
Z-score là gì?
Nếu z-score > 0, quan sát cao hơn trung bình.
Nếu z-score < 0, giá trị thấp hơn trung bình.
Nếu z-score = 0, dữ liệu đúng bằng trung bình.
Nhờ được chuẩn hóa theo độ lệch chuẩn, z-score loại bỏ hoàn toàn ảnh hưởng của đơn vị đo, giúp việc so sánh dữ liệu từ những nguồn khác nhau trở nên dễ dàng. Ví dụ, người học có thể so sánh điểm toán và điểm văn của một học sinh bằng z-score, thay vì chỉ nhìn vào điểm số thô vốn có thang đo khác nhau.
Tìm hiểu thêm:
Margin of Error là gì?
Standard Deviation là gì?
Tại sao z-score lại quan trọng trong phân tích dữ liệu?
Không chỉ dừng lại ở việc so sánh, chỉ số z-score còn giúp phát hiện những quan sát bất thường trong dữ liệu. Trong thống kê, một giá trị có |z| lớn, chẳng hạn lớn hơn 3, thường được coi là ngoại lệ (outlier). Điều này cực kỳ quan trọng trong phân tích vì các ngoại lệ có thể báo hiệu sai sót đo lường, hoặc ngược lại, cho thấy một hiện tượng đặc biệt cần chú ý. Ngoài ra, z-score còn gắn liền với việc ước lượng xác suất trong phân phối chuẩn. Các nhà nghiên cứu thường dùng nó để đánh giá mức độ tin cậy, rủi ro hay khả năng xảy ra của một kết quả, từ đó hỗ trợ ra quyết định khoa học và khách quan hơn.
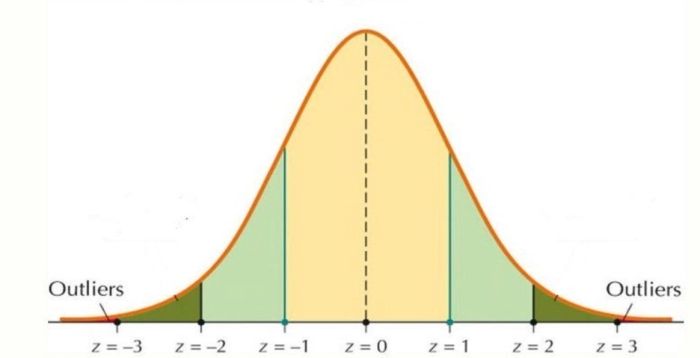
Mối liên hệ giữa z-score và phân phối chuẩn
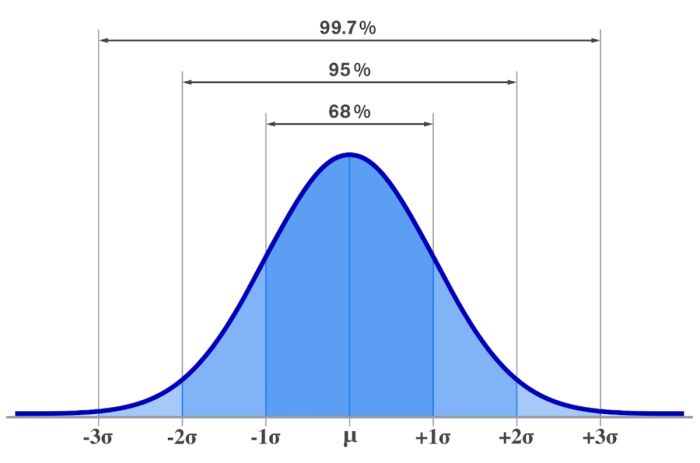
Điều này mang lại lợi ích lớn: ta có thể sử dụng bảng z hoặc phần mềm thống kê để nhanh chóng tìm xác suất một giá trị xuất hiện. Ngoài ra, z-score gắn liền với quy tắc 68–95–99.7:
Khoảng 68% dữ liệu sẽ nằm trong ±1 độ lệch chuẩn quanh trung bình.
Khoảng 95% dữ liệu nằm trong ±2 độ lệch chuẩn.
Khoảng 99.7% dữ liệu nằm trong ±3 độ lệch chuẩn.
Nhờ quy tắc này, z-score trở thành công cụ trực quan để dự đoán, diễn giải và đánh giá dữ liệu, giúp người học hiểu rõ hơn về phân phối xác suất và sự biến động của thông tin trong thực tế.
