

Trong bài viết trước, mình đã giải thích về vai trò của cache và sự quan trọng của nó đối với CPU. Hôm nay, chúng ta sẽ khám phá tại sao công nghệ 3D V-Cache lại là sự lựa chọn tối ưu cho game, mặc dù không phải tất cả mọi ứng dụng đều có thể tận dụng lợi ích từ bộ cache này, nhưng game là lĩnh vực nổi bật nhất. Đây là lý do vì sao?


Vật thể lơ lửng trong Starfield. Lưu ý rằng người chơi có thể tương tác với tất cả, và CPU sẽ xử lý các tác động này. Dữ liệu phát sinh sẽ được truy xuất nhanh chóng nếu bộ cache lớn hơn.
Bạn có thể nhận thấy rằng độ "thật" trong game tỉ lệ thuận với số lượng vật thể và hiệu ứng mà người chơi có thể tác động. Khi số lượng tương tác nhiều, lượng meta data sinh ra cũng sẽ tăng lên, mà điểm quan trọng là các meta data này không phải lúc nào cũng có sẵn mà chúng được tạo ra bởi người chơi hoặc các sự kiện trong game. Trong môi trường trọng lực bình thường, mọi vật thể đều có trọng lực và rơi xuống, nhưng khi ở trạng thái không trọng lực (zero-G), mọi thứ đều lơ lửng và Starfield cho phép bạn tương tác với tất cả những vật thể này. Do đó, bạn có thể thấy một vật thể bình thường ở khoang A có thể di chuyển sang khoang B do sự tác động của người chơi, và khi trọng lực trở lại, vật thể đó sẽ không còn ở vị trí ban đầu. Đây chính là meta data được người chơi tạo ra.
Vậy ai sẽ giải quyết những vấn đề này? Đó chính là CPU. Nếu CPU không đủ mạnh để xử lý các sự kiện kịp thời, nó sẽ gửi thông tin đến GPU với độ trễ. Và khi GPU nhận thông tin muộn, việc render sẽ chậm lại và trong một số trường hợp hiếm hoi, hình ảnh render có thể không chính xác (chẳng hạn khi bạn bắn nổ bình xăng làm cháy kẻ địch, nhưng GPU chưa nhận được thông tin để render kẻ địch bị cháy).
Tất nhiên, trong một hệ thống máy tính sẽ luôn có một thành phần gây nghẽn cổ chai. Khi game được render ở độ phân giải thấp, CPU sẽ là yếu tố nghẽn. Tuy nhiên, khi game xuất hình ảnh với độ phân giải cao, yêu cầu bóng đổ, ray-tracing, blurring, slo-mo... thì GPU sẽ là yếu tố nghẽn. Vì vậy, khi nói về CPU tốt nhất cho game, bạn cần hiểu rằng đó là CPU giúp xử lý các tác vụ không phải đồ họa hiệu quả nhất, chứ không phải là một GPU yếu mà vẫn yêu cầu chơi game ở độ phân giải 4K @ 120 fps.


Ở các độ phân giải thấp, sự khác biệt giữa fps cao nhất và thấp nhất có thể lên tới 60%. Tuy nhiên, khi tăng độ phân giải, gánh nặng sẽ chuyển từ CPU sang GPU.
Ngoài ra, một điểm quan trọng cần lưu ý khi nói về game đó là đối tượng người sử dụng. Mặc dù game cũng là một ứng dụng như bao phần mềm khác, nhưng có một đặc điểm đặc biệt đó là người chơi liên tục tương tác và điều khiển (ra lệnh) cho game/CPU. Điều này hoàn toàn khác biệt so với các ứng dụng khác như render bản vẽ CAD, encode video, hay giải nén file RAR/ZIP, nơi mà người dùng chỉ cần để chúng chạy tự động rồi đi làm việc khác. Với những ứng dụng này, fps cao hay thấp không quan trọng, nhưng với game, "không mượt là không mượt".
X3D không chỉ mang lại lợi ích cho game. Các ứng dụng xử lý dữ liệu lớn cũng sẽ hưởng lợi từ một bộ cache lớn. Tuy nhiên, việc trải nghiệm "chơi game mượt mà" rất khó nhận thấy khi chúng ta làm các công việc khác.
