
Sự kiện này gióng lên hồi chuông cảnh báo: ngay cả những hệ thống công nghệ tinh vi và được xây dựng kỹ lưỡng như Google cũng có thể sụp đổ chỉ vì những sai sót cực kỳ cơ bản.
Vào 10h45 sáng ngày 12/6/2025 (giờ PDT), hàng loạt nền tảng internet hàng đầu thế giới bao gồm Google, Spotify, Discord, Cloudflare cùng nhiều dịch vụ trực tuyến khác đồng loạt ngừng hoạt động trên quy mô lớn. Nguyên nhân sau đó được xác định xuất phát từ lỗi hệ thống của Google Cloud - một trong những sự cố nghiêm trọng nhất lịch sử nền tảng này, ảnh hưởng tới hàng chục triệu người dùng khắp thế giới.
Điều gây sốc nhất không phải mức độ thiệt hại mà chính là nguyên nhân - một lỗi lập trình sơ đẳng mà bất kỳ sinh viên CNTT năm nhất nào cũng biết cách phòng tránh. Sự việc minh chứng cho việc một sai lầm nhỏ bé có thể tạo ra hiệu ứng domino thảm khốc trong thế giới công nghệ kết nối hiện nay.

Ngày 12/6 vừa qua chứng kiến sự cố ngừng hoạt động hàng loạt của các dịch vụ internet
Hiệu ứng domino của những sai lầm liên tiếp
Muốn hiểu rõ sự cố, cần phải nắm được chức năng then chốt của hệ thống Service Control trong cơ sở hạ tầng Google Cloud. Đóng vai trò như trung tâm điều phối, Service Control xử lý mọi yêu cầu API đến Google Cloud, bao gồm xác thực người dùng, kiểm soát hạn mức sử dụng, thực thi chính sách bảo mật và ghi nhận dữ liệu tính phí. Có thể ví Service Control như "trái tim" của toàn bộ hệ thống Google Cloud.
Mọi chuyện bắt đầu vào ngày 29/5/2025 khi nhóm kỹ sư Google triển khai bản nâng cấp mới cho Service Control. Bản cập nhật này nhằm cải thiện khả năng quản lý hạn mức sử dụng chi tiết hơn, đáp ứng yêu cầu ngày càng phức tạp từ các khách hàng doanh nghiệp.
Quá trình triển khai đã phạm phải sai lầm nghiêm trọng trong quy trình phát triển phần mềm. Đội ngũ kỹ thuật đã bỏ qua việc sử dụng 'feature flag' - công cụ cho phép tắt nhanh tính năng mới khi cần thiết. Điều này đồng nghĩa với việc tính năng sẽ hoạt động toàn hệ thống mà không có phương án dự phòng khẩn cấp.
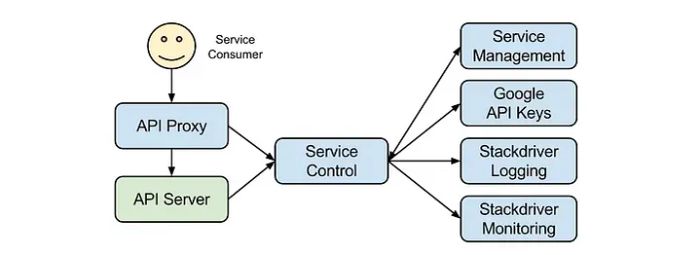
Service Control - trái tim của hệ thống quản lý API Google Cloud
Đáng báo động hơn, bản cập nhật chứa lỗi null pointer - một trong những lỗi lập trình cơ bản nhất. Lỗi này xảy ra khi chương trình truy cập vào vùng nhớ chưa được cấp phát. Trường hợp cụ thể này chỉ phát sinh khi hệ thống xử lý một kiểu dữ liệu đặc biệt mà quá trình kiểm thử đã bỏ sót.
Hai tuần sau ngày triển khai, vào 12/6, một sự kiện tưởng chừng vô hại đã châm ngòi cho thảm họa. Một nhân viên Google tải lên bản cập nhật chính sách chứa các trường dữ liệu để trống - điều thường thấy trong hoạt động hàng ngày và thường được hệ thống xử lý trơn tru.
Khi Service Control đọc các trường dữ liệu trống này, tính năng mới lập tức gặp lỗi null pointer. Hậu quả là toàn bộ Service Control ngừng hoạt động đột ngột, khiến hệ thống mất khả năng xử lý mọi yêu cầu API.
Tình hình trở nên tồi tệ hơn do cơ chế hoạt động của Spanner. Cơ sở dữ liệu này được thiết kế để đồng bộ dữ liệu toàn cầu nhằm đảm bảo tính nhất quán. Chỉ trong tích tắc, dữ liệu lỗi đã lan truyền khắp các trung tâm dữ liệu Google toàn cầu, khiến mọi phiên bản Service Control lần lượt gặp sự cố khi xử lý dữ liệu nhiễm độc này.

