngành.
Cơ chế Multi-Head Latent Attention của DeepSeek giúp cải thiện khả năng xử lý dữ liệu khi liên kết chúng với nhau. Nhờ đó, mô hình này vượt trội trong việc xử lý ngữ cảnh dài lên đến 128K tokens, vượt xa các mô hình khác chỉ đạt 32K-64K tokens. Điều này giúp DeepSeek duy trì tính ổn định khi xử lý các tác vụ phức tạp như phân tích dữ liệu lớn hoặc các dự án lập trình quy mô.
Trên các bài benchmark phức tạp liên quan đến lập trình, lập luận hay trả lời câu hỏi, DeepSeek thậm chí còn cạnh tranh ngang ngửa hoặc vượt trội so với các ‘chuyên gia’ như GPT-4 của OpenAI và Claude của Anthropic.
Mối đe dọa lớn đối với mô hình kinh doanh của NVIDIA
Bên cạnh những đột phá về kiến trúc, triết lý mã nguồn mở là yếu tố then chốt góp phần vào thành công của DeepSeek. Không giống như nhiều gã khổng lồ công nghệ giữ kín bí mật, startup này công khai mã nguồn và các bài báo kỹ thuật chi tiết. Điều này không chỉ minh bạch, mà còn mời gọi cộng đồng cùng tham gia đóng góp, giúp cải tiến mô hình AI mà không cần thêm chi phí.

Không phải , mà NVIDIA mới là kẻ chịu thiệt hại lớn nhất khi DeepSeek xuất hiện.
Với triết lý mã nguồn mở, các công ty khác cũng có thể tận dụng mã nguồn này để xây dựng mô hình AI giá rẻ cho riêng mình. Điều này hoàn toàn đảo ngược nguyên tắc “AI chỉ dành cho những gã khổng lồ công nghệ”, vì giờ đây bạn không cần trung tâm dữ liệu trị giá hàng tỷ USD, chỉ cần một vài GPU chất lượng cao là đủ.
Đối với NVIDIA, đây là một mối đe dọa thực sự. Trong suốt hơn 2 năm qua, công ty này đã vượt qua Apple để trở thành công ty giá trị nhất thế giới nhờ vào nhu cầu mạnh mẽ từ các công ty muốn sở hữu GPU cao cấp của NVIDIA, có giá lên đến hàng chục nghìn USD để xây dựng các trung tâm dữ liệu. Tuy nhiên, sự xuất hiện của DeepSeek có thể sẽ thay đổi điều này.
DeepSeek chính là minh chứng cho sự đột phá sáng tạo. Một nhóm nhỏ chưa đầy 200 người, với chi phí phát triển sản phẩm thấp hơn rất nhiều so với các đối thủ, nhưng lại khiến các ông lớn trong ngành phải lo sợ.
Nguyễn Hải