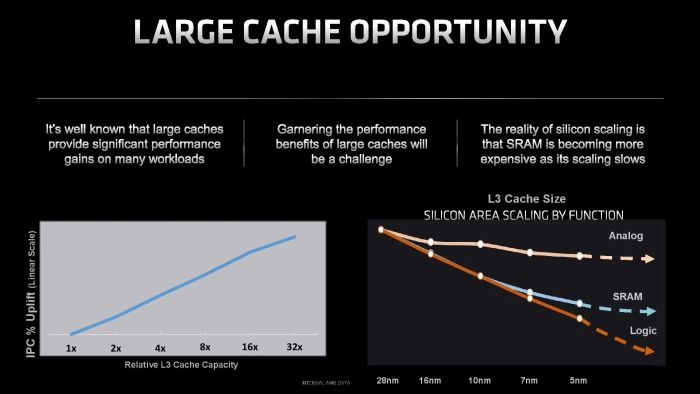
Vậy là bạn đã hiểu tại sao bộ cache càng lớn càng có lợi (dù không phải lúc nào cũng đúng 100%, nhưng đa phần là như vậy). Tuy nhiên, mặc dù ai cũng biết lý thuyết về bộ cache lớn, nhưng làm sao để đưa lý thuyết này thành sản phẩm thực tế lại là một vấn đề. Có thể nói, bất kỳ công ty sản xuất chip nào cũng đều hiểu những vấn đề này, nhưng việc triển khai chúng trong thực tế lại là câu chuyện khác. Bạn hẳn đã nghe câu nói quen thuộc "nói thì dễ, làm thì khó".
Như tôi đã chia sẻ trước, cấu trúc SRAM không quá phức tạp vì trong suốt hàng chục năm qua, nó vẫn không thay đổi. Vấn đề lớn nhất ở đây là SRAM tiêu tốn rất nhiều transistor (T) để sản xuất. SRAM phổ biến hiện nay cần đến 6T chỉ để chứa 1 bit dữ liệu! Để so sánh, bộ nhớ DRAM chỉ cần 1T và 1 tụ điện để chứa 1 bit dữ liệu. Tất nhiên, cũng có những loại SRAM tốn ít hoặc nhiều transistor hơn 6T, nhưng vì chúng ít được sử dụng, nên tạm thời không đề cập đến.
Cơn "hấp hối" của SRAM
Việc hao tổn transistor/silicon chỉ là một khía cạnh của vấn đề, một khía cạnh khác nghiêm trọng hơn là trong những năm gần đây, việc thu nhỏ tế bào SRAM trở nên khó khăn hơn rất nhiều. Mặc dù các mạch logic (CPU, GPU, DSP...) vẫn thu nhỏ tương đối tốt qua các tiến trình bán dẫn, nhưng bộ nhớ nói chung lại không tiến bộ như vậy. Thực tế, không chỉ SRAM mà cả DRAM và NAND cũng không đạt được mức độ mật độ dữ liệu cao như trước. Nếu để ý, bạn sẽ thấy các tiến trình sản xuất DRAM/NAND tiên tiến nhất hiện nay vẫn chỉ ở mức khoảng 10 nm hoặc lớn hơn.