Chỉ từ một lỗi null pointer đơn giản, toàn bộ hệ thống của Google và các đối tác đã sụp đổ theo hiệu ứng domino không thể ngăn cản
Những hệ lụy nghiêm trọng từ sự cố
Ảnh hưởng của sự cố nhanh chóng lan ra ngoài phạm vi Google. Vô số dịch vụ và ứng dụng của bên thứ ba phụ thuộc vào nền tảng Google Cloud cũng chịu tác động nặng nề. Đáng chú ý nhất là Cloudflare - nhà cung cấp dịch vụ bảo mật và tăng tốc website vốn nổi tiếng với độ ổn định cao.
Hàng loạt ứng dụng phổ biến với hàng triệu người dùng hàng ngày cũng bị ảnh hưởng: Spotify không thể phát nhạc, Discord mất kết nối giữa các cộng đồng, Snapchat gián đoạn dịch vụ chia sẻ hình ảnh, thậm chí của OpenAI cũng ngừng hoạt động. Ngay cả một số dịch vụ của Amazon Web Services cũng chịu tác động do mối quan hệ phụ thuộc giữa các nhà cung cấp đám mây.
Đội ngũ SRE của Google đã có phản ứng nhanh nhạy. Chỉ trong 2 phút sau khi phát hiện sự cố, họ đã xác định được nguyên nhân và bắt đầu triển khai biện pháp khắc phục. Google đã kích hoạt cơ chế 'kill switch' để loại bỏ đoạn mã lỗi chỉ sau 10 phút kể từ thời điểm xảy ra sự cố.

Quá trình khôi phục diễn ra tương đối suôn sẻ ở hầu hết các khu vực. Phần lớn dịch vụ trở lại hoạt động bình thường sau 40 phút. Riêng khu vực us-central1 (Iowa) gặp vấn đề phức tạp hơn khi tất cả phiên bản Service Control cùng khởi động lại đồng loạt, tạo ra hiện tượng 'herd effect' làm quá tải cơ sở dữ liệu backend, khiến việc khôi phục kéo dài gần 3 tiếng.
Một điểm đáng lưu ý khác là vấn đề truyền thông với khách hàng. Google không thể cập nhật trạng thái dịch vụ vì chính hệ thống bảng điều khiển cũng nằm trên cơ sở hạ tầng bị sự cố. Điều này buộc người dùng phải tìm kiếm thông tin từ các nguồn bên ngoài như DownDetector và mạng xã hội.
Trước làn sóng chỉ trích, Google đã công bố bản báo cáo kỹ thuật chi tiết cùng các biện pháp khắc phục cụ thể. Công ty cam kết nâng cấp khả năng xử lý dữ liệu không hợp lệ của hệ thống quản lý API, thiết lập cơ chế kiểm soát chặt chẽ hơn để ngăn chặn việc đồng bộ dữ liệu lỗi trên phạm vi toàn cầu, đồng thời mở rộng quy trình kiểm thử để phát hiện sớm các trường hợp dữ liệu bất thường.
Sự kiện này làm lộ rõ xu hướng tập trung hóa đáng lo ngại trong ngành công nghệ. Khi phần lớn dịch vụ trực tuyến đều phụ thuộc vào một số ít gã khổng lồ cơ sở hạ tầng, chỉ một điểm yếu duy nhất cũng có thể gây ra hiệu ứng sụp đổ dây chuyền trên quy mô toàn cầu. Điều này đặt ra những câu hỏi quan trọng về tính đa dạng và khả năng chịu lỗi trong kiến trúc hệ thống công nghệ hiện đại.
Dù Google đã thể hiện năng lực xử lý khủng hoảng chuyên nghiệp và hiệu quả, sự cố này vẫn là lời cảnh tỉnh: ngay cả những hệ thống tinh vi và được đầu tư bài bản nhất cũng có thể sụp đổ vì những sai sót cực kỳ cơ bản. Trong kỷ nguyên số phụ thuộc ngày càng nhiều vào điện toán đám mây, việc xây dựng các cơ chế dự phòng và quy trình ứng phó sự cố trở thành yêu cầu sống còn.
Nguyễn Hải (Tổng hợp)