
Tuy nhiên, liệu giải pháp phần mềm này có thể giúp Trung Quốc không còn phụ thuộc vào các GPU cao cấp của NVIDIA nữa không?
Để duy trì sự hiện diện tại thị trường Trung Quốc nhưng vẫn tuân thủ các quy định của Mỹ về xuất khẩu công nghệ, NVIDIA đã ra mắt GPU H800, phiên bản giảm hiệu năng và tính năng so với GPU H100, nhằm phục vụ thị trường Trung Quốc.
Tuy nhiên, DeepSeek của Trung Quốc dường như đã tìm ra cách giải quyết mà không cần nâng cấp phần cứng. Mới đây, trong sự kiện "OpenSource Week", startup AI này đã công bố FlashMLA – một phần mềm đặc biệt thiết kế cho kiến trúc GPU Hopper của NVIDIA, giúp tối ưu hóa GPU H800 và tăng tốc huấn luyện AI. Công cụ này được phát hành mã nguồn mở trên GitHub.
Điều đặc biệt là công cụ này không cải thiện hiệu năng thông qua phần cứng, mà sử dụng các thuật toán và quản lý tài nguyên một cách thông minh. FlashMLA áp dụng kỹ thuật nén "low-rank key-value" để chia nhỏ dữ liệu, giúp giảm mức tiêu thụ bộ nhớ từ 40-60% so với phương pháp xử lý truyền thống mà không làm giảm độ chính xác.
Giải pháp này cũng sử dụng hệ thống phân trang khối (block-based paging system), giúp phân bổ bộ nhớ động linh hoạt theo mức độ tác vụ, nâng cao khả năng xử lý các chuỗi dữ liệu có độ dài thay đổi.
FlashMLA đã được DeepSeek phát hành mã nguồn mở trên GitHub
Theo DeepSeek, giải pháp của họ giúp tăng tốc AI trên GPU H800 đạt 580 TFLOPS (TeraFLOPS) với phép nhân ma trận BF16 – gấp 8 lần so với điểm chuẩn thông thường khi sử dụng GPU H800 trong huấn luyện AI (khoảng 73,5 TFLOPS mà không có tối ưu hóa).
Băng thông bộ nhớ cũng được đẩy lên 3000 GB/s, gần gấp đôi giới hạn lý thuyết của H800 (1681 GB/s). Những con số này chứng minh rằng DeepSeek không chỉ vượt qua giới hạn phần cứng mà còn thiết lập một chuẩn mới về hiệu quả tính toán.

Thông số hiệu năng của H800 sau tối ưu gấp 8 lần so với điểm số thông thường
Nhờ vào những cải tiến này, FlashMLA đã giúp tăng tốc độ suy luận trên các mô hình ngôn ngữ lớn với 176 tỷ tham số lên gấp 2,3 lần so với các phương pháp triển khai hiện tại. DeepSeek hiện đã triển khai công cụ này trong môi trường sản xuất, cho thấy tính ứng dụng cao của giải pháp này.
Mặc dù được tăng cường mạnh mẽ về khả năng xử lý, hiệu năng của GPU H800 sau khi tối ưu phần mềm vẫn thấp hơn so với GPU H100 tiêu chuẩn – dòng GPU tiên tiến nhất trong kiến trúc Hopper của NVIDIA.
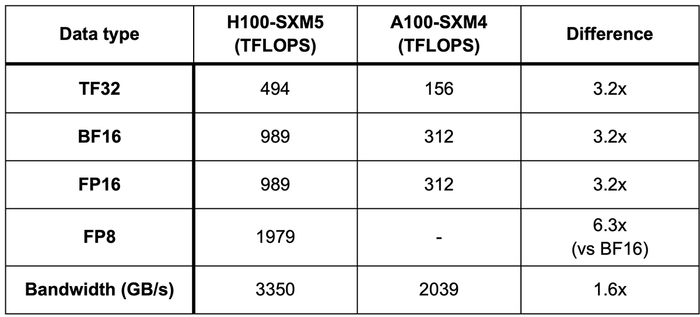
Sức mạnh tính toán: H100 đạt 989 TFLOPS theo lý thuyết với định dạng BF16, vượt xa so với 580 TFLOPS của H800 sau khi tối ưu hóa bằng FlashMLA. Tuy nhiên, FlashMLA đã giúp thu hẹp khoảng cách đáng kể, đưa H800 lên gần 60% hiệu suất đỉnh của H100 chỉ nhờ phần mềm.
Thông số hiệu năng của GPU NVIDIA H100 vẫn cao hơn H800 sau khi tối ưu bằng giải pháp của DeepSeek
Băng thông bộ nhớ: H100 vượt trội với 3350 GB/s nhờ sử dụng HBM3, trong khi H800 với FlashMLA đạt 3000 GB/s. Mặc dù kém một chút, H800 vẫn thể hiện khả năng tối ưu xuất sắc khi vượt qua giới hạn phần cứng ban đầu của nó. Nếu không có FlashMLA, H100 sẽ nhanh hơn H800 khoảng 1,5-2 lần trong các tác vụ AI thông thường.
Giải pháp FlashMLA của DeepSeek cho GPU H800 chứng minh rằng phần mềm có thể khắc phục các hạn chế của phần cứng. Mặc dù GPU H100 vẫn dẫn đầu về sức mạnh tính toán thuần túy, DeepSeek mở ra cơ hội rằng với các tối ưu tương tự, H100 có thể đạt được những hiệu suất mới, vượt qua các chỉ số hiện tại. Với việc công cụ này được phát hành mã nguồn mở trên GitHub, có khả năng cao là nó sẽ được thử nghiệm trên dòng H100 trong tương lai để khám phá khả năng nâng cao hiệu suất.