Công thức tính Z-score
Công thức chung
Z-score được tính bằng công thức cơ bản sau:
z=x−μ𝜎
trong đó:
x: là giá trị dữ liệu cụ thể cần đánh giá.
μ (mu): trung bình của toàn bộ tập hợp hoặc quần thể.
σ (sigma): độ lệch chuẩn, thể hiện mức độ phân tán của dữ liệu quanh trung bình.
Đây là công thức chuẩn hóa trực tiếp và được sử dụng rộng rãi nhất trong thống kê. Nhờ công thức này, mọi giá trị trong tập dữ liệu – dù khác nhau về đơn vị đo (cm, kg, điểm số, doanh thu…) – đều có thể được quy đổi về cùng một thang đo chuẩn. Kết quả là người học có thể dễ dàng so sánh các giá trị, kể cả khi xuất phát từ những nguồn dữ liệu hoàn toàn khác nhau.
Vai trò của từng thành phần
x chính là điểm dữ liệu muốn phân tích. Nó có thể là điểm thi của một học sinh trong một kỳ kiểm tra, chiều cao của một người so với nhóm dân số, hoặc doanh thu một ngày của cửa hàng so với doanh thu trung bình.
μ đóng vai trò “mốc chuẩn” để đo xem giá trị x lệch bao nhiêu so với mức trung bình. Không có μ, ta sẽ không biết liệu dữ liệu đang cao hay thấp hơn mặt bằng chung.
σ cho biết dữ liệu phân tán rộng hay hẹp quanh trung bình. Khi σ lớn, dữ liệu trải rộng và dao động nhiều; khi σ nhỏ, dữ liệu tập trung sát quanh trung bình. Nhờ có σ, khoảng cách giữa x và μ được quy đổi thành số “lần độ lệch chuẩn” – đó chính là bản chất của z-score.
Các trường hợp của giá trị z-score
Z > 0: dữ liệu cao hơn trung bình, nằm về phía bên phải của đồ thị phân phối. Ví dụ, nếu z = +2, nghĩa là giá trị này cao hơn trung bình đúng 2 độ lệch chuẩn, thường nằm trong nhóm nổi bật.
Z < 0: dữ liệu thấp hơn trung bình, nằm bên trái của phân phối. Ví dụ z = -1.5 cho thấy dữ liệu thấp hơn trung bình 1.5 độ lệch chuẩn, tức nằm ở phía dưới trung bình đáng kể.
Z = 0: dữ liệu đúng bằng trung bình, tức hoàn toàn không lệch sang bên nào cả. Đây là vị trí “chuẩn” trên phân phối chuẩn.
Nhờ cách diễn giải này, z-score không chỉ cho biết dữ liệu cao hay thấp, mà còn định lượng rõ ràng “cao hơn bao nhiêu” hoặc “thấp hơn bao nhiêu” so với trung bình.
Ảnh hưởng của giá trị z-score
Việc tính z-score mang lại nhiều lợi ích quan trọng:
So sánh dữ liệu: vì đã chuẩn hóa về cùng thang đo, người học có thể so sánh trực tiếp giữa nhiều tập dữ liệu khác nhau. Ví dụ, so sánh điểm Toán (thang 10) và điểm SAT (thang 1600) bằng cách đưa về z-score.
Phát hiện ngoại lệ (outliers): những điểm dữ liệu có |z| quá lớn, thường lớn hơn 3, được coi là ngoại lệ vì nằm rất xa trung bình. Đây là thông tin cực kỳ quan trọng trong nghiên cứu và phân tích dữ liệu.
Tính xác suất trong phân phối chuẩn: thông qua bảng Z (Z-table), người học có thể nhanh chóng ước lượng xác suất một giá trị xuất hiện, từ đó phục vụ kiểm định giả thuyết hoặc ra quyết định dựa trên độ tin cậy thống kê.
Ứng dụng đa lĩnh vực: z-score được sử dụng rộng rãi trong nhiều ngành, từ khoa học xã hội, kinh tế, tài chính, giáo dục cho đến khoa học dữ liệu và trí tuệ nhân tạo. Ví dụ, nhà phân tích tài chính dùng z-score để đánh giá rủi ro cổ phiếu, còn nhà nghiên cứu giáo dục dùng để so sánh thành tích học tập của học sinh giữa các kỳ thi khác nhau.