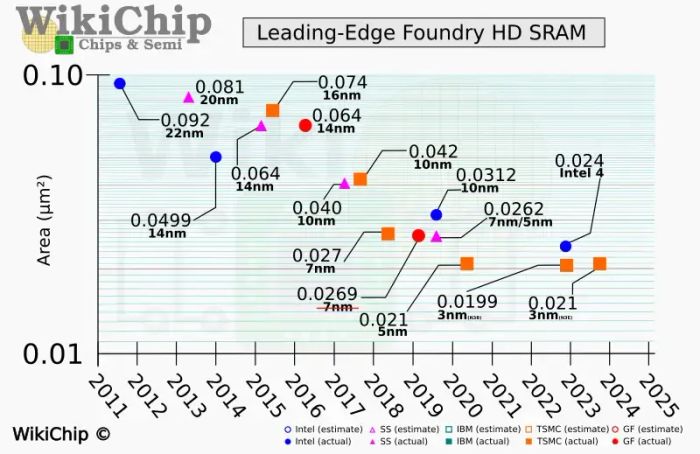
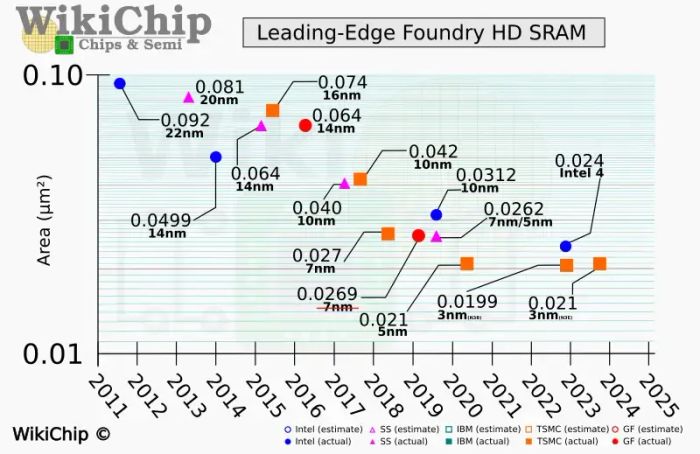
So sánh kích thước SRAM của các hãng qua các năm (TSMC màu cam). Dù có giảm kích thước, nhưng sự khác biệt này càng ngày càng nhỏ. Đặc biệt, TSMC N3P có kích thước gần giống với TSMC N5!
Tại hội nghị IEDM 2022, TSMC đã khiến cả ngành bán dẫn sửng sốt khi công bố kích thước tế bào SRAM của tiến trình N3. Trong khi mật độ mạch logic của N3 cao gấp 1.6 lần so với N5, thì mật độ SRAM chỉ tăng 5% (35 so với 31.8 Mb/mm^2). Thậm chí, phiên bản N3E (nâng cấp của N3) có mật độ SRAM tương đương với N5 (31.8 Mb/mm^2). Điều này có nghĩa là 32 MB SRAM ở N5 sẽ có kích thước giống hệt khi chuyển sang N3E!
Tin vui là trong thông tin mới nhất về tiến trình N2 (dự kiến sản xuất vào nửa cuối 2025), TSMC cho biết mật độ SRAM của N2 sẽ tăng đáng kể, lên đến 38 Mb/mm^2. Tuy nhiên, khả năng này có được nhờ vào việc N2 chuyển sang cấu trúc GAAFET nhỏ gọn hơn FinFET. Nhưng GAAFET không phải là giải pháp vĩnh viễn. Thực tế là việc thu nhỏ transistor ngày càng khó khăn, và trong tương lai, khả năng mật độ SRAM không thay đổi vẫn là mối lo ngại lớn đối với các công ty thiết kế chip.
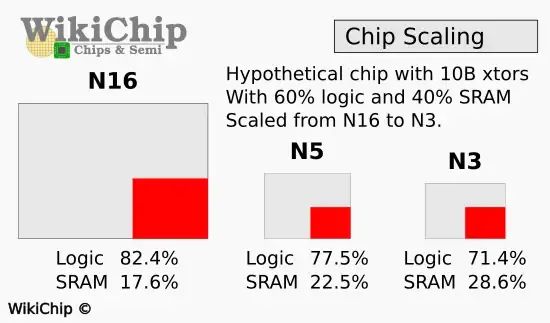
Giả sử một thiết kế chip với 10 tỷ transistor dựa trên 3 tiến trình N6, N5 và N3. Có thể nhận thấy rằng phần SRAM chiếm tỷ lệ ngày càng cao qua mỗi tiến trình
Dù TSMC không phải là công ty duy nhất có thể sản xuất chip bán dẫn, nhưng với việc Intel và Samsung vẫn đang theo đuổi công ty Đài Loan, tình hình này tạo ra một viễn cảnh khá u ám cho ngành công nghệ. Điều này có nghĩa là để tăng số nhân xử lý (mạch logic) trên các chip tương lai, các công ty thiết kế chip phải tính toán xem liệu có cần phải tăng kích thước die chip (để duy trì dung lượng cache/nhân) hoặc giảm dung lượng cache/nhân (để giữ kích thước chip không bị phình to). Đây là một bài toán khá đau đầu!
Đó cũng là lý do tại sao dù chip lớn nhất thế giới WSE-3 của Cerebras có đến 4000 tỷ transistor N5, số nhân và SRAM của nó cũng không tăng nhiều so với phiên bản WSE-2 trước đó với 2600 tỷ transistor N7 (900,000 vs. 850,000 nhân và 44 GB vs. 40 GB SRAM), vì phần lớn transistor bổ sung chủ yếu được dùng để mở rộng SRAM.
Kích thước của bộ nhớ cache đang trở thành vấn đề đau đầu đối với nhiều công ty sản xuất chip, trong đó có AMD
Phân chia tài nguyên để đạt hiệu quả tối ưu
Với vấn đề thu nhỏ SRAM như đã đề cập, các kỹ sư trong ngành bán dẫn đang tìm kiếm những giải pháp mới để cải thiện tình hình. Một trong những hướng đi đó là thiết kế nhiều die (MCM hoặc chiplet). Thực tế, phương pháp này không hề mới mẻ, vì những con chip như POWER7 của IBM, PlayStation 2 của Sony, hay Haswell của Intel đã sử dụng các die nhớ ngoài die CPU. Tuy nhiên, điểm khác biệt là các chip này không sử dụng SRAM mà là DRAM (hoặc eDRAM).
Mặc dù vậy, điều cần lưu ý ở đây là không phải để nói rằng AMD cũng sẽ làm giống như các công ty trên, mà ý tưởng cơ bản là SRAM có thể không nhất thiết phải nằm chung với die CPU.

AMD 3D V-Cache "thế hệ đầu" với die X3D được đặt trên die CCD
Như đã đề cập, mạch SRAM và mạch logic đang dần tách rời nhau. Sự không tương thích trong việc thu nhỏ kích thước dẫn đến SRAM ngày càng chiếm nhiều diện tích hơn. Nếu xu hướng này tiếp tục, sẽ có một thời điểm mà phần lớn không gian trong chip chỉ còn lại SRAM. Điều này có nghĩa là hiệu năng của các con chip sau này sẽ chỉ tăng trưởng chậm, vì các công ty không thể tiếp tục nhồi nhét thêm nhiều nhân xử lý khi diện tích silicon đã bị hạn chế.
Vậy thì SRAM sẽ phải "ra đi". Tuy nhiên, không phải là hoàn toàn (vì SRAM không thể hoàn toàn tách khỏi mạch logic). Một phần của SRAM sẽ không nằm cùng với die CPU nữa.
Từ đó, một hướng đi mới đã xuất hiện: SRAM có thể được sản xuất trên tiến trình cũ hơn nếu việc chuyển sang tiến trình bán dẫn mới không mang lại hiệu quả tốt (đặc biệt là với SRAM). Các tiến trình cũ thường có hiệu suất cao hơn và chi phí rẻ hơn so với các tiến trình mới. Do vậy, chi phí tổng thể sẽ thấp hơn so với việc nhồi nhét toàn bộ SRAM vào trong một die chip sử dụng tiến trình mới nhất.
Tuy nhiên, chỉ đơn giản "cắt khẩu" như vậy vẫn chưa đủ. Tại sao? Vì việc này quá dễ, các công ty khác cũng đã áp dụng với SRAM, chứ không chỉ dừng lại ở DRAM. Vậy thì tại sao?

eDRAM là một giải pháp hay, nhưng vẫn chưa đủ tốt về độ trễ khi được thiết kế theo kiểu chiplet 2D
Vấn đề ở đây chính là khoảng cách. Hãy nghĩ đến ví dụ về nhà máy đã đề cập trước đó. Nếu như DRAM giống như một kho chứa hàng ở cảng, cách xa hàng km, thì SRAM lại giống như đống pallet chỉ cách xưởng sản xuất vài mét hay vài chục mét. Nếu SRAM được đặt trên một die riêng biệt như eDRAM, thì lợi ích thu được sẽ giảm đi nhiều - vì mạch điện quá dài dẫn đến độ trễ quá cao. Nói cách khác, mặc dù có thể khác die, nhưng yêu cầu vẫn phải đảm bảo độ trễ cực kỳ thấp - 2 die mà phải hoạt động như một die! Vậy làm thế nào để đạt được điều này???
Tìm hiểu công nghệ AMD 3D V-Cache - Phần 3: Từ cấp 4 lên nhà cao tầng