
Điều đặc biệt là mô hình AI này có thể huấn luyện mà không cần sử dụng các GPU cao cấp của NVIDIA, những sản phẩm đang bị cấm xuất khẩu sang Trung Quốc.
DeepSeek, một công ty khởi nghiệp AI tại Hàng Châu, Trung Quốc, vừa giới thiệu mô hình ngôn ngữ lớn (LLM) mới mang tên DeepSeek V3, vượt qua các đối thủ lớn như Meta Platforms và OpenAI trong các bài kiểm tra hiệu suất, với chi phí huấn luyện thấp hơn nhiều.
Theo thông tin từ một bài đăng trên WeChat vào thứ Năm, DeepSeek tiết lộ mô hình DeepSeek V3 mới sở hữu 671 tỷ tham số và chỉ mất 2 tháng huấn luyện với chi phí 5,58 triệu USD. Điều này giúp tiết kiệm đáng kể tài nguyên tính toán so với các mô hình của các công ty công nghệ lớn. Các mô hình LLM là nền tảng cho các công cụ AI tạo sinh như . Số lượng tham số lớn giúp LLM xử lý các mẫu dữ liệu phức tạp và đưa ra dự đoán chính xác hơn.

DeepSeek, startup AI đầy triển vọng từ Trung Quốc
Thậm chí, Andrej Karpathy, nhà khoa học máy tính và thành viên sáng lập OpenAI, đã bày tỏ sự bất ngờ trước báo cáo kỹ thuật về mô hình AI của DeepSeek. Ông viết trên nền tảng X: "DeepSeek khiến mọi thứ trở nên dễ dàng khi phát hành một LLM hàng đầu với ngân sách huấn luyện gần như không đáng kể."
Đặc biệt, mô hình V3 được huấn luyện với chỉ 2,78 triệu giờ GPU, tức là tổng thời gian sử dụng bộ xử lý đồ họa để huấn luyện một LLM. Quá trình này sử dụng GPU H800 của NVIDIA, được thiết kế riêng cho Trung Quốc và có hiệu suất thấp hơn so với các GPU cao cấp khác.
Con số này thấp hơn rất nhiều so với 30,8 triệu giờ GPU mà Llama 3.1 của Meta cần để huấn luyện trên GPU H100 cao cấp của NVIDIA, loại chip không được phép xuất khẩu sang Trung Quốc.
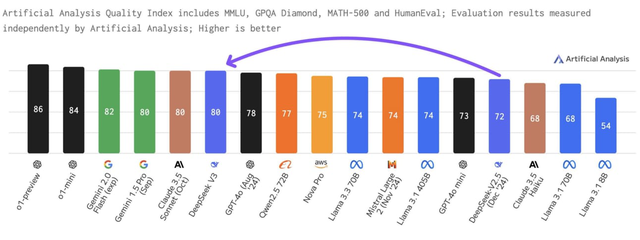
Kích thước của DeepSeek V3 tương đương với các mô hình AI tiên tiến nhất hiện nay, nhưng chi phí huấn luyện lại thấp hơn rất nhiều.
Báo cáo kỹ thuật về DeepSeek V3 cho thấy mô hình này vượt trội hơn Llama 3.1 của Meta và Qwen 2.5 của Alibaba trong các bài kiểm tra đánh giá khả năng hiểu và tạo văn bản, kiến thức chuyên sâu, lập trình và giải quyết bài toán toán học.
Kết quả benchmark của DeepSeek V3 cũng cho thấy mô hình này ngang tầm với GPT-4 của OpenAI và Claude Sonnet của Anthropic, những mô hình AI hàng đầu thế giới hiện nay.
Sự ra đời của DeepSeek V3 chứng minh sự tiến bộ của các công ty AI Trung Quốc, bất chấp các lệnh trừng phạt của Mỹ đã ngăn cản họ tiếp cận các bán dẫn tiên tiến dùng để huấn luyện mô hình. Bằng cách áp dụng kiến trúc mới tối ưu chi phí trong huấn luyện, DeepSeek đã chứng minh rằng phát triển một LLM mạnh mẽ không cần thiết phải có một nguồn vốn khổng lồ như các công ty lớn khác thường đầu tư.

Việc huấn luyện DeepSeek V3 hoàn toàn được thực hiện trên GPU H800 của NVIDIA, loại GPU được phép xuất khẩu sang Trung Quốc.
DeepSeek được tách ra từ High-Flyer Quant vào tháng 7 năm ngoái, công ty sử dụng AI để điều hành một trong những quỹ đầu cơ định lượng lớn nhất ở Trung Quốc. High-Flyer đã chi 200 triệu nhân dân tệ (27,4 triệu USD) để phát triển cụm AI Fire Flyer I trong giai đoạn 2019-2020, và sau đó tiếp tục chi thêm 1 tỷ nhân dân tệ để xây dựng Fire-Flyer II.
Trong một thông báo vào tháng 4 năm ngoái, High-Flyer chia sẻ mục tiêu của DeepSeek là phát triển "AI vì lợi ích của toàn nhân loại". Trước đó, DeepSeek đã cho ra mắt nhiều mô hình AI, được các nhà phát triển sử dụng để xây dựng các ứng dụng của bên thứ ba và chatbot của riêng họ.
Với DeepSeek V3, công ty khởi nghiệp Trung Quốc đã chứng minh rằng phát triển các mô hình AI tiên tiến không còn là độc quyền của các tập đoàn công nghệ lớn. Thành tích này sẽ thúc đẩy cạnh tranh và đổi mới trong ngành, đồng thời mở ra cơ hội cho các công ty nhỏ tham gia vào cuộc đua AI. Điều này cũng khiến chúng ta đặt câu hỏi về vị thế của Trung Quốc trong tương lai của AI, khi quốc gia này đang nỗ lực vượt qua các rào cản để trở thành cường quốc công nghệ.