Hướng dẫn chi tiết cách tính z-score
Giá trị trung bình là nền tảng để so sánh và chuẩn hóa dữ liệu. Để tính giá trị trung bình, người học cộng tất cả các giá trị trong tập dữ liệu rồi chia cho số lượng phần tử. Ví dụ, với dãy số 5, 6, 7, 8, 9 thì trung bình bằng (5 + 6 + 7 + 8 + 9) / 5 = 7.
Bước 2: Tìm độ lệch chuẩn (σ).
Độ lệch chuẩn cho biết dữ liệu tập trung gần hay phân tán xa so với trung bình. Trước hết, lấy từng giá trị trừ đi trung bình, bình phương hiệu số này, cộng tất cả lại, chia cho số lượng phần tử, rồi lấy căn bậc hai. Độ lệch chuẩn được tính như sau:
σ=Σ(x−μ)2n
Nếu σ nhỏ, dữ liệu phân bố sát với trung bình; nếu σ lớn, dữ liệu trải rộng và có nhiều biến động hơn.
Bước 3: Áp dụng công thức và tính toán.
Sau khi đã có μ và σ, người học có thể dễ dàng tính được z-score dựa vào công thức:
z=x−μ𝜎
Ứng dụng của z-score trong bài thi SAT Math
Chiến lược giải bài tập z-score trong SAT:
Bước 1: Quan sát dạng biểu đồ. Xác định xem đề cho biểu đồ cột, biểu đồ chấm hay biểu đồ hộp. Kiểm tra kỹ xem các biểu đồ có cùng thang đo trên trục giá trị hay không, vì chỉ khi cùng thang đo mới có thể so sánh độ lệch chuẩn một cách chính xác.
Bước 2: Nhận diện mức độ tập trung và phân tán của dữ liệu. Nếu biểu đồ có các giá trị tập trung nhiều ở khu vực trung tâm (biểu đồ cao và hẹp ở giữa) thì dữ liệu ít dao động, nghĩa là độ lệch chuẩn nhỏ. Ngược lại, nếu các giá trị trải rộng, xuất hiện nhiều ở hai đầu hoặc phân bố phẳng hơn, thì dữ liệu dao động mạnh hơn và có độ lệch chuẩn lớn.
Bước 3: Đưa ra kết luận theo yêu cầu của đề. So sánh mức độ phân tán của các tập dữ liệu và kết luận xem tập nào có độ lệch chuẩn lớn hơn hoặc nhỏ hơn.
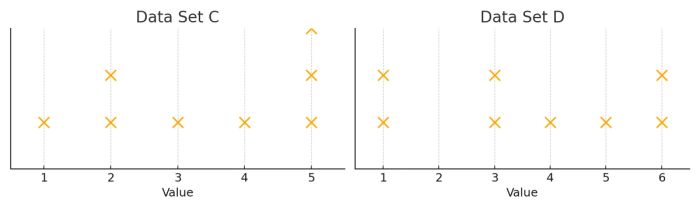
Bài tập thực hành
I. The median of data set C is equal to the median of data set D.II. The standard deviation of data set C is equal to the standard deviation of data set D.
A) I onlyB) II onlyC) I and IID) Neither I nor II
Bài 2: Which of the following statements is true based on the histograms?
A) The standard deviation of Class A’s scores is greater than that of Class B’s.B) The standard deviation of Class A’s scores is less than that of Class B’s.C) The two classes have approximately the same standard deviation.D) It is not possible to determine which class has a larger standard deviation.
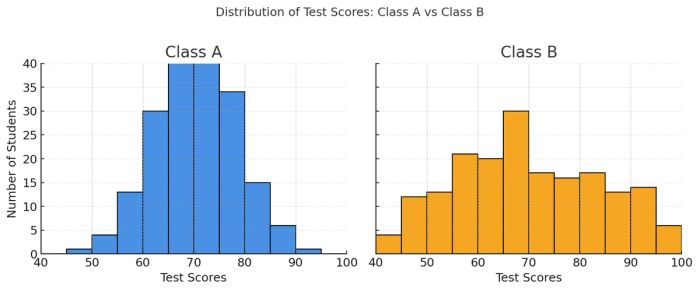
Giải đáp
Câu 1: A
Câu 